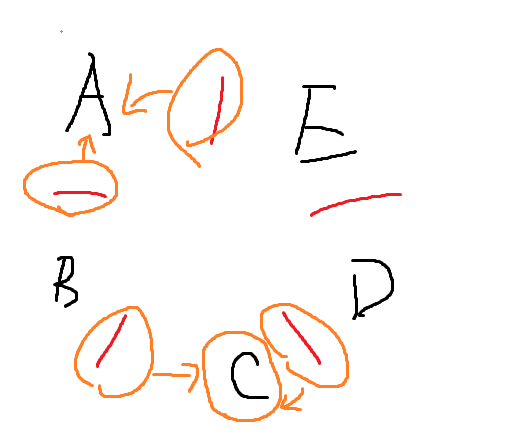操作系统实验 实验一、进程调度试验 [目的要求] 用高级语言编写和调试一个进程调度程序,以加深对进程的概念及进程调度算法的理解.
[准备知识] 一、基本概念 1、进程的概念;
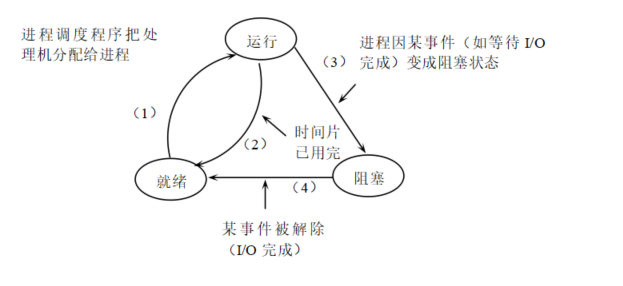
二、进程调度 1、进程的状态
[试验内容] 设计一个有 N个进程共行的进程调度程序。
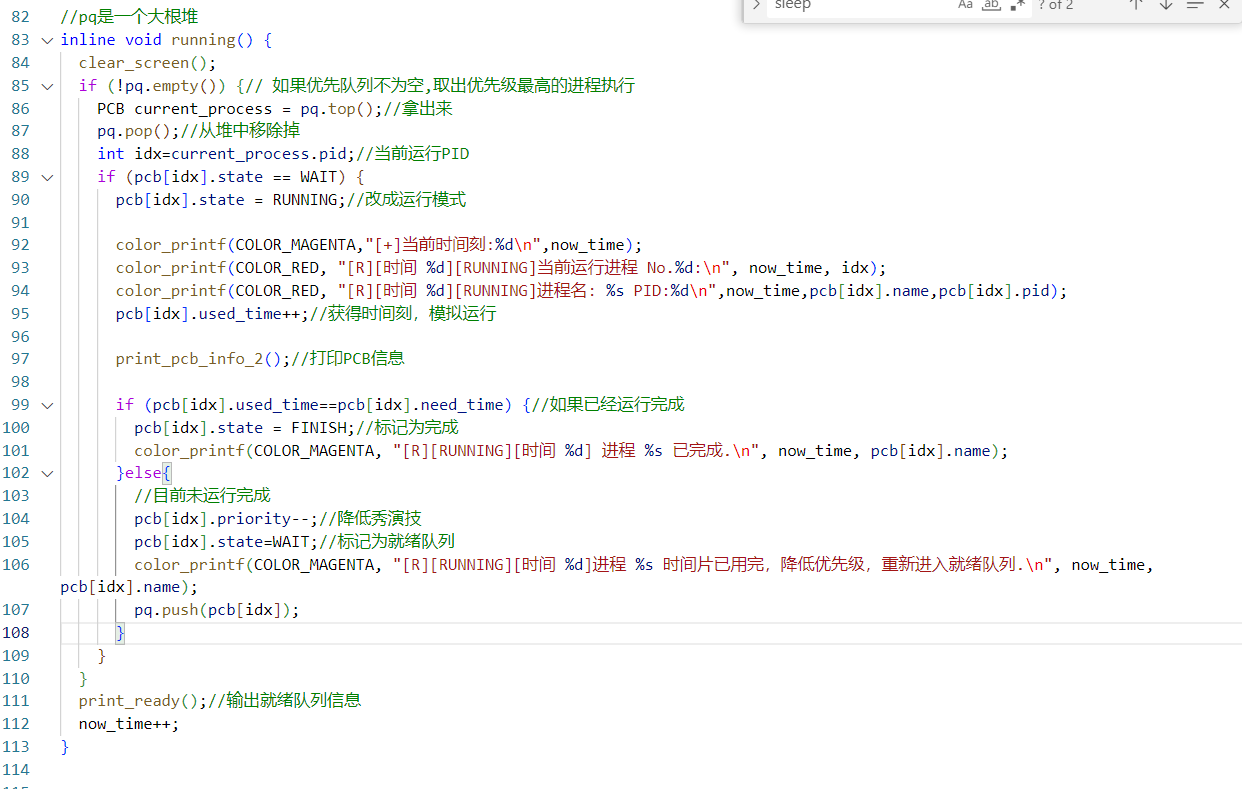
[实验过程] 题目中核心说的是:“最高优先数优先的调度算法”。也就是最高优先级的先运行,那么实现过程其实可以直接用数据结构:大根堆 来进行实现:
具体的:每次从队列中拿出一个PCB中运行,然后就可以焊东西了(bushi
将每个PCB的节点加入到大根堆中即可。
这里的pcb数组实际上可有可无。因为后面过程使用的pq进行维护,但再代码的一开始写的时候,为了方便调试还是存留了一些,方便一些运行完成的进程进行展示。
这里有小细节:新建进程的时候亦时间++,作为处理的时间。
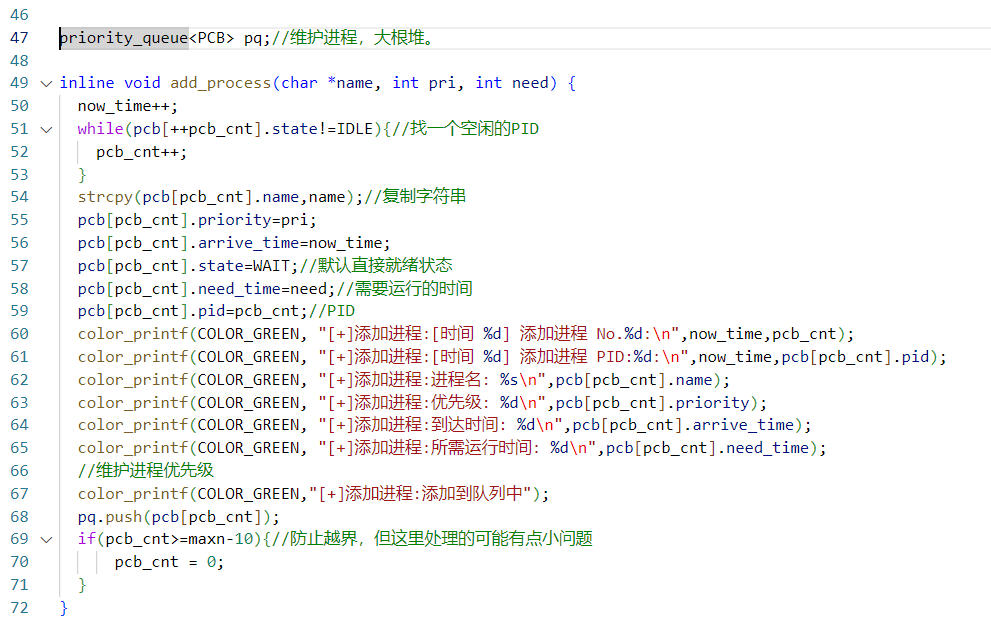
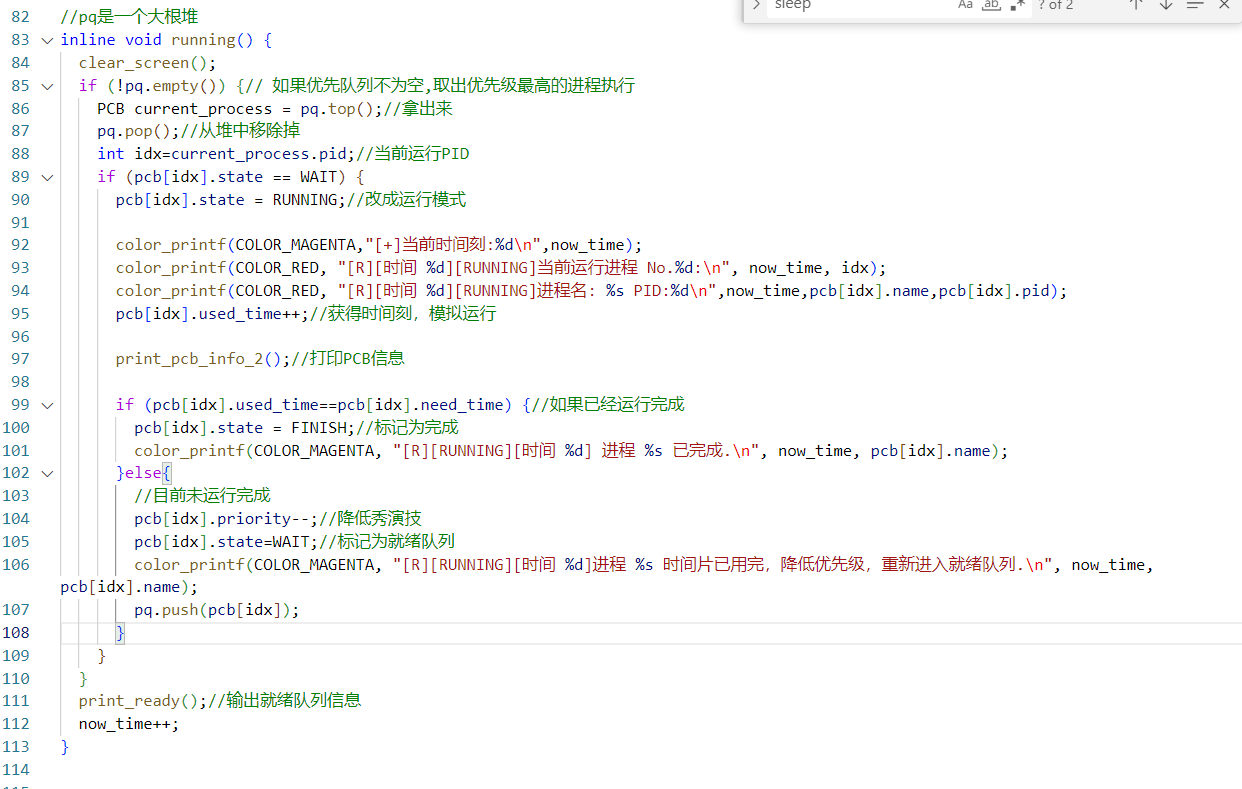
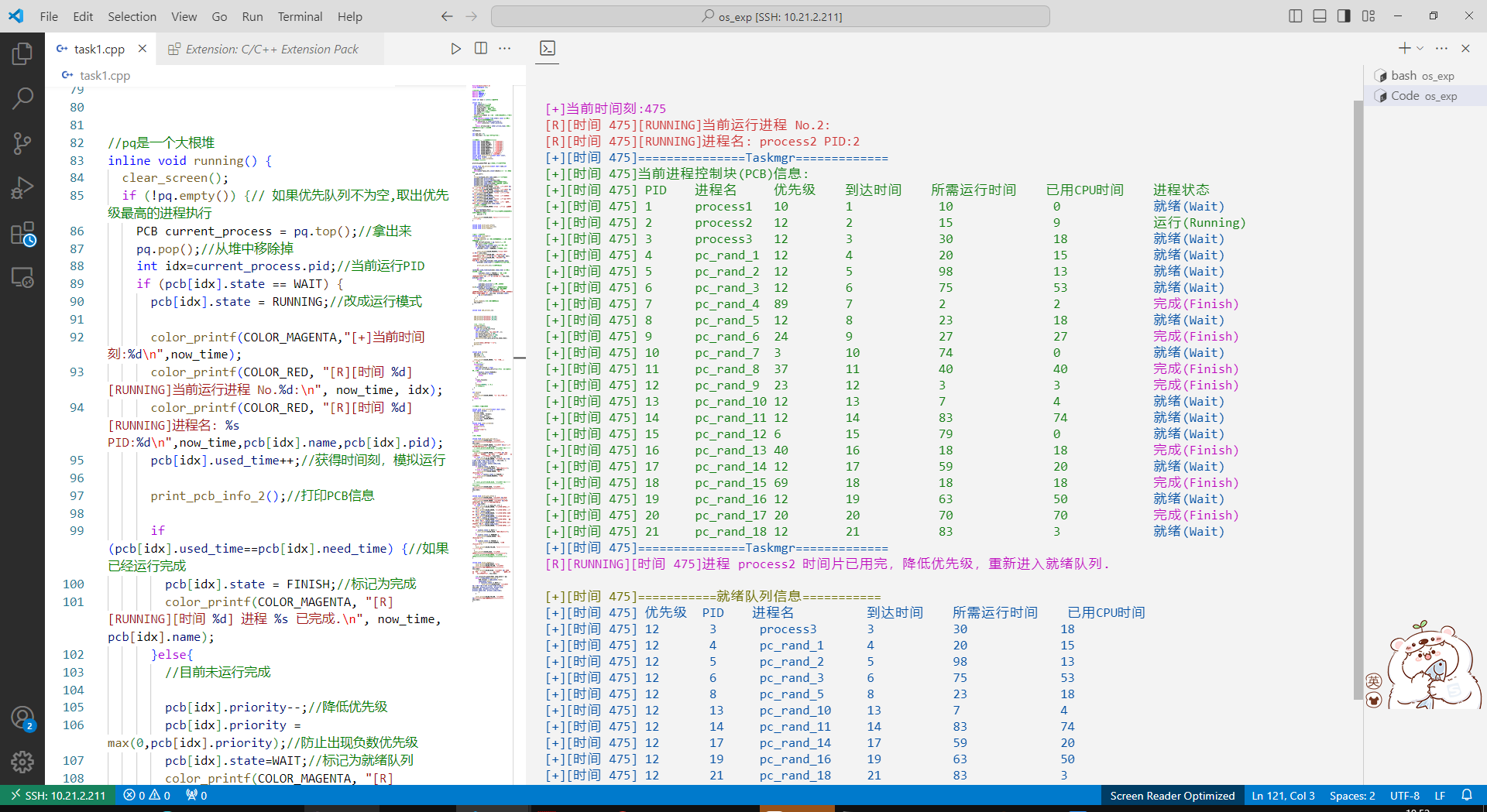
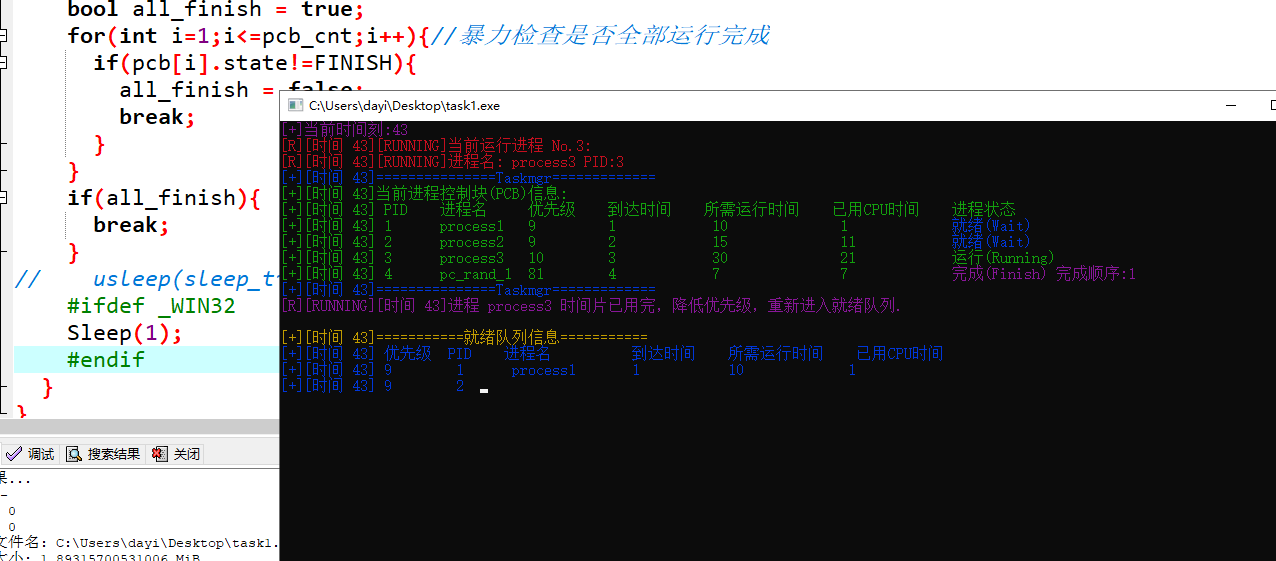
实际的代码大致如下图:
每次从pq(就绪队列),取出一个优先级(和到达顺序)最高的,然后进行分配CPU时间片,进入运行状态,运行完判断一下是否已经执行完(时间片达到需要的时间片)
如果执行完成:标记为FINISH
如果没有,再添加到大根堆里即可。
PCB定义 其实就是题目描述的定义,没太有什么特殊来讲的必要,重载下小于来进行排序。
添加进程 找一个PID,然后赋值到结构体上,用结构体数组实际上是为了维护。完全可以去掉。
运行 具体的已经前面说啦
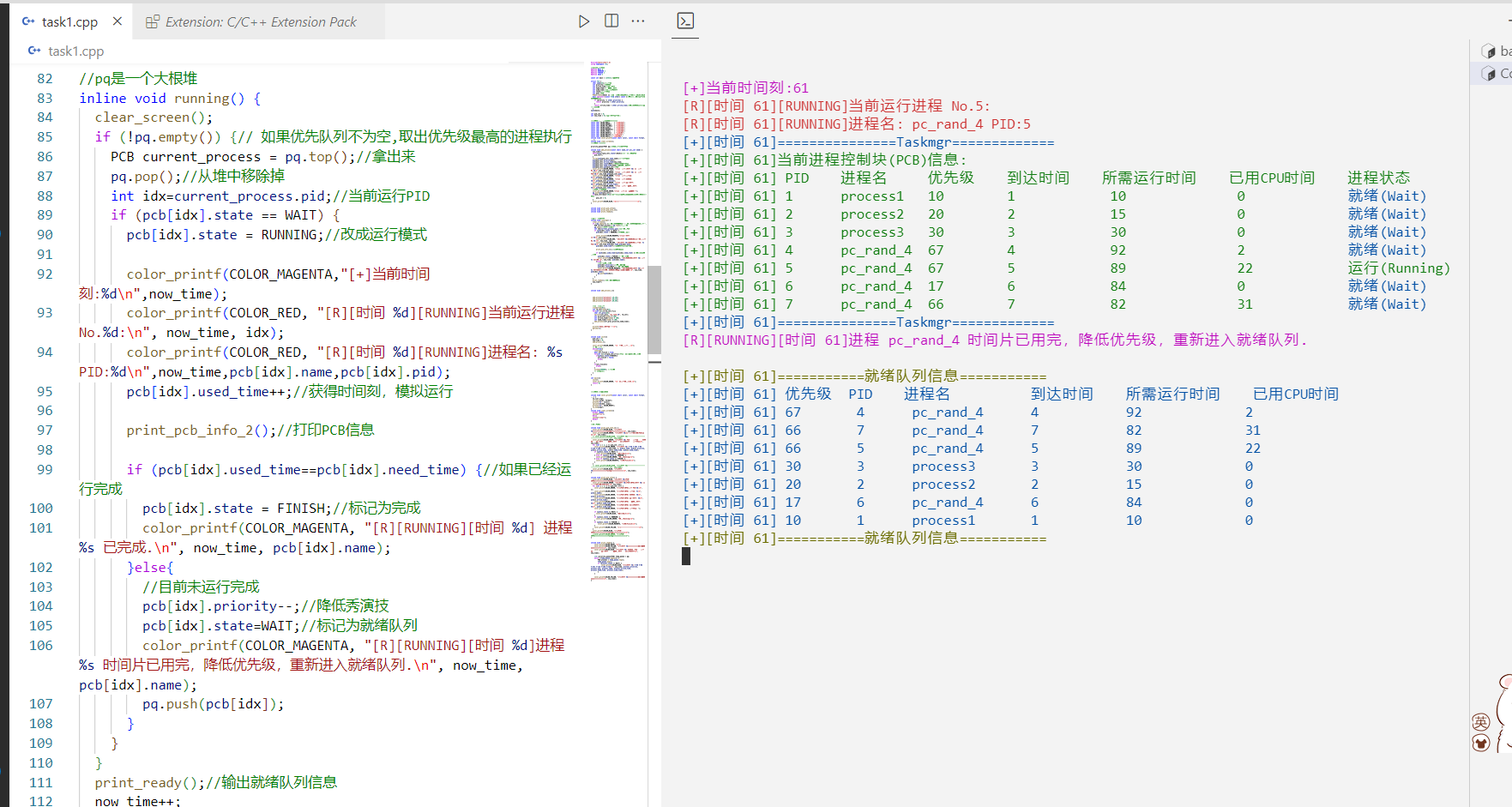
每次从pq取出优先级最高的进程,将其状态改为RUNNING并模拟执行一个时间片,更新其占用CPU时间。
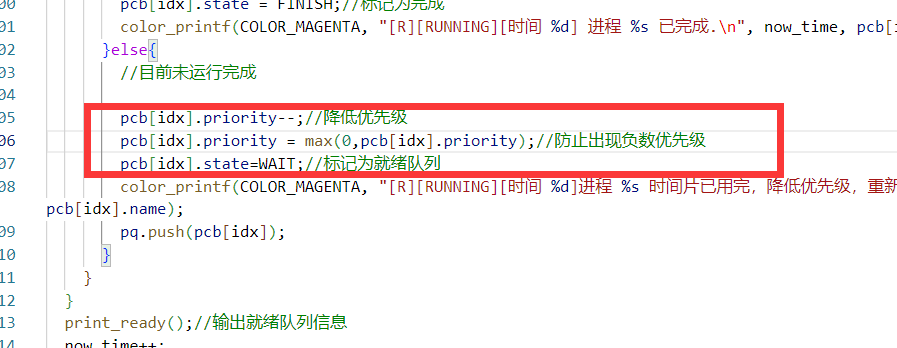
如果进程执行完毕,就标记为FINISH;否则将其优先级减1,状态改回WAIT,重新加入pq。这个过程不断重复,直到所有进程都完成。
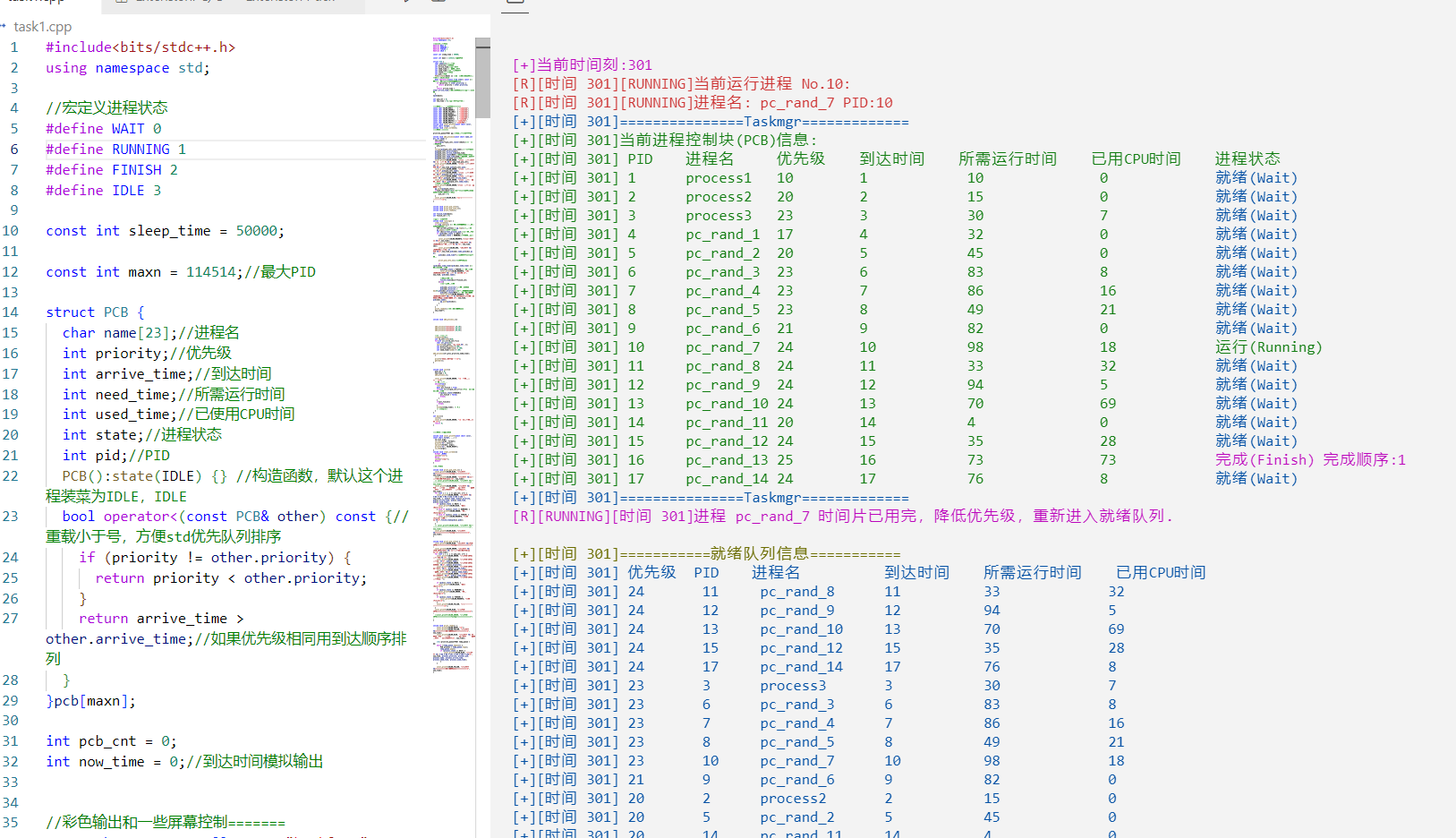
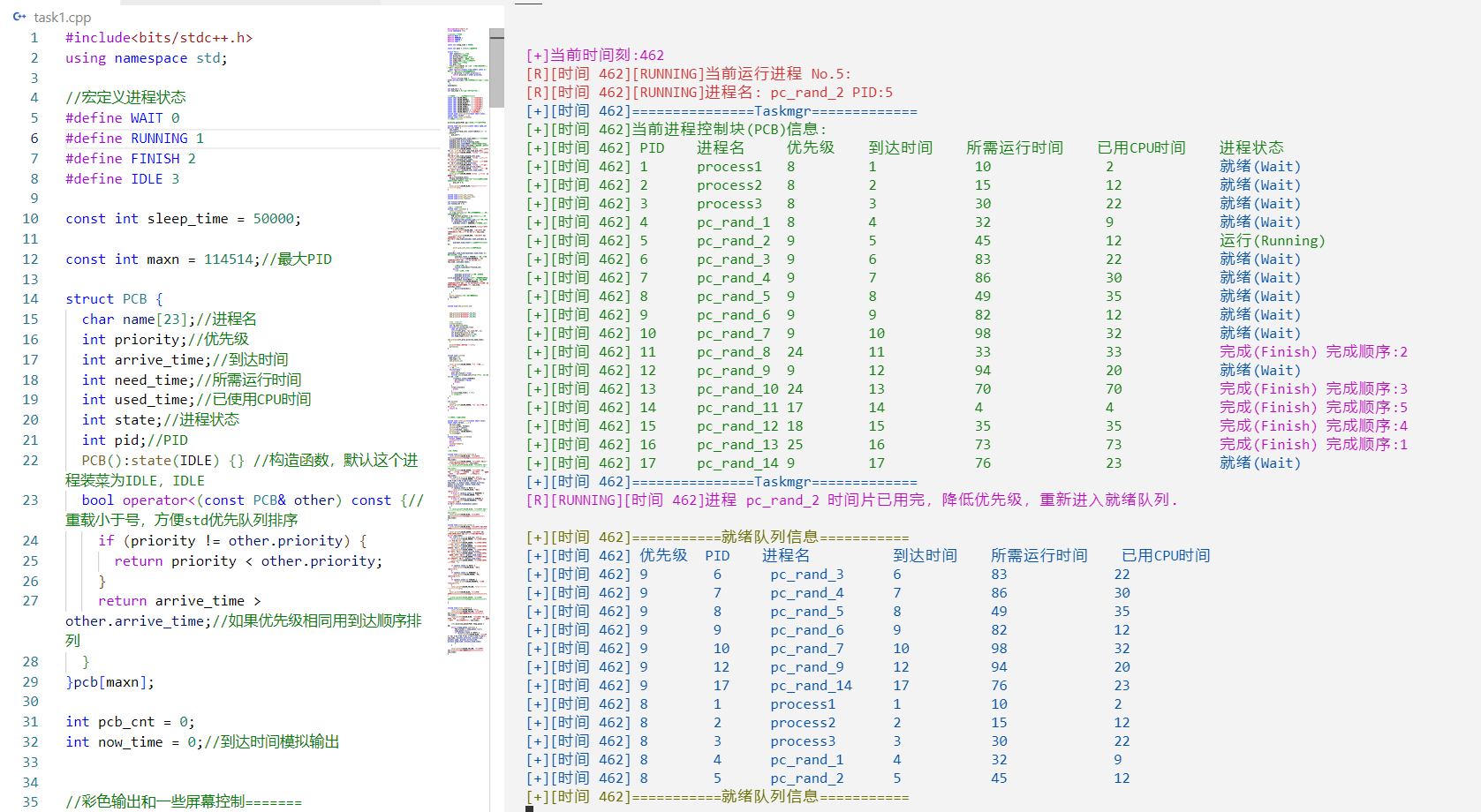
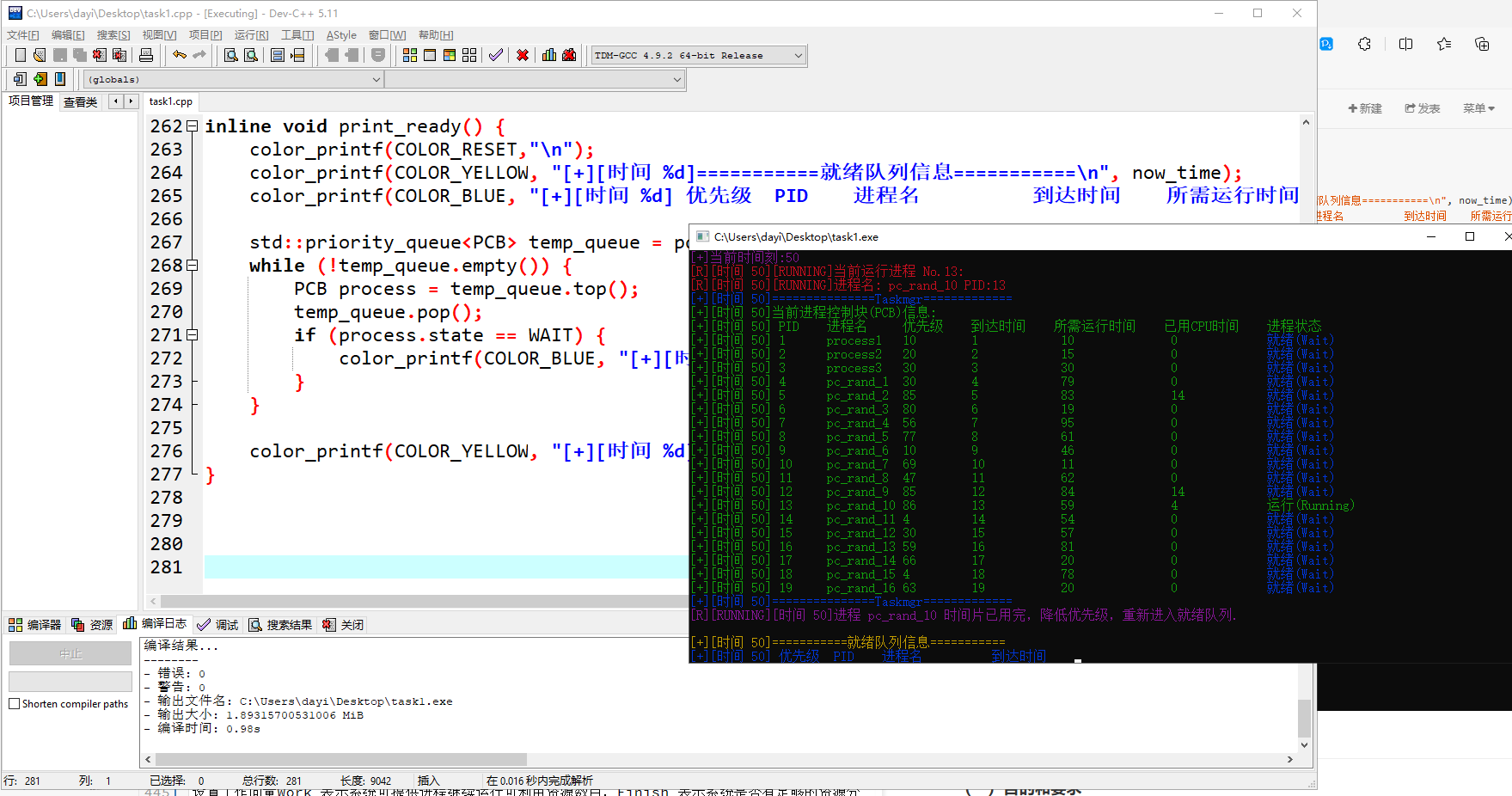
运行过程:
最后两个调度
然后就可以啦
但是会出现优先级为负数的情况,这里修改一下即可。
再试一下: ovo
oao
优先级一样会根据到达时间来执行
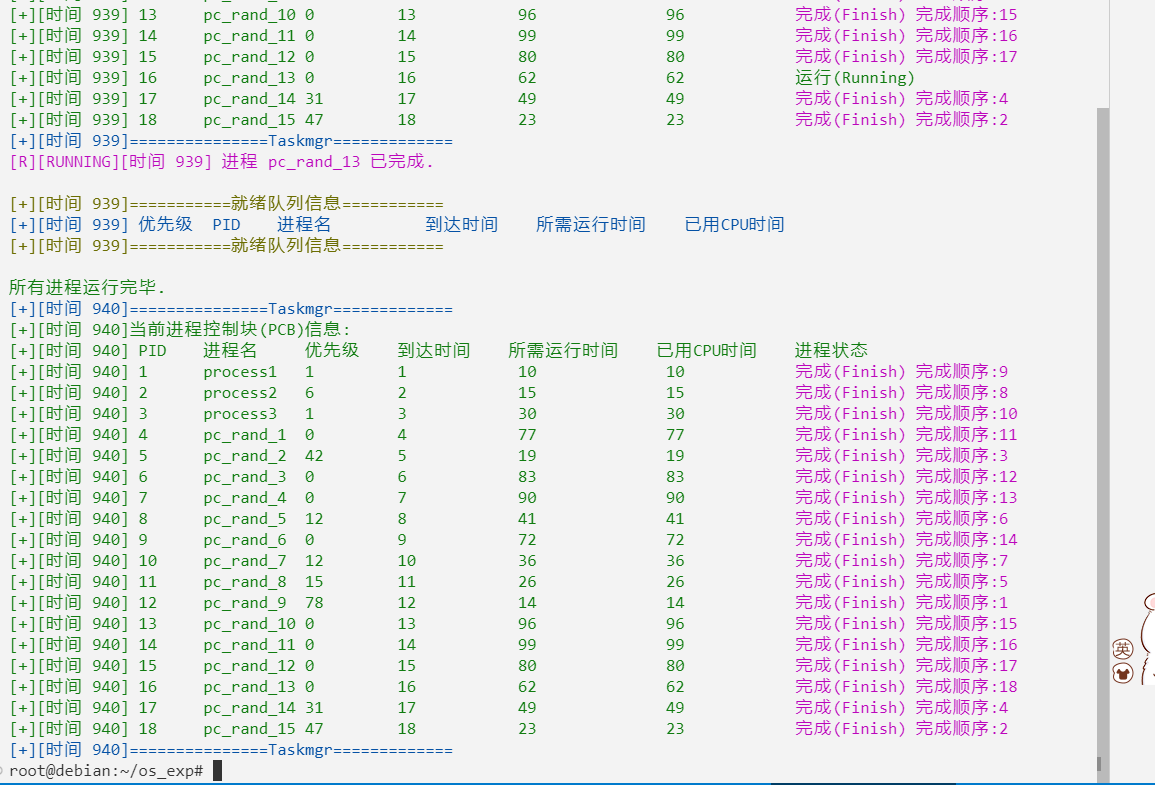
这样就完事啦:
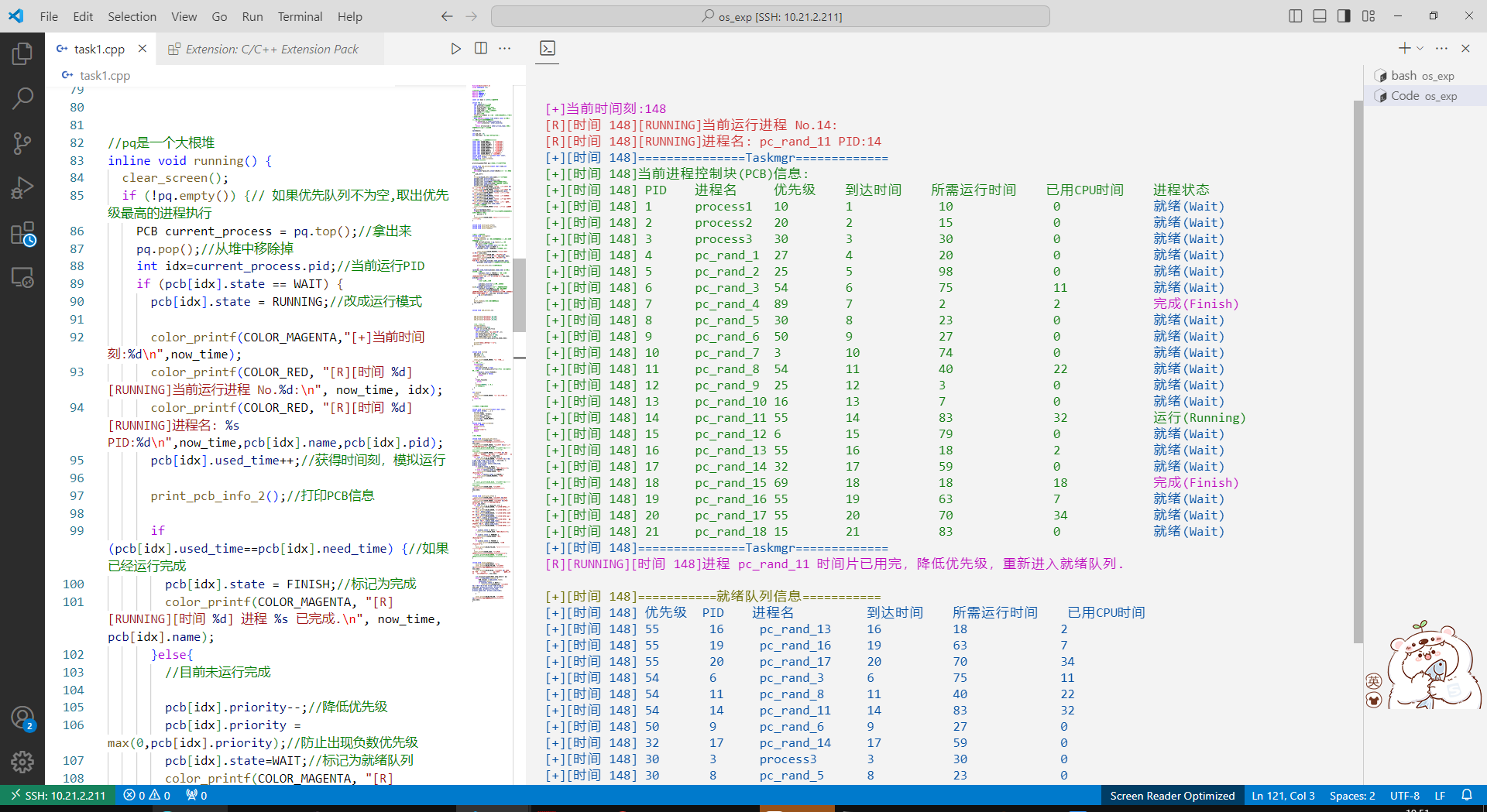
加了一个完成顺序:
完成任务后再打印一下PCB;
代码: 该文件在linux g++
1 2 3 4 5 root@debian:~/os_exp g++ (Debian 10.2.1-6) 10.2.1 20210110 Copyright (C) 2020 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
10.2.1下通过编译并正常运行无段错误。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 #include <bits/stdc++.h> using namespace std;#define WAIT 0 #define RUNNING 1 #define FINISH 2 #define IDLE 3 const int sleep_time = 50000 ; const int maxn = 114514 ;struct PCB { char name[23 ]; int priority; int arrive_time; int need_time; int used_time; int state; int pid; PCB ():state (IDLE) {} bool operator <(const PCB& other) const { if (priority != other.priority) { return priority < other.priority; } return arrive_time > other.arrive_time; } }pcb[maxn]; int pcb_cnt = 0 ;int now_time = 0 ;const char COLOR_RED[] = "\x1b[31m" ;const char COLOR_GREEN[] = "\x1b[32m" ;const char COLOR_YELLOW[] = "\x1b[33m" ;const char COLOR_BLUE[] = "\x1b[34m" ;const char COLOR_MAGENTA[] = "\x1b[35m" ;const char COLOR_CYAN[] = "\x1b[36m" ;const char COLOR_RESET[] = "\x1b[0m" ;const char COLOR_WHITE[] = "\x1b[37m" ;const char COLOR_GRAY[] = "\x1b[90m" ;inline void color_printf (const char * color, const char * format, ...) inline void clear_screen () priority_queue<PCB> pq; inline void add_process (const char * name,int pri,int need) now_time++; while (pcb[++pcb_cnt].state!=IDLE){ pcb_cnt++; } strcpy (pcb[pcb_cnt].name,name); pcb[pcb_cnt].priority=pri; pcb[pcb_cnt].arrive_time=now_time; pcb[pcb_cnt].state=WAIT; pcb[pcb_cnt].need_time=need; pcb[pcb_cnt].pid=pcb_cnt; color_printf (COLOR_GREEN, "[+]添加进程:[时间 %d] 添加进程 No.%d\n" ,now_time,pcb_cnt); color_printf (COLOR_GREEN, "[+]添加进程:[时间 %d] 添加进程 PID:%d\n" ,now_time,pcb[pcb_cnt].pid); color_printf (COLOR_GREEN, "[+]添加进程:进程名: %s\n" ,pcb[pcb_cnt].name); color_printf (COLOR_GREEN, "[+]添加进程:优先级: %d\n" ,pcb[pcb_cnt].priority); color_printf (COLOR_GREEN, "[+]添加进程:到达时间: %d\n" ,pcb[pcb_cnt].arrive_time); color_printf (COLOR_GREEN, "[+]添加进程:所需运行时间: %d\n" ,pcb[pcb_cnt].need_time); color_printf (COLOR_GREEN,"[+]添加进程:添加到队列中" ); pq.push (pcb[pcb_cnt]); if (pcb_cnt>=maxn-10 ){ pcb_cnt = 0 ; } color_printf (COLOR_BLUE,"\n[-]----------------------\n" ); } inline void print_pcb_info () inline void print_pcb_info_2 () inline void print_ready () int finish_time[maxn];int finish_cnt = 0 ;inline void running () clear_screen (); if (!pq.empty ()) { PCB current_process = pq.top (); pq.pop (); int idx=current_process.pid; if (pcb[idx].state == WAIT) { pcb[idx].state = RUNNING; color_printf (COLOR_MAGENTA,"[+]当前时间刻:%d\n" ,now_time); color_printf (COLOR_RED, "[R][时间 %d][RUNNING]当前运行进程 No.%d:\n" , now_time, idx); color_printf (COLOR_RED, "[R][时间 %d][RUNNING]进程名: %s PID:%d\n" ,now_time,pcb[idx].name,pcb[idx].pid); pcb[idx].used_time++; print_pcb_info_2 (); if (pcb[idx].used_time==pcb[idx].need_time) { pcb[idx].state = FINISH; color_printf (COLOR_MAGENTA, "[R][RUNNING][时间 %d] 进程 %s 已完成.\n" , now_time, pcb[idx].name); finish_time[idx]=++finish_cnt; }else { pcb[idx].priority--; pcb[idx].priority = max (0 ,pcb[idx].priority); pcb[idx].state=WAIT; color_printf (COLOR_MAGENTA, "[R][RUNNING][时间 %d]进程 %s 时间片已用完,降低优先级,重新进入就绪队列.\n" , now_time, pcb[idx].name); pq.push (pcb[idx]); } } } print_ready (); now_time++; } inline void add_process_ () add_process ("process1" ,10 ,10 ); add_process ("process2" ,20 ,15 ); add_process ("process3" ,30 ,30 ); srand (time (0 )); int rd_int=rand ()%20 ; for (int i=1 ;i<=rd_int;++i){ char str_proc[23 ]; sprintf (str_proc, "pc_rand_%d" , i); int priority=rand () % 100 ; int arrive_time=rand () % 100 ; int need_time=rand () % 100 ; add_process (str_proc,priority,need_time); } printf ("输入任意字符继续\n" ); getchar (); } #ifdef _WIN32 #include <windows.h> #endif inline void init () pcb_cnt = 0 ; now_time = 0 ; add_process_ (); color_printf (COLOR_GREEN, "\n开始运行进程...\n" ); while (true ){ running (); bool all_finish = true ; for (int i=1 ;i<=pcb_cnt;i++){ if (pcb[i].state!=FINISH){ all_finish = false ; break ; } } if (all_finish){ break ; } #ifdef _WIN32 Sleep (5 ); #else usleep (sleep_time); #endif } } int main () init (); color_printf (COLOR_GREEN, "\n所有进程运行完毕.\n" ); print_pcb_info_2 (); return 0 ; } inline void color_printf (const char * color, const char * format, ...) va_list args; va_start (args, format); printf ("%s" , color); vprintf (format, args); printf ("%s" , COLOR_RESET); va_end (args); } inline void clear_screen () #ifdef _WIN32 system ("cls" ); #else system ("clear" ); #endif } inline void print_pcb_info_2 () color_printf (COLOR_BLUE, "[+][时间 %d]===============Taskmgr=============\n" , now_time); color_printf (COLOR_GREEN, "[+][时间 %d]当前进程控制块(PCB)信息:\n" , now_time); color_printf (COLOR_GREEN, "[+][时间 %d] PID 进程名 优先级 到达时间 所需运行时间 已用CPU时间 进程状态\n" , now_time); for (int i = 1 ; i <= pcb_cnt; i++) { color_printf (COLOR_GREEN, "[+][时间 %d] %-6d %-10s %-9d %-12d %-15d %-13d " , now_time, i, pcb[i].name, pcb[i].priority, pcb[i].arrive_time, pcb[i].need_time, pcb[i].used_time); if (pcb[i].state == WAIT) { color_printf (COLOR_BLUE, "就绪(Wait)\n" ); } else if (pcb[i].state == RUNNING) { color_printf (COLOR_GREEN, "运行(Running)\n" ); } else if (pcb[i].state == FINISH) { color_printf (COLOR_MAGENTA, "完成(Finish) 完成顺序:%d\n" ,finish_time[pcb[i].pid]); } } color_printf (COLOR_BLUE, "[+][时间 %d]===============Taskmgr=============\n" , now_time); } inline void print_pcb_info () color_printf (COLOR_BLUE, "[I][时间 %d][PCB-INFO]===============Taskmgr=============\n" ); color_printf (COLOR_GREEN, "[I][时间 %d][PCB-INFO][时间 %d] 当前进程控制块(PCB)信息:\n" ,now_time); for (int i = 1 ; i <= pcb_cnt; i++) { color_printf (COLOR_GREEN, "[-][PCB-INFO]进程 PID:%d:\n" , i); color_printf (COLOR_GREEN, "[-][PCB-INFO] 进程名: %s\n" , pcb[i].name); color_printf (COLOR_GREEN, "[-][PCB-INFO] 优先级: %d\n" , pcb[i].priority); color_printf (COLOR_GREEN, "[-][PCB-INFO] 到达时间: %d\n" , pcb[i].arrive_time); color_printf (COLOR_GREEN, "[-][PCB-INFO] 所需运行时间: %d\n" , pcb[i].need_time); color_printf (COLOR_GREEN, "[-][PCB-INFO] 已用CPU时间: %d\n" , pcb[i].used_time); color_printf (COLOR_GREEN, "[-][PCB-INFO] 进程状态: " ); if (pcb[i].state == WAIT) { color_printf (COLOR_BLUE, "就绪(Wait)\n" ); } if (pcb[i].state == RUNNING) { color_printf (COLOR_GREEN, "运行(Running)\n" ); } if (pcb[i].state == FINISH) { color_printf (COLOR_MAGENTA, "完成(Finish)\n" ); } color_printf (COLOR_YELLOW, "[-]---------------------\n" ); } color_printf (COLOR_BLUE, "[-][PCB-INFO]===============Taskmgr=============\n" ); } inline void print_ready () color_printf (COLOR_RESET,"\n" ); color_printf (COLOR_YELLOW, "[+][时间 %d]===========就绪队列信息===========\n" , now_time); color_printf (COLOR_BLUE, "[+][时间 %d] 优先级 PID 进程名 到达时间 所需运行时间 已用CPU时间\n" , now_time); std::priority_queue<PCB> temp_queue = pq; while (!temp_queue.empty ()) { PCB process = temp_queue.top (); temp_queue.pop (); if (process.state == WAIT) { color_printf (COLOR_BLUE, "[+][时间 %d] %-8d %-6d %-14s %-11d %-14d %-12d\n" , now_time, process.priority, process.pid, process.name, process.arrive_time, process.need_time, process.used_time); } } color_printf (COLOR_YELLOW, "[+][时间 %d]===========就绪队列信息===========\n" , now_time); }
win也可以运行
就是稍微有点怪,不知道为啥stdlib的sleep编译不通过了,用了条件编译windows.h。
动图:
实验二、银行家算法 (一)目的和要求 银行家算法是由Dijkstra设计的最具有代表性的避免死锁的算法。本实验要求用高级语言编写一个银行家的模拟算法。通过本实验可以对预防死锁和银行家算法有更深刻的认识。
(二)实验内容 1、设置数据结构
(三)实验环境 1、pc
用滴g++
原理: 部分参考:
https://www.cnblogs.com/wkfvawl/p/11929508.html
注意:
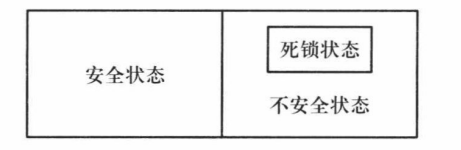
银行家算法的实质就是要设法保证系统动态分配资源后不进入不安全状态,以避免可能产生的死锁。
题目大致这样:
有几个小问
原理-实现(无证明正确性): 首先需要这三个量:
Allocation 已经分配的资源
Max 最大需求矩阵
Need 需求矩阵 = Allocation - Max
每个进程$P_i$需要一定的资源。
算法流程:
对于本题提供的代码例子,系统初始状态如下表所示:
进程
Max
Allocation
Need
Available
P1
7 5 3
0 1 0
7 4 3
3 3 2
P2
3 2 2
2 0 0
1 2 2
P3
9 0 2
3 0 2
6 0 0
P4
2 2 2
2 1 1
0 1 1
P5
4 3 3
0 0 2
4 3 1
矩阵中每个坐标可以这样看:
进程
最大需求
已分配资源
需求资源
是否完成
P0
7 5 3
0 1 0
7 4 3
0
P1
3 2 2
2 0 0
1 2 2
0
P2
9 0 2
3 0 2
6 0 0
0
P3
2 2 2
2 1 1
0 1 1
0
P4
4 3 3
0 0 2
4 3 1
0
可用资源: 3 3 2
Available向量表示的是系统当前可用资源数,随着进程的请求和释放会动态变化。
然后当请求来的时候,尝试满足需要,如果可以满足需要则进行分配,然后判断系统的安全性。
具体的详细的内容可以参考王道考研死锁的避免。
这样直接写算法即可:
根据这个算法流程可以这样做:
分为三个矩阵:
Max N*M N为进程数,M为资源量
Allocation N*M
Need N*M的矩阵,表示需求矩阵
Available M的以为向量
Request 多个请求,一个向量表示一个请求(M维向量),每个进程都有多个请求。
over 相当于图论的vis,表示当前有没有弄完。
安全性算法:
设置两个向量:工作向量Work和完成向量Finish 都是M维
Work = Availabe
finish = 0
从进程集合中找到一个满足条件的进程:
finish[i] = 0
Need[i,j]<=Work[j] 也就是需求量小于等于当前还剩下的资源量
如果找到:
重复过程2,然后直到找不到任何一个符合条件的进程。
如果Finish = 1(全为1)则是安全状态,否则,则不安全。
原题 大概是这个:
课本PDF:https://github.com/luyumei/Operating-Systems/blob/main/
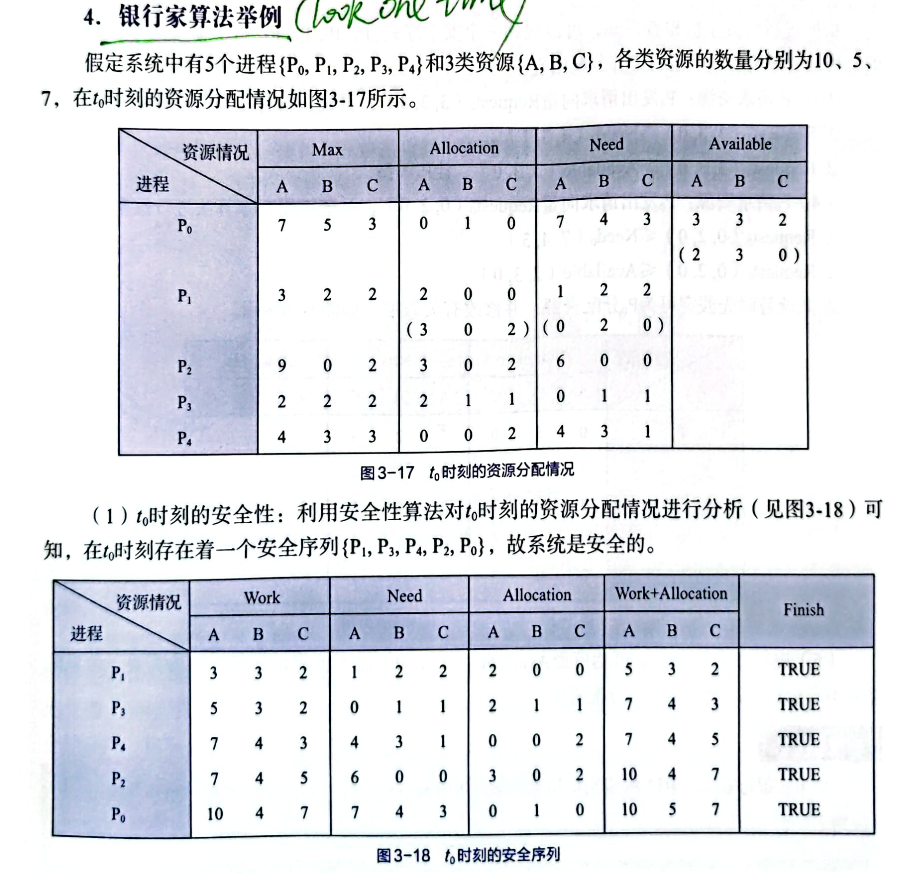
书本P101页例题:
1. T0时刻系统的安全性: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 #include <bits/stdc++.h> int Availiable[3 +1 ]={0 ,3 ,3 ,2 };int Max[5 +1 ][3 +1 ]={{0 ,0 ,0 ,0 },{0 ,7 ,5 ,3 },{0 ,3 ,2 ,2 },{0 ,9 ,0 ,2 },{0 ,2 ,2 ,2 },{0 ,4 ,3 ,3 }};int Allocation[5 +1 ][3 +1 ]={{0 ,0 ,0 ,0 },{0 ,0 ,1 ,0 },{0 ,2 ,0 ,0 },{0 ,3 ,0 ,2 },{0 ,2 ,1 ,1 },{0 ,0 ,0 ,2 }};int Need[5 +1 ][3 +1 ]={{0 ,0 ,0 ,0 },{0 ,7 ,4 ,3 },{0 ,1 ,2 ,2 },{0 ,6 ,0 ,0 },{0 ,0 ,1 ,1 },{0 ,4 ,3 ,1 }};int over[5 +1 ]={0 ,0 ,0 ,0 ,0 ,0 };const int maxn = 5 + 1 ;const int max_res = 3 +1 ;int res_cnt = 3 ;int proc_cnt = 5 ;int work[max_res];inline int check_need (int i) for (int k=1 ;k<=res_cnt;++k){ if (Need[i][k]>work[k]){ printf ("[debug]检查%d是否可以获得资源:不可以\n" ,i); return 0 ; } } printf ("[debug]检查%d是否可以获得资源:可以\n" ,i); return 1 ; } inline int check_is_safe_t0 () for (int i=1 ;i<=res_cnt;++i)work[i]=Availiable[i]; for (int i=1 ;i<=proc_cnt;++i)over[i]=0 ; int cnt = 0 ; for (int i=1 ;i<=proc_cnt;++i){ int find=0 ; for (int j=1 ;j<=proc_cnt;++j){ if (!over[j]&&check_need (j)){ find=1 ; over[j] = ++cnt; std::cout<<"进程 P" <<j<<"已分配资源,并且执行完成,归还资源." <<"\n" ; std::cout<<"目前可用资源:" ; for (int k=1 ;k<=res_cnt;++k){ work[k]+=Allocation[j][k]; std::cout<<work[k]<<" " ; } std::cout<<"\n" ; break ; } } if (!find)return 0 ; } return cnt==proc_cnt; } inline void print_safe_seq () std::cout<<"安全序列为:" ; for (int i=1 ;i<=proc_cnt;++i){ for (int j=1 ;j<=proc_cnt;++j){ if (over[j]==i){ std::cout<<"P" <<j<<" " ; break ; } } } std::cout<<"\n" ; } int main () using namespace std; if (check_is_safe_t0 ()){ std::cout<<"结果:氨醛~\n" ; cout<<"安全序列为:" ; print_safe_seq (); }else { std::cout<<"结果:Not Safe\n" ; } }
输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 root@debian:~/os_exp [debug]检查1是否可以获得资源:不可以 [debug]检查2是否可以获得资源:可以 进程 P2已分配资源,并且执行完成,归还资源. 目前可用资源:5 3 2 [debug]检查1是否可以获得资源:不可以 [debug]检查3是否可以获得资源:不可以 [debug]检查4是否可以获得资源:可以 进程 P4已分配资源,并且执行完成,归还资源. 目前可用资源:7 4 3 [debug]检查1是否可以获得资源:可以 进程 P1已分配资源,并且执行完成,归还资源. 目前可用资源:7 5 3 [debug]检查3是否可以获得资源:可以 进程 P3已分配资源,并且执行完成,归还资源. 目前可用资源:10 5 5 [debug]检查5是否可以获得资源:可以 进程 P5已分配资源,并且执行完成,归还资源. 目前可用资源:10 5 7 结果:氨醛~ 安全序列为:安全序列为:P2 P4 P1 P3 P5
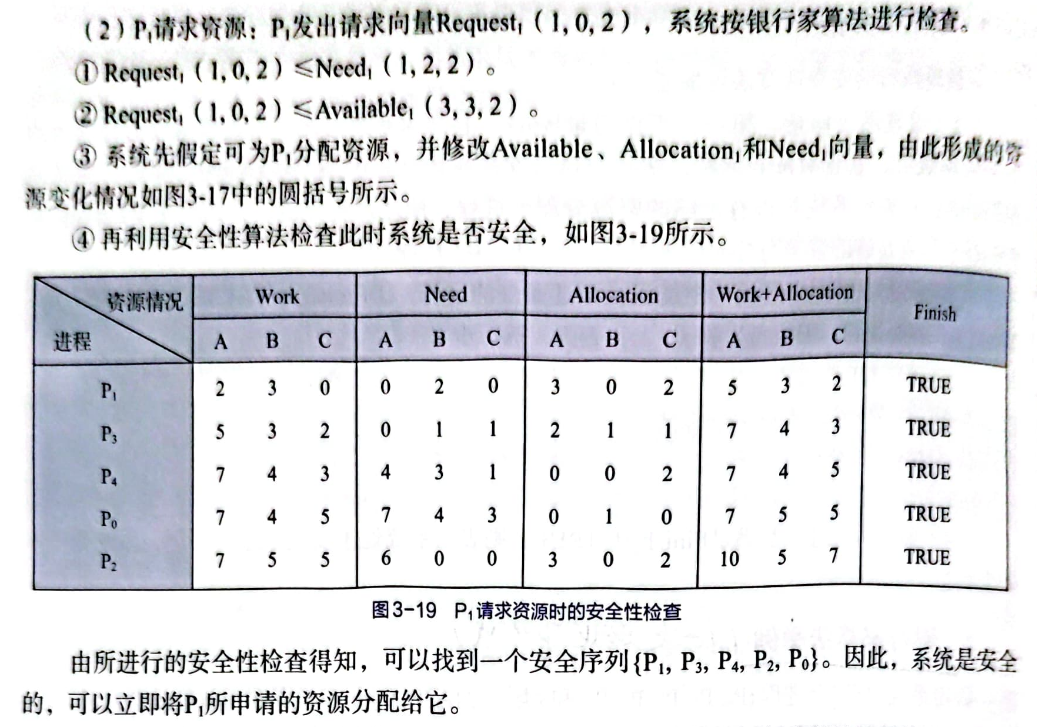
T2.P1请求资源:P1发出请求向量Request(1,0,2),系统按银行家算法进行检查
请求(1,0,2)
银行家算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 inline int bank (int proc_id, int req[]) for (int i=1 ;i<=res_cnt;++i){ if (req[i]>Need[proc_id][i]){ printf ("[dayi-debug-err]请求错误,%d进程请求:%d:%d最大需求矩阵为:%d:%d\n" ,proc_id,i,req[i],i,Need[proc_id][i]); return 0 ; } } for (int i=1 ;i<=res_cnt;++i){ if (req[i]>Availiable[i]){ printf ("[dayi-debug-err]请求错误,%d进程请求:%d:%d 目前可用:%d:%d ,需要等待\n" ,proc_id,i,req[i],i,Availiable[i]); return -1 ; } } for (int i=1 ;i<=res_cnt;i++){ Availiable[i]-=req[i]; Allocation[proc_id][i]+=req[i]; Need[proc_id][i]-=req[i]; } if (check_is_safe_t0 ()) { printf ("[info] 进程 P%d 请求资源成功\n" , proc_id); return 1 ; } for (int i=1 ;i<=res_cnt;i++){ Availiable[i]+=req[i]; Allocation[proc_id][i]-=req[i]; Need[proc_id][i]+=req[i]; } printf ("[info] 进程 P%d 请求资源导致系统不安全,请求失败\n" , proc_id); return -1 ; }
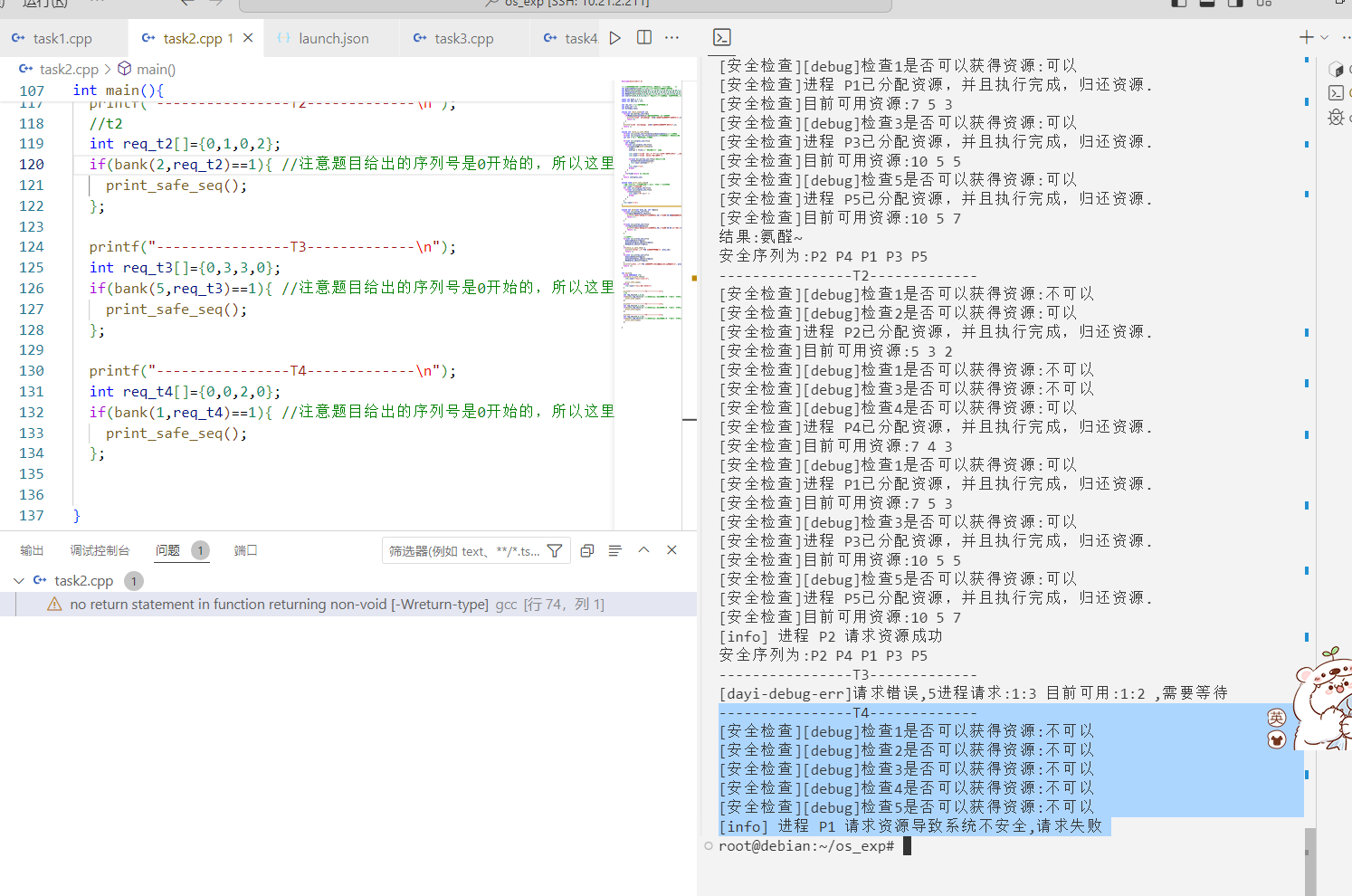
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 [安全检查][debug]检查1是否可以获得资源:不可以 [安全检查][debug]检查2是否可以获得资源:可以 [安全检查]进程 P2已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:5 3 2 [安全检查][debug]检查1是否可以获得资源:不可以 [安全检查][debug]检查3是否可以获得资源:不可以 [安全检查][debug]检查4是否可以获得资源:可以 [安全检查]进程 P4已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:7 4 3 [安全检查][debug]检查1是否可以获得资源:可以 [安全检查]进程 P1已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:7 5 3 [安全检查][debug]检查3是否可以获得资源:可以 [安全检查]进程 P3已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:10 5 5 [安全检查][debug]检查5是否可以获得资源:可以 [安全检查]进程 P5已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:10 5 7 结果:氨醛~ 安全序列为:P2 P4 P1 P3 P5 ----------------T2------------- [安全检查][debug]检查1是否可以获得资源:不可以 [安全检查][debug]检查2是否可以获得资源:可以 [安全检查]进程 P2已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:5 3 2 [安全检查][debug]检查1是否可以获得资源:不可以 [安全检查][debug]检查3是否可以获得资源:不可以 [安全检查][debug]检查4是否可以获得资源:可以 [安全检查]进程 P4已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:7 4 3 [安全检查][debug]检查1是否可以获得资源:可以 [安全检查]进程 P1已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:7 5 3 [安全检查][debug]检查3是否可以获得资源:可以 [安全检查]进程 P3已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:10 5 5 [安全检查][debug]检查5是否可以获得资源:可以 [安全检查]进程 P5已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:10 5 7 [info] 进程 P2 请求资源成功 安全序列为:P2 P4 P1 P3 P5
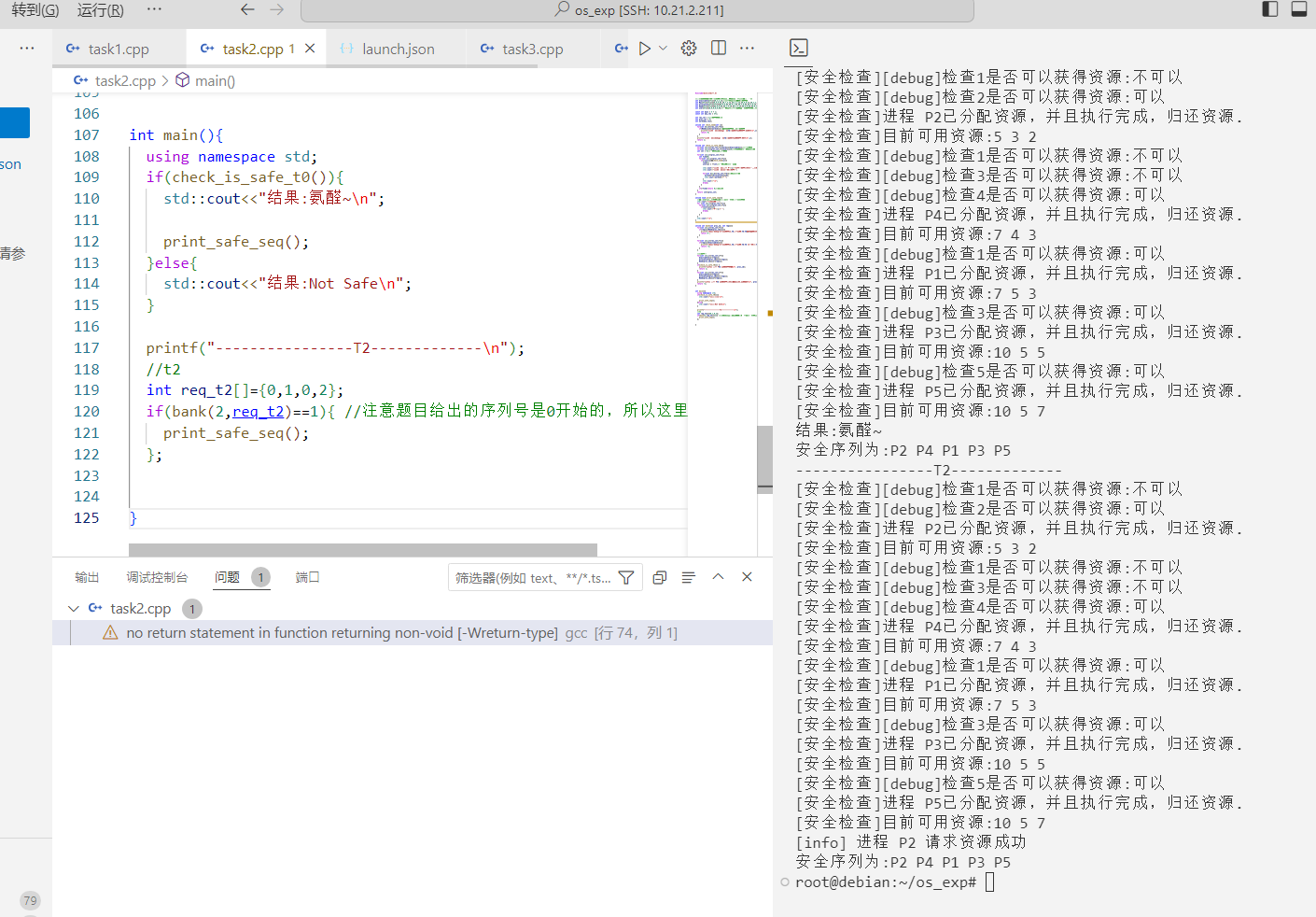
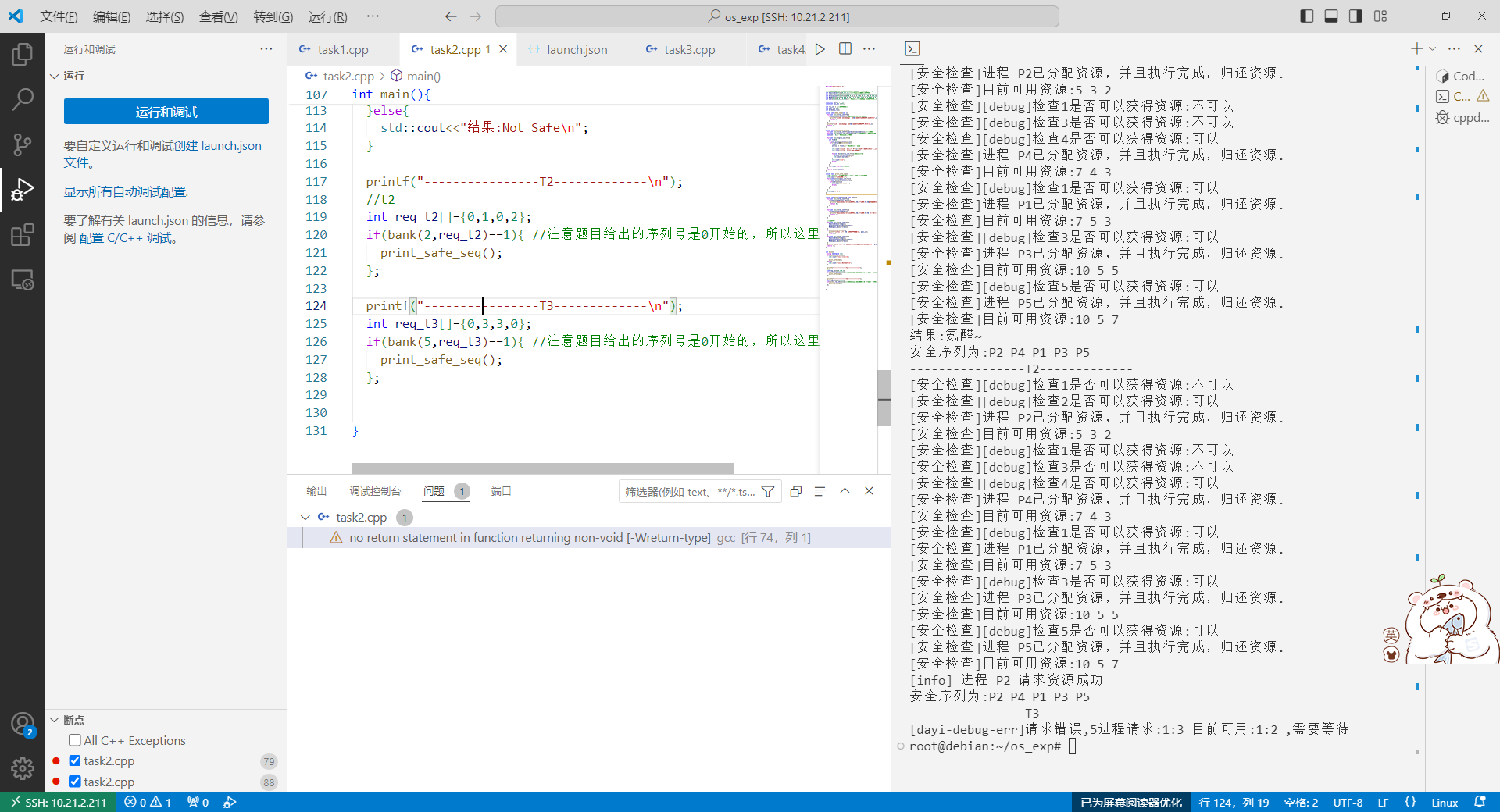
T3 发出请求向量Request(3,3,0),系统按银行家算法进行检查
P4请求资源(3,3,0);
1 2 3 4 5 printf ("----------------T3-------------\n" ); int req_t3[]={0 ,3 ,3 ,0 }; if (bank (5 ,req_t3)==1 ){ print_safe_seq (); };
运行结果:
1 2 3 ----------------T3------------- [dayi-debug-err]请求错误,5进程请求:1:3 目前可用:1:2 ,需要等待 root@debian:~/os_exp
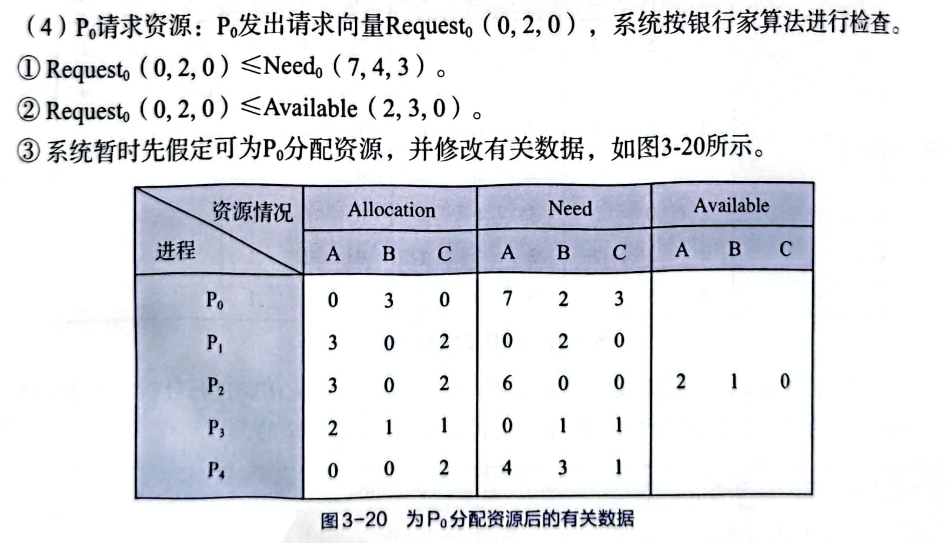
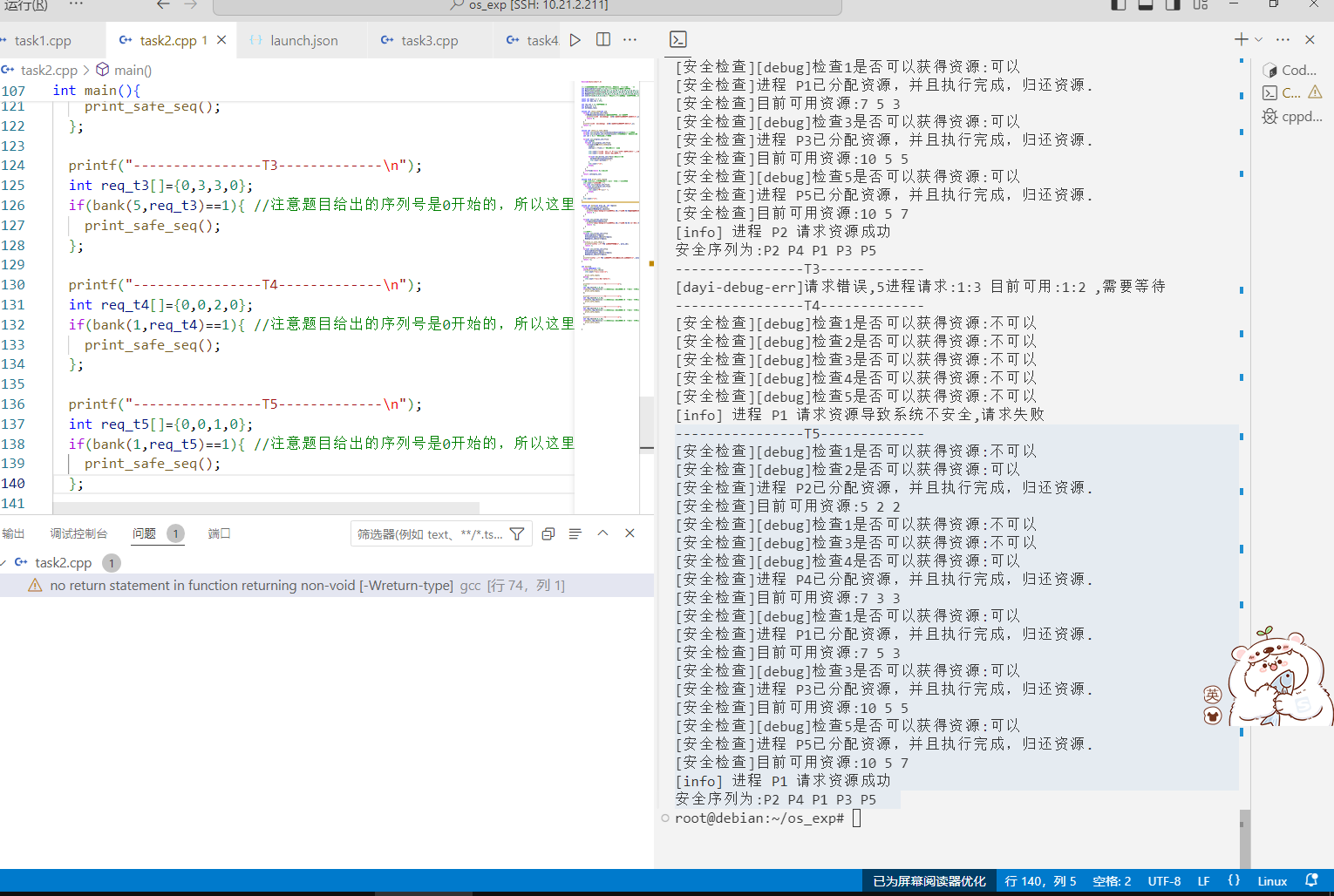
T4 发出请求向量Request(0,2,0),系统按银行家算法进行检查 P0 请求(0,2,0),进行检查
1 2 3 4 5 6 7 8 9 10 11 12 13 printf ("----------------T4-------------\n" ); int req_t4[]={0,0,2,0}; if (bank(1,req_t4)==1){ //注意题目给出的序列号是0开始的,所以这里的进程是5 print_safe_seq(); }; ----------------T4------------- [安全检查][debug]检查1是否可以获得资源:不可以 [安全检查][debug]检查2是否可以获得资源:不可以 [安全检查][debug]检查3是否可以获得资源:不可以 [安全检查][debug]检查4是否可以获得资源:不可以 [安全检查][debug]检查5是否可以获得资源:不可以 [info] 进程 P1 请求资源导致系统不安全,请求失败
T5
同理,因为上一问导致系统处于不安全状态,所以不分配资源。
思考:t0 (0,1,0)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 printf ("----------------T5-------------\n" ); int req_t5[]={0,0,1,0}; if (bank(1,req_t5)==1){ //注意题目给出的序列号是0开始的,所以这里的进程是5 print_safe_seq(); }; ----------------T5------------- [安全检查][debug]检查1是否可以获得资源:不可以 [安全检查][debug]检查2是否可以获得资源:可以 [安全检查]进程 P2已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:5 2 2 [安全检查][debug]检查1是否可以获得资源:不可以 [安全检查][debug]检查3是否可以获得资源:不可以 [安全检查][debug]检查4是否可以获得资源:可以 [安全检查]进程 P4已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:7 3 3 [安全检查][debug]检查1是否可以获得资源:可以 [安全检查]进程 P1已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:7 5 3 [安全检查][debug]检查3是否可以获得资源:可以 [安全检查]进程 P3已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:10 5 5 [安全检查][debug]检查5是否可以获得资源:可以 [安全检查]进程 P5已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:10 5 7 [info] 进程 P1 请求资源成功 安全序列为:P2 P4 P1 P3 P5
这样看是可以的。
原始代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 #include <bits/stdc++.h> int Availiable[3 +1 ]={0 ,3 ,3 ,2 };int Max[5 +1 ][3 +1 ]={{0 ,0 ,0 ,0 },{0 ,7 ,5 ,3 },{0 ,3 ,2 ,2 },{0 ,9 ,0 ,2 },{0 ,2 ,2 ,2 },{0 ,4 ,3 ,3 }};int Allocation[5 +1 ][3 +1 ]={{0 ,0 ,0 ,0 },{0 ,0 ,1 ,0 },{0 ,2 ,0 ,0 },{0 ,3 ,0 ,2 },{0 ,2 ,1 ,1 },{0 ,0 ,0 ,2 }};int Need[5 +1 ][3 +1 ]={{0 ,0 ,0 ,0 },{0 ,7 ,4 ,3 },{0 ,1 ,2 ,2 },{0 ,6 ,0 ,0 },{0 ,0 ,1 ,1 },{0 ,4 ,3 ,1 }};int over[5 +1 ]={0 ,0 ,0 ,0 ,0 ,0 };const int maxn = 5 + 1 ;const int max_res = 3 +1 ;int res_cnt = 3 ;int proc_cnt = 5 ;int work[max_res];inline int check_need (int i) for (int k=1 ;k<=res_cnt;++k){ if (Need[i][k]>work[k]){ printf ("[安全检查][debug]检查%d是否可以获得资源:不可以\n" ,i); return 0 ; } } printf ("[安全检查][debug]检查%d是否可以获得资源:可以\n" ,i); return 1 ; } inline int check_is_safe_t0 () for (int i=1 ;i<=res_cnt;++i)work[i]=Availiable[i]; for (int i=1 ;i<=proc_cnt;++i)over[i]=0 ; int cnt = 0 ; for (int i=1 ;i<=proc_cnt;++i){ int find=0 ; for (int j=1 ;j<=proc_cnt;++j){ if (!over[j]&&check_need (j)){ find=1 ; over[j] = ++cnt; std::cout<<"[安全检查]进程 P" <<j<<"已分配资源,并且执行完成,归还资源." <<"\n" ; std::cout<<"[安全检查]目前可用资源:" ; for (int k=1 ;k<=res_cnt;++k){ work[k]+=Allocation[j][k]; std::cout<<work[k]<<" " ; } std::cout<<"\n" ; break ; } } if (!find)return 0 ; } return cnt==proc_cnt; } inline void print_safe_seq () std::cout<<"安全序列为:" ; for (int i=1 ;i<=proc_cnt;++i){ for (int j=1 ;j<=proc_cnt;++j){ if (over[j]==i){ std::cout<<"P" <<j<<" " ; break ; } } } std::cout<<"\n" ; } inline int bank (int proc_id, int req[]) for (int i=1 ;i<=res_cnt;++i){ if (req[i]>Need[proc_id][i]){ printf ("[dayi-debug-err]请求错误,%d进程请求:%d:%d最大需求矩阵为:%d:%d\n" ,proc_id,i,req[i],i,Need[proc_id][i]); return 0 ; } } for (int i=1 ;i<=res_cnt;++i){ if (req[i]>Availiable[i]){ printf ("[dayi-debug-err]请求错误,%d进程请求:%d:%d 目前可用:%d:%d ,需要等待\n" ,proc_id,i,req[i],i,Availiable[i]); return -1 ; } } for (int i=1 ;i<=res_cnt;i++){ Availiable[i]-=req[i]; Allocation[proc_id][i]+=req[i]; Need[proc_id][i]-=req[i]; } if (check_is_safe_t0 ()) { printf ("[info] 进程 P%d 请求资源成功\n" , proc_id); return 1 ; } for (int i=1 ;i<=res_cnt;i++){ Availiable[i]+=req[i]; Allocation[proc_id][i]-=req[i]; Need[proc_id][i]+=req[i]; } printf ("[info] 进程 P%d 请求资源导致系统不安全,请求失败\n" , proc_id); return -1 ; } int main () using namespace std; if (check_is_safe_t0 ()){ std::cout<<"结果:氨醛~\n" ; print_safe_seq (); }else { std::cout<<"结果:Not Safe\n" ; } printf ("----------------T2-------------\n" ); int req_t2[]={0 ,1 ,0 ,2 }; if (bank (2 ,req_t2)==1 ){ print_safe_seq (); }; printf ("----------------T3-------------\n" ); int req_t3[]={0 ,3 ,3 ,0 }; if (bank (5 ,req_t3)==1 ){ print_safe_seq (); }; printf ("----------------T4-------------\n" ); int req_t4[]={0 ,0 ,2 ,0 }; if (bank (1 ,req_t4)==1 ){ print_safe_seq (); }; printf ("----------------T5-------------\n" ); int req_t5[]={0 ,0 ,1 ,0 }; if (bank (1 ,req_t5)==1 ){ print_safe_seq (); }; }
好看一点的代码
打印了需求矩阵
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 #include <bits/stdc++.h> int Availiable[3 +1 ]={0 ,3 ,3 ,2 };int Max[5 +1 ][3 +1 ]={{0 ,0 ,0 ,0 },{0 ,7 ,5 ,3 },{0 ,3 ,2 ,2 },{0 ,9 ,0 ,2 },{0 ,2 ,2 ,2 },{0 ,4 ,3 ,3 }};int Allocation[5 +1 ][3 +1 ]={{0 ,0 ,0 ,0 },{0 ,0 ,1 ,0 },{0 ,2 ,0 ,0 },{0 ,3 ,0 ,2 },{0 ,2 ,1 ,1 },{0 ,0 ,0 ,2 }};int Need[5 +1 ][3 +1 ]={{0 ,0 ,0 ,0 },{0 ,7 ,4 ,3 },{0 ,1 ,2 ,2 },{0 ,6 ,0 ,0 },{0 ,0 ,1 ,1 },{0 ,4 ,3 ,1 }};int over[5 +1 ]={0 ,0 ,0 ,0 ,0 ,0 };const int maxn = 5 + 1 ;const int max_res = 3 +1 ;int res_cnt = 3 ;int proc_cnt = 5 ;int work[max_res];inline void print_matrix (std::string name, int mat[][max_res], int n, int m) std::cout<<name<<"矩阵:\n" ; for (int i=1 ;i<=n;++i){ for (int j=1 ;j<=m;++j){ std::cout<<mat[i][j]<<" " ; } std::cout<<"\n" ; } std::cout<<"\n" ; } inline void print_vector (std::string name, int vec[], int n) std::cout<<name<<"向量:" ; for (int i=1 ;i<=n;++i){ std::cout<<vec[i]<<" " ; } std::cout<<"\n\n" ; } inline void print_sysstate () std::cout<<"当前系统状态:\n" ; print_vector ("可用资源" ,Availiable,res_cnt); print_matrix ("最大需求矩阵" ,Max,proc_cnt,res_cnt); print_matrix ("分配矩阵" ,Allocation,proc_cnt,res_cnt); print_matrix ("需求矩阵" ,Need,proc_cnt,res_cnt); } inline int check_need (int i) for (int k=1 ;k<=res_cnt;++k){ if (Need[i][k]>work[k]){ printf ("[安全检查][debug]检查P%d是否可以获得资源:不可以\n" ,i); return 0 ; } } printf ("[安全检查][debug]检查P%d是否可以获得资源:可以\n" ,i); return 1 ; } inline int check_is_safe_t0 () for (int i=1 ;i<=res_cnt;++i)work[i]=Availiable[i]; for (int i=1 ;i<=proc_cnt;++i)over[i]=0 ; int cnt = 0 ; for (int i=1 ;i<=proc_cnt;++i){ int find=0 ; for (int j=1 ;j<=proc_cnt;++j){ if (!over[j]&&check_need (j)){ find=1 ; over[j] = ++cnt; std::cout<<"[安全检查]进程P" <<j<<"已分配资源,并且执行完成,归还资源." <<"\n" ; std::cout<<"[安全检查]目前可用资源:" ; for (int k=1 ;k<=res_cnt;++k){ work[k]+=Allocation[j][k]; std::cout<<work[k]<<" " ; } std::cout<<"\n" ; break ; } } if (!find)return 0 ; } return cnt==proc_cnt; } inline void print_safe_seq () std::cout<<"安全序列为:" ; for (int i=1 ;i<=proc_cnt;++i){ for (int j=1 ;j<=proc_cnt;++j){ if (over[j]==i){ std::cout<<"P" <<j<<" " ; break ; } } } std::cout<<"\n" ; } inline int bank (int proc_id, int req[]) std::cout<<"进程P" <<proc_id<<"请求资源:" ; for (int i=1 ;i<=res_cnt;++i)std::cout<<req[i]<<" " ; std::cout<<"\n" ; for (int i=1 ;i<=res_cnt;++i){ if (req[i]>Need[proc_id][i]){ printf ("[err]请求错误,P%d进程请求资源数超过其最大需求量\n" ,proc_id); return 0 ; } } for (int i=1 ;i<=res_cnt;++i){ if (req[i]>Availiable[i]){ printf ("[info]P%d进程请求资源数超过当前可用资源,需等待\n" ,proc_id); return -1 ; } } for (int i=1 ;i<=res_cnt;i++){ Availiable[i]-=req[i]; Allocation[proc_id][i]+=req[i]; Need[proc_id][i]-=req[i]; } std::cout<<"尝试分配后系统状态:\n" ; print_sysstate (); if (check_is_safe_t0 ()) { printf ("[info]P%d进程请求资源后系统仍安全,请求成功\n" , proc_id); return 1 ; } for (int i=1 ;i<=res_cnt;i++){ Availiable[i]+=req[i]; Allocation[proc_id][i]-=req[i]; Need[proc_id][i]+=req[i]; } printf ("[info]P%d进程请求资源将导致系统不安全,请求失败\n" , proc_id); return -1 ; } int main () using namespace std; std::cout<<"初始时系统状态:\n" ; print_sysstate (); if (check_is_safe_t0 ()){ std::cout<<"系统初始状态安全\n" ; print_safe_seq (); }else { std::cout<<"系统初始状态不安全\n" ; return 0 ; } int choice=1 ; int cnt = 0 ; while (choice != 0 ) { printf ("----------------T%d----------------\n" ,++cnt); cout<<"请输入选项(0:退出 1:请求资源):" ; cin>>choice; if (choice==0 ) { break ; }else if (choice == 1 ) { int proc_id,req[max_res]; cout<<"请输入进程编号(从1开始): " ; cin>>proc_id; cout<<"请输入请求的资源量(共" <<res_cnt<<"种资源): " ; for (int i=1 ;i<=res_cnt;++i)cin>>req[i]; int result=bank (proc_id,req); if (result==1 ) { print_safe_seq (); } } else { cout<<"无效选项,请重新输入\n" ; } } }
输出结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 root@debian:~/os_exp 初始时系统状态: 当前系统状态: 可用资源向量:3 3 2 最大需求矩阵矩阵: 7 5 3 3 2 2 9 0 2 2 2 2 4 3 3 分配矩阵矩阵: 0 1 0 2 0 0 3 0 2 2 1 1 0 0 2 需求矩阵矩阵: 7 4 3 1 2 2 6 0 0 0 1 1 4 3 1 [安全检查][debug]检查P1是否可以获得资源:不可以 [安全检查][debug]检查P2是否可以获得资源:可以 [安全检查]进程P2已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:5 3 2 [安全检查][debug]检查P1是否可以获得资源:不可以 [安全检查][debug]检查P3是否可以获得资源:不可以 [安全检查][debug]检查P4是否可以获得资源:可以 [安全检查]进程P4已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:7 4 3 [安全检查][debug]检查P1是否可以获得资源:可以 [安全检查]进程P1已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:7 5 3 [安全检查][debug]检查P3是否可以获得资源:可以 [安全检查]进程P3已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:10 5 5 [安全检查][debug]检查P5是否可以获得资源:可以 [安全检查]进程P5已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:10 5 7 系统初始状态安全 安全序列为:P2 P4 P1 P3 P5 ----------------T1---------------- 请输入选项(0:退出 1:请求资源):1 请输入进程编号(从1开始): 2 请输入请求的资源量(共3种资源): 1 0 2 进程P2请求资源:1 0 2 尝试分配后系统状态: 当前系统状态: 可用资源向量:2 3 0 最大需求矩阵矩阵: 7 5 3 3 2 2 9 0 2 2 2 2 4 3 3 分配矩阵矩阵: 0 1 0 3 0 2 3 0 2 2 1 1 0 0 2 需求矩阵矩阵: 7 4 3 0 2 0 6 0 0 0 1 1 4 3 1 [安全检查][debug]检查P1是否可以获得资源:不可以 [安全检查][debug]检查P2是否可以获得资源:可以 [安全检查]进程P2已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:5 3 2 [安全检查][debug]检查P1是否可以获得资源:不可以 [安全检查][debug]检查P3是否可以获得资源:不可以 [安全检查][debug]检查P4是否可以获得资源:可以 [安全检查]进程P4已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:7 4 3 [安全检查][debug]检查P1是否可以获得资源:可以 [安全检查]进程P1已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:7 5 3 [安全检查][debug]检查P3是否可以获得资源:可以 [安全检查]进程P3已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:10 5 5 [安全检查][debug]检查P5是否可以获得资源:可以 [安全检查]进程P5已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:10 5 7 [info]P2进程请求资源后系统仍安全,请求成功 安全序列为:P2 P4 P1 P3 P5 ----------------T2---------------- 请输入选项(0:退出 1:请求资源):1 请输入进程编号(从1开始): 5 请输入请求的资源量(共3种资源): 3 3 0 进程P5请求资源:3 3 0 [info]P5进程请求资源数超过当前可用资源,需等待 ----------------T3---------------- 请输入选项(0:退出 1:请求资源):1 请输入进程编号(从1开始): 1 请输入请求的资源量(共3种资源): 0 2 0 进程P1请求资源:0 2 0 尝试分配后系统状态: 当前系统状态: 可用资源向量:2 1 0 最大需求矩阵矩阵: 7 5 3 3 2 2 9 0 2 2 2 2 4 3 3 分配矩阵矩阵: 0 3 0 3 0 2 3 0 2 2 1 1 0 0 2 需求矩阵矩阵: 7 2 3 0 2 0 6 0 0 0 1 1 4 3 1 [安全检查][debug]检查P1是否可以获得资源:不可以 [安全检查][debug]检查P2是否可以获得资源:不可以 [安全检查][debug]检查P3是否可以获得资源:不可以 [安全检查][debug]检查P4是否可以获得资源:不可以 [安全检查][debug]检查P5是否可以获得资源:不可以 [info]P1进程请求资源将导致系统不安全,请求失败 ----------------T4---------------- 请输入选项(0:退出 1:请求资源):1 请输入进程编号(从1开始): 1 请输入请求的资源量(共3种资源): 0 1 0 进程P1请求资源:0 1 0 尝试分配后系统状态: 当前系统状态: 可用资源向量:2 2 0 最大需求矩阵矩阵: 7 5 3 3 2 2 9 0 2 2 2 2 4 3 3 分配矩阵矩阵: 0 2 0 3 0 2 3 0 2 2 1 1 0 0 2 需求矩阵矩阵: 7 3 3 0 2 0 6 0 0 0 1 1 4 3 1 [安全检查][debug]检查P1是否可以获得资源:不可以 [安全检查][debug]检查P2是否可以获得资源:可以 [安全检查]进程P2已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:5 2 2 [安全检查][debug]检查P1是否可以获得资源:不可以 [安全检查][debug]检查P3是否可以获得资源:不可以 [安全检查][debug]检查P4是否可以获得资源:可以 [安全检查]进程P4已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:7 3 3 [安全检查][debug]检查P1是否可以获得资源:可以 [安全检查]进程P1已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:7 5 3 [安全检查][debug]检查P3是否可以获得资源:可以 [安全检查]进程P3已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:10 5 5 [安全检查][debug]检查P5是否可以获得资源:可以 [安全检查]进程P5已分配资源,并且执行完成,归还资源. [安全检查]目前可用资源:10 5 7 [info]P1进程请求资源后系统仍安全,请求成功 安全序列为:P2 P4 P1 P3 P5 ----------------T5---------------- 请输入选项(0:退出 1:请求资源):0 root@debian:~/os_exp
实验X: 张民老师实验:哲学家进餐和多线程并发: https://cmd.dayi.ink/s2rrvUwHSe-0hsHmsu4Mng?view
哲学家吃饭问题
设有五位哲学家围坐在一张圆形餐桌旁,做以下两件事情之一:吃饭,或者思考。吃东西的时候,他们就停止思考,思考的时候也停止吃东西。餐桌上有五碗意大利面,每位哲学家之间各有一只餐叉。因为用一只餐叉很难吃到意大利面,所以假设哲学家必须用两只餐叉吃东西。
他们类似这样坐着:
如果 他们同时饿了
他们同时拿起左边的筷子,等待右边的人把筷子放下来。
他们都很饿,又不肯放下自己的筷子。
于是
他们一直等
然后饿死了。
如果 他们同时饿了,但是自己又比较优雅
他们同时拿起左边的筷子,等了一会,发现吃不了饭
于是他们放下了筷子,想让给别人吃饭,但是没想到他们是同时放下的。
然后过了一会再拿起筷子,但是没想到是一起拿起来的。
不断重复1、2、3的过程
资源依旧无法分配给任何人
虽然他们很谦让,但这个过程还是把全部人饿死了。
这虽然不是死锁,但缺成了活锁。
解决哲学家问题 ovo!
题1:题目要求的解法
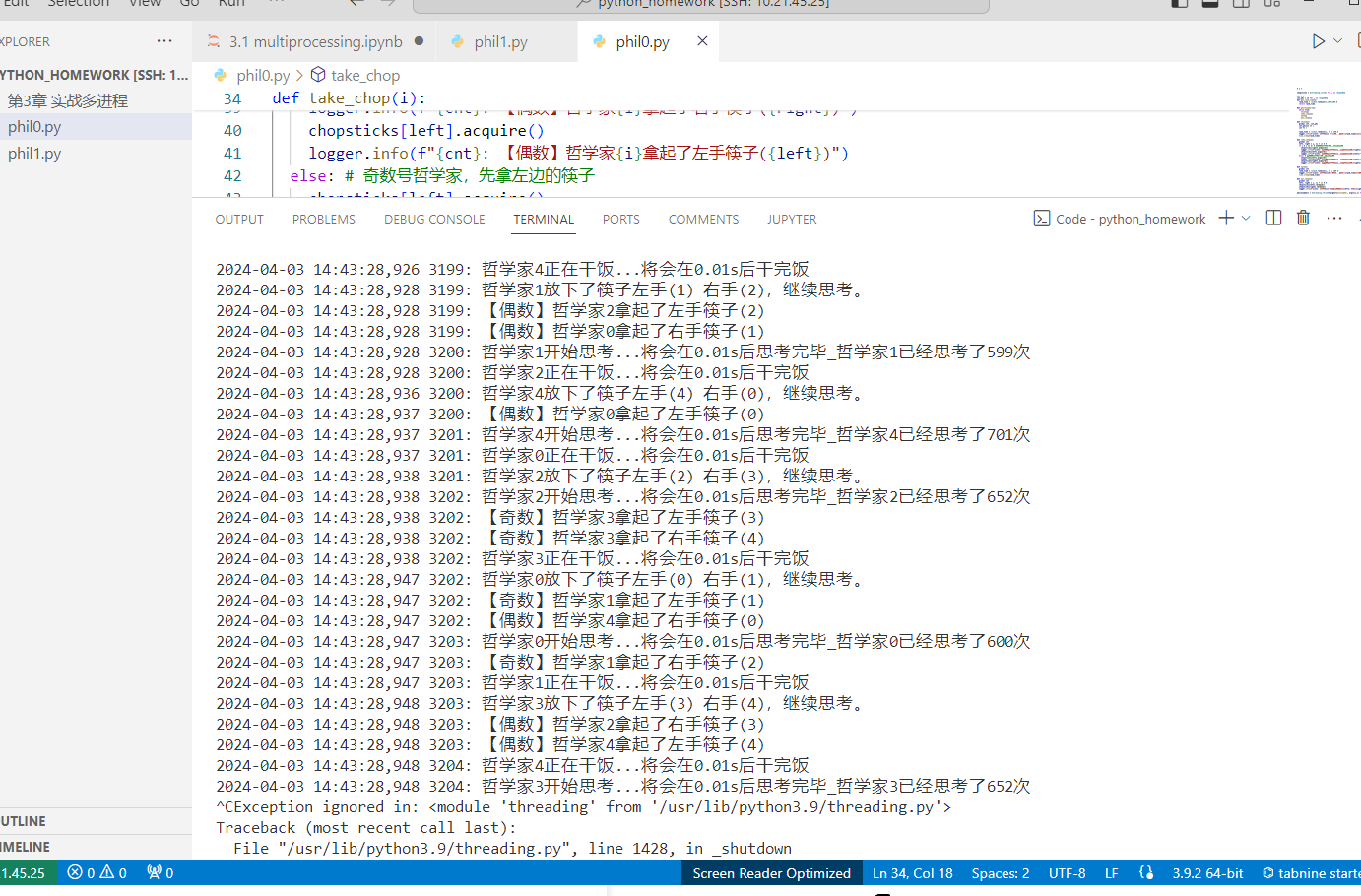
(1)对于哲学家就餐问题,为了防止出现每位哲学家拿到一支筷子而出现死锁的情况,规定奇数号的哲学家必须首先拿左边的筷子,偶数号的哲学家则反之,请编写程序实现上述策略。
逻辑:
运行:
代码
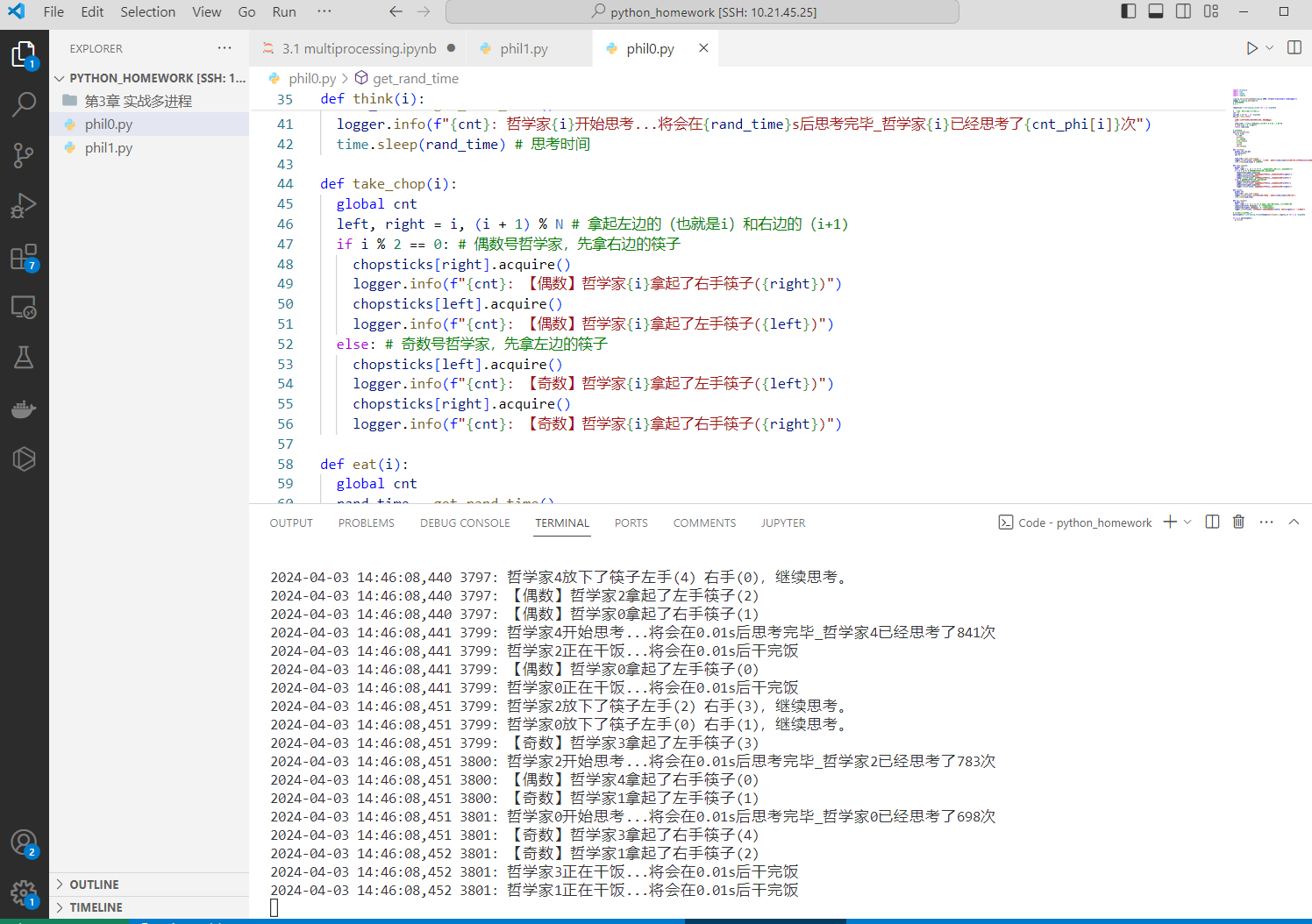
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import threadingimport timeimport randomimport logginglogging.basicConfig(level=logging.INFO, format ="%(asctime)s %(message)s" ) logger = logging.getLogger() N = 5 chopsticks = [threading.Lock() for _ in range (N)] cnt = 0 cnt_phi = [0 for _ in range (N)] def get_rand_time (): """ 获得随机时间(这里可以调整思考和干饭速率) """ rand_time = random.randint(1 ,100 )/100.0 return rand_time def philosopher (i ): while True : think(i) take_chop(i) eat(i) put_chop(i) def think (i ): global cnt,cnt_phi cnt_phi[i]+=1 cnt += 1 rand_time = get_rand_time() logger.info(f"{cnt} : 哲学家{i} 开始思考...将会在{rand_time} s后思考完毕_哲学家{i} 已经思考了{cnt_phi[i]} 次" ) time.sleep(rand_time) def take_chop (i ): global cnt left, right = i, (i + 1 ) % N if i % 2 == 0 : chopsticks[right].acquire() logger.info(f"{cnt} : 【偶数】哲学家{i} 拿起了右手筷子({right} )" ) chopsticks[left].acquire() logger.info(f"{cnt} : 【偶数】哲学家{i} 拿起了左手筷子({left} )" ) else : chopsticks[left].acquire() logger.info(f"{cnt} : 【奇数】哲学家{i} 拿起了左手筷子({left} )" ) chopsticks[right].acquire() logger.info(f"{cnt} : 【奇数】哲学家{i} 拿起了右手筷子({right} )" ) def eat (i ): global cnt rand_time = get_rand_time() logger.info(f"{cnt} : 哲学家{i} 正在干饭...将会在{rand_time} s后干完饭" ) time.sleep(rand_time) def put_chop (i ): global cnt left, right = i, (i + 1 ) % N chopsticks[left].release() chopsticks[right].release() logger.info(f"{cnt} : 哲学家{i} 放下了筷子左手({left} ) 右手({right} ),继续思考。" ) philosophers = [threading.Thread(target=philosopher, args=(i,)) for i in range (N)] for p in philosophers: p.start()
运行:
服务生解法 (dijkstra)
引入一个服务生。
哲学家不知道筷子谁正在用,但是服务生可以知道。
服务生来控制谁来用就行啦
例:
A、C正在吃东西,那么B一定获得不了筷子,所以此时不让B来获得筷子,B如果此时想吃东西,会被服务生拒绝。
同时、D如果想要申请筷子,同样的可能会导致死锁
D死锁:
A和C正在吃东西,他们各自占用了两只餐叉(A占用1号和2号,C占用3号和4号),只剩下第5只餐叉是空闲的。
假设D想要开始吃饭,他需要同时拿起4号和5号餐叉。如果他尝试并成功拿起了5号餐叉,这意味着他现在正在等待4号餐叉(目前被C持有)。
死锁:
如果E也开始尝试吃饭,并尝试拿起1号餐叉(目前被A持有),则E将等待A完成。
同时,如果A尝试再次吃东西(完成后),可能会等待E释放1号餐叉,形成一个等待循环。
常见解法:资源分级解法
哲学家进餐时,必须要先申请编号小的筷子,再申请编号大的筷子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import threadingimport timeimport randomimport logginglogging.basicConfig(level=logging.INFO, format ="%(asctime)s %(message)s" ) logger = logging.getLogger() N = 5 chopsticks = [threading.Lock() for _ in range (N)] cnt = 0 cnt_phi = [0 for _ in range (N)] def get_rand_time (): """ 获得随机时间(这里可以调整思考和干饭速率) """ rand_time = random.randint(1 ,100 )/100.0 return rand_time def philosopher (i ): while True : think(i) take_chop(i) eat(i) put_chop(i) def think (i ): global cnt,cnt_phi cnt_phi[i]+=1 cnt += 1 rand_time = random.randint(1 ,1 )/100.0 logger.info(f"{cnt} : 哲学家{i} 开始思考...将会在{rand_time} s后思考完毕_哲学家{i} 已经思考了{cnt_phi[i]} 次" ) time.sleep(rand_time) def take_chop (i ): left, right = i, (i + 1 ) % N chopsticks[min (left, right)].acquire() chopsticks[max (left, right)].acquire() logger.info(f"{cnt} : 哲学家{i} 拿起了筷子左手({left} ) 右手({right} )" ) def eat (i ): global cnt rand_time = random.randint(1 ,1 )/100.0 logger.info(f"{cnt} : 哲学家{i} 正在干饭...将会在{rand_time} s后干完饭" ) time.sleep(rand_time) def put_chop (i ): global cnt left, right = i, (i + 1 ) % N chopsticks[left].release() chopsticks[right].release() logger.info(f"{cnt} : 哲学家{i} 放下了筷子左手({left} ) 右手({right} ),继续思考。" ) philosophers = [threading.Thread(target=philosopher, args=(i,)) for i in range (N)] for p in philosophers: p.start()
题2:进程同步PV
(2)有n个接收消息的进程A1,A2,……An和一个发送消息的进程B,他们共享一个容量为1的缓冲区。发送进程B不断地通过缓冲区向进程A1,A2,……An发送消息。发送到缓冲区的每个消息,必须等所有的接收进程A1,A2,……An各取一次且仅限一次后,进程B才能继续发送消息。请编写程序实现这n+1个进程的同步。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 from multiprocessing import Process, Semaphore, Condition, Value, Lockimport time,logginglogging.basicConfig(level=logging.INFO, format ="%(asctime)s %(message)s" ) logger = logging.getLogger() n = 5 buffer_semaphore = Semaphore(1 ) receive_semaphore = Semaphore(0 ) condition_lock = Lock() condition = Condition(condition_lock) counter = Value('i' , 0 ) def receive_process (id , counter, buffer_semaphore, condition, receive_semaphore while True : try : receive_semaphore.acquire() buffer_semaphore.acquire() with condition: counter.value += 1 logger.info(f'接收进程 {id } 接收了消息 当前计数器:{counter.value} ' ) if counter.value == n: condition.notify() buffer_semaphore.release() time.sleep(0.1 ) except KeyboardInterrupt as e: logger.warning(f"进程 【{i} 】 检测到CTRL+C" ) return msg_num = 0 def send_process (counter, condition, receive_semaphore ): global msg_num while True : try : with condition: logger.info("=======================" ) msg_num += 1 logger.info(f'[{msg_num} ]发送进程 B 发送了一条消息' ) for _ in range (n): receive_semaphore.release() counter.value = 0 condition.wait() time.sleep(1 ) except KeyboardInterrupt as e: logger.warning(f"进程 【发送者】 检测到CTRL+C" ) return if __name__ == '__main__' : Process(target=send_process, args=(counter, condition, receive_semaphore)).start() for i in range (n): Process(target=receive_process, args=(i+1 , counter, buffer_semaphore, condition, receive_semaphore)).start()
运行:
50进程:
稳定性还可以:1024进程:
代码下载: https://pic.icee.top/web/python作业3_f1a499e8-f19b-11ee-a978-bfb4fb8d915e.rar
实验三、页式地址重定位模拟 一、实验目的: 1、用高级语言编写和调试模拟实现页式地址重定位。
二、实验原理: 当进程在CPU上运行时,如指令中涉及逻辑地址时,操作系统自动根据页长得到页号和页内偏移,把页内偏移拷贝到物理地址寄存器,再根据页号,查页表,得到该页在内存中的块号,把块号左移页长的位数,写到物理地址寄存器。
三、实验内容: 1、设计页表结构
原理
逻辑地址(Logical Address) :程序使用的地址,由页号(Page Number)和页内偏移(Page Offset)组成。逻辑地址计算 :物理地址(Physical Address) :实际在物理内存中的地址,由块号(Block Number)和块内偏移(Block Offset)组成。物理地址计算 :页表(Page Table) :存储每个页号对应的块号。页表的索引是页号,值是块号。页大小(Page Size) :每个页面的大小,通常是2的幂,如4KB。页号(Page Number) :逻辑地址除以页大小的商。页号计算 :页内偏移(Page Offset) :逻辑地址除以页大小的余数。页内偏移计算 :
设计页表结构 页表是一个数组,其中每个元素称为页表项(PTE),包含了页号和对应的块号。可以用以下符号来表示:
$PTE_i = (PN_i, BN_i)$
其中:
$PTE_i$表示第$i$个页表项。
$PN_i$表示第$i$个页表项的页号。
$BN_i$表示第$i$个页表项对应的块号。
页表的长度为$N$,即有$N$个页表项:
$PageTable = [PTE_0, PTE_1, \dots, PTE_{N-1}]$
设计地址重定位算法 给定一个逻辑地址$LA$,地址重定位算法的目标是将其转换为对应的物理地址$PA$。
首先,将逻辑地址$LA$划分为页号$PN$和页内偏移$PO$:
$PN = \lfloor \frac{LA}{PageSize} \rfloor$
其中:$PageSize$为页大小。
检查页号$PN$是否越界:
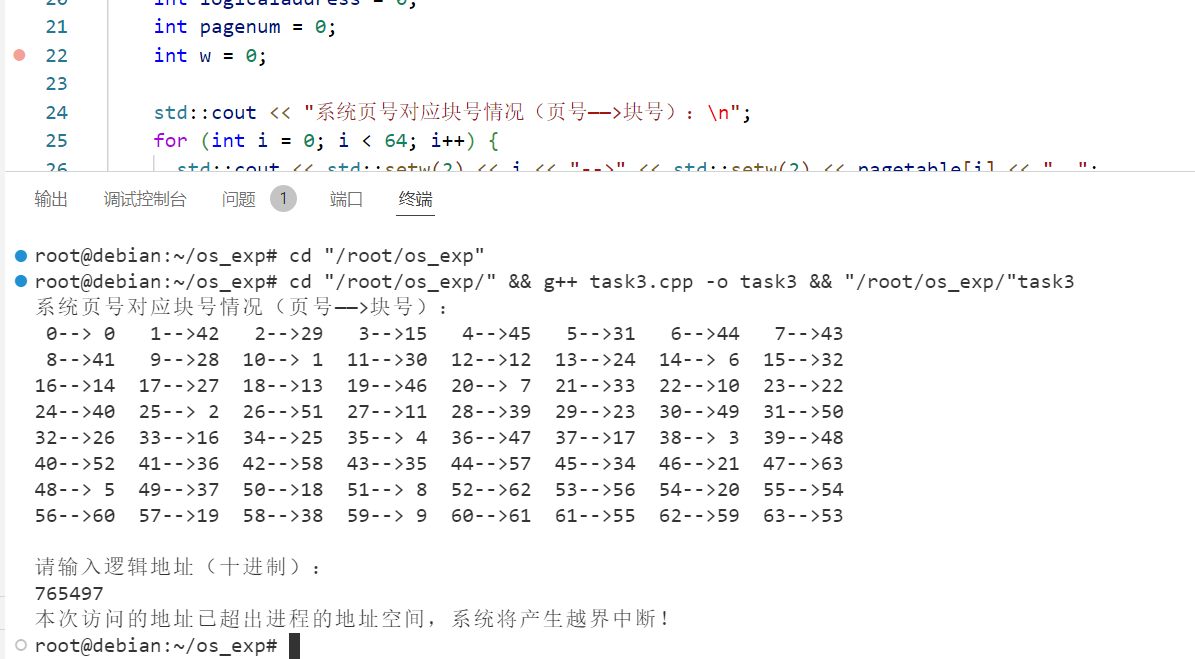
如果$PN$越界,则发生越界中断。
如果$PN$没有越界,则从页表中获取对应的块号$BN$:
$BN = PageTable[PN].BN$
计算物理地址$PA$:
$PA = BN \times PageSize + PO$
地址重定位算法可以用以下公式表示:
$$
其中:
$PA$ 表示物理地址
$BN$ 表示块号
$\text{PageSize}$ 表示页大小
$PO$ 表示页偏移
$PN$ 表示页号
$N$ 表示页号的最大值
其中:$BN = PageTable[PN].BN$。
原始代码
可以直接跑应该。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <iostream> #include <iomanip> const int pagesize = 1024 ;const int pagetablelength = 64 ;const int pagetable[pagetablelength] = { 0 , 42 , 29 , 15 , 45 , 31 , 44 , 43 , 41 , 28 , 1 , 30 , 12 , 24 , 6 , 32 , 14 , 27 , 13 , 46 , 7 , 33 , 10 , 22 , 40 , 2 , 51 , 11 , 39 , 23 , 49 , 50 , 26 , 16 , 25 , 4 , 47 , 17 , 3 , 48 , 52 , 36 , 58 , 35 , 57 , 34 , 21 , 63 , 5 , 37 , 18 , 8 , 62 , 56 , 20 , 54 , 60 , 19 , 38 , 9 , 61 , 55 , 59 , 53 }; int main () int logicaladdress = 0 ; int pagenum = 0 ; int w = 0 ; std::cout << "系统页号对应块号情况(页号——>块号):\n" ; for (int i = 0 ; i < 64 ; i++) { std::cout << std::setw (2 ) << i << "-->" << std::setw (2 ) << pagetable[i] << " " ; if (i % 8 == 7 )std::cout << std::endl; } std::cout << std::endl << "请输入逻辑地址(十进制):\n" ; std::cin >> logicaladdress; pagenum = logicaladdress / pagesize; w = logicaladdress % pagesize; if (pagenum >= pagetablelength) { std::cout << "本次访问的地址已超出进程的地址空间,系统将产生越界中断!\n" ; return 0 ; } std::cout << "对应的物理地址为(十进制):\n" << pagetable[pagenum] * pagesize + w << std::endl; return 0 ; }
好像也没什么需要改的。
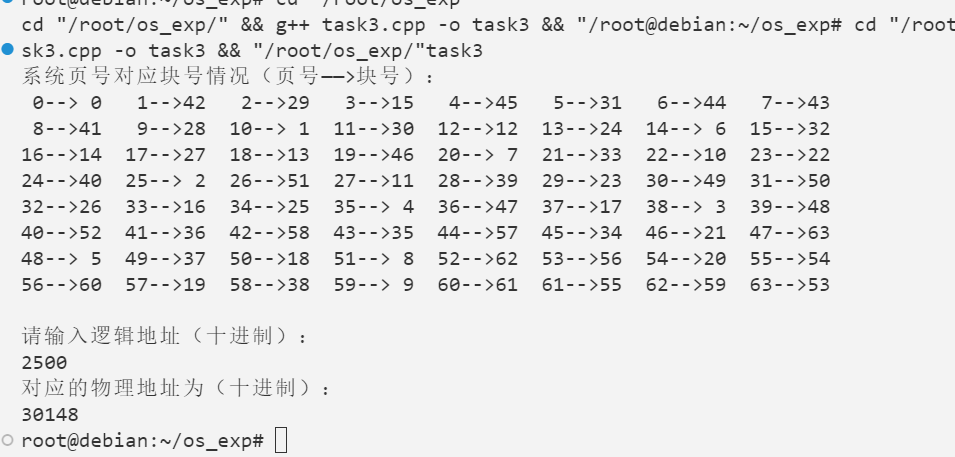
调试数据2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 root@debian:~/os_exp 系统页号对应块号情况(页号——>块号): 0--> 0 1-->42 2-->29 3-->15 4-->45 5-->31 6-->44 7-->43 8-->41 9-->28 10--> 1 11-->30 12-->12 13-->24 14--> 6 15-->32 16-->14 17-->27 18-->13 19-->46 20--> 7 21-->33 22-->10 23-->22 24-->40 25--> 2 26-->51 27-->11 28-->39 29-->23 30-->49 31-->50 32-->26 33-->16 34-->25 35--> 4 36-->47 37-->17 38--> 3 39-->48 40-->52 41-->36 42-->58 43-->35 44-->57 45-->34 46-->21 47-->63 48--> 5 49-->37 50-->18 51--> 8 52-->62 53-->56 54-->20 55-->54 56-->60 57-->19 58-->38 59--> 9 60-->61 61-->55 62-->59 63-->53 请输入逻辑地址(十进制): 765497 本次访问的地址已超出进程的地址空间,系统将产生越界中断! root@debian:~/os_exp
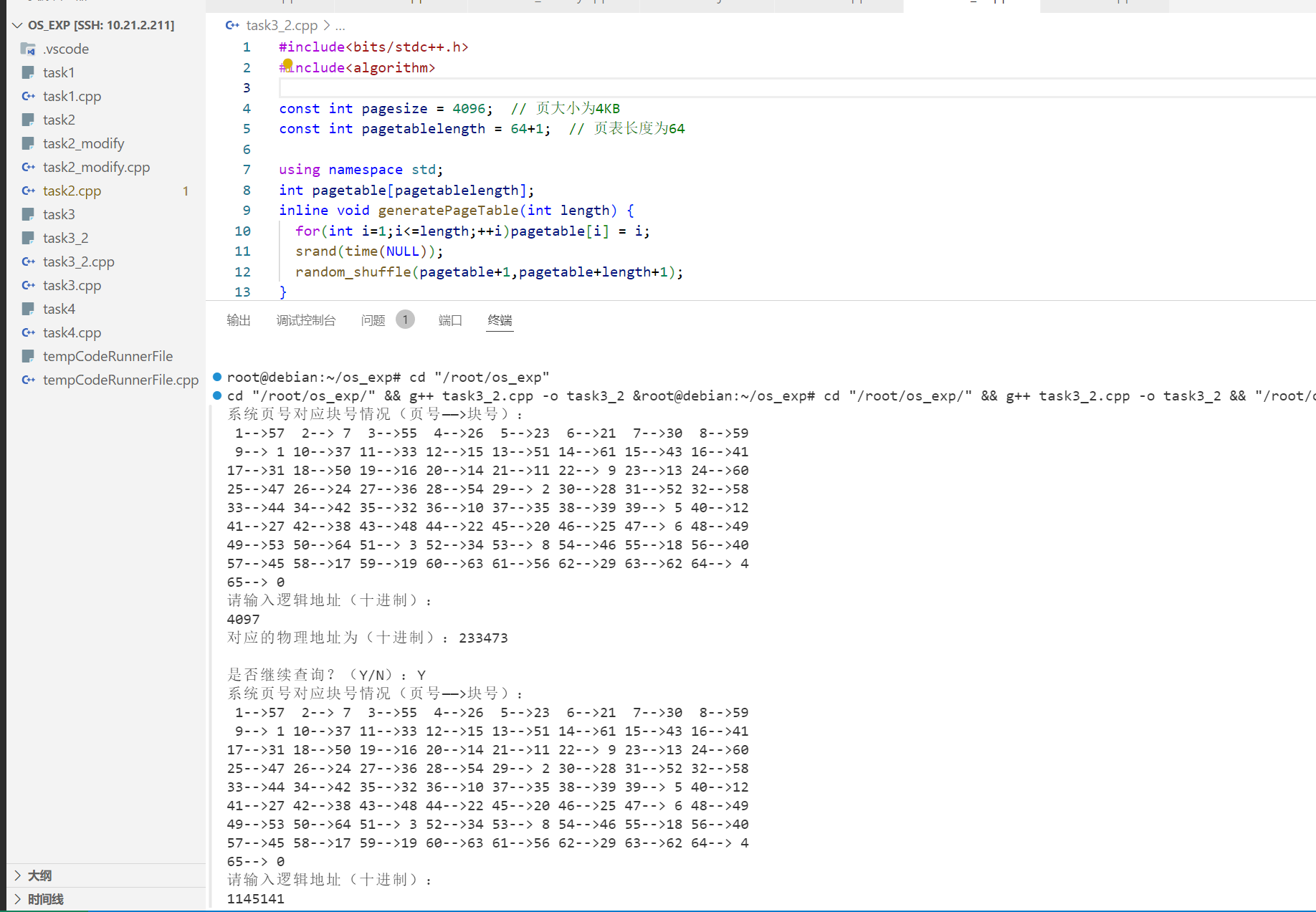
4K大小的页表,换汤不换药,随机块 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <bits/stdc++.h> #include <algorithm> const int pagesize = 4096 ; const int pagetablelength = 64 +1 ; using namespace std;int pagetable[pagetablelength];inline void generatePageTable (int length) for (int i=1 ;i<=length;++i)pagetable[i] = i; srand (time (NULL )); random_shuffle (pagetable+1 ,pagetable+length+1 ); } int main () generatePageTable (64 ); while (true ) { printf ("系统页号对应块号情况(页号——>块号):\n" ); for (int i=1 ;i<=pagetablelength;++i){ printf ("%2d-->%2d " ,i,pagetable[i]); if (i%8 ==0 )printf ("\n" ); } int logicaladdress; printf ("\n请输入逻辑地址(十进制):\n" ); scanf ("%d" , &logicaladdress); if (logicaladdress < 0 ) { printf ("输入的逻辑地址无效,程序结束。\n" ); break ; } int pagenum=logicaladdress/pagesize; int w=logicaladdress%pagesize; if (pagenum>=pagetablelength) { printf ("本次访问的地址已超出进程的地址空间,系统将产生越界中断!\n" ); } else { int addr = pagetable[pagenum] * pagesize + w; printf ("对应的物理地址为(十进制):%d\n" ,addr); } printf ("\n是否继续查询?(Y/N):" ); char choice; scanf (" %c" , &choice); if (choice != 'Y' && choice != 'y' ) { printf ("程序结束。\n" ); break ; } } return 0 ; }
输出 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 cd "/root/os_exp/" && g++ task3_2.cpp -o task3_2 &root@debian:~/os_exp系统页号对应块号情况(页号——>块号): 1-->57 2--> 7 3-->55 4-->26 5-->23 6-->21 7-->30 8-->59 9--> 1 10-->37 11-->33 12-->15 13-->51 14-->61 15-->43 16-->41 17-->31 18-->50 19-->16 20-->14 21-->11 22--> 9 23-->13 24-->60 25-->47 26-->24 27-->36 28-->54 29--> 2 30-->28 31-->52 32-->58 33-->44 34-->42 35-->32 36-->10 37-->35 38-->39 39--> 5 40-->12 41-->27 42-->38 43-->48 44-->22 45-->20 46-->25 47--> 6 48-->49 49-->53 50-->64 51--> 3 52-->34 53--> 8 54-->46 55-->18 56-->40 57-->45 58-->17 59-->19 60-->63 61-->56 62-->29 63-->62 64--> 4 65--> 0 请输入逻辑地址(十进制): 4097 对应的物理地址为(十进制):233473 是否继续查询?(Y/N):Y 系统页号对应块号情况(页号——>块号): 1-->57 2--> 7 3-->55 4-->26 5-->23 6-->21 7-->30 8-->59 9--> 1 10-->37 11-->33 12-->15 13-->51 14-->61 15-->43 16-->41 17-->31 18-->50 19-->16 20-->14 21-->11 22--> 9 23-->13 24-->60 25-->47 26-->24 27-->36 28-->54 29--> 2 30-->28 31-->52 32-->58 33-->44 34-->42 35-->32 36-->10 37-->35 38-->39 39--> 5 40-->12 41-->27 42-->38 43-->48 44-->22 45-->20 46-->25 47--> 6 48-->49 49-->53 50-->64 51--> 3 52-->34 53--> 8 54-->46 55-->18 56-->40 57-->45 58-->17 59-->19 60-->63 61-->56 62-->29 63-->62 64--> 4 65--> 0 请输入逻辑地址(十进制): 1145141 本次访问的地址已超出进程的地址空间,系统将产生越界中断! 是否继续查询?(Y/N):N 程序结束。
实验四、LRU算法模拟 一、实验目的和要求 用高级语言模拟页面置换算法LRU,加深对LRU算法的认识。
二、实验原理 其基本原理为:如果某一个页面被访问了,它很可能还要被访问;相反,如果它长时间不被访问,再最近未来是不大可能被访问的。
三、实验环境 1、pc
四、程序源代码:
源代码用的栈模拟的,但我感觉效率不是很高诶,还是用栈写一下。
原理
对于每一个需要调入内存的页面(由 workstep 数组记录):
首先检查当前栈中是否已经有该页面。如果有,则无需发生中断,直接跳到下一个页面。($O(N)$复杂度)
如果没有该页面,检查栈中是否有空位置。如果有空位置,直接将页面放入空位置,并记录一次中断。($O(N)$复杂度)
如果栈满且没有空位置,执行页面置换:
将栈底的页面(最不常用的页面)调出,并将新的页面放入栈顶,记录一次中断。 ($O(N)$复杂度)
将新调入的页面放入栈顶,并将其他页面依次下移。 ($O(N)$复杂度)
简单写一下,这样做的缺点就是空间没法重复利用,但是重复利用其实也简单,跑到最后重置下指针,复制一下栈的数据即可。
写完后感觉更像一个队列吧,不太像一个栈。
然后就是模拟过程:
模拟页面置换过程
初始化与输入:
初始化栈的指针,设定栈的大小和容量。
通过输入获得所需调入内存的页面序列。
页面处理逻辑:
遍历每一个页面。
对于每个页面,首先检查它是否已经在栈中:
如果页面已存在 (栈中有此页面):
不需要进行页面置换,因此无中断发生。
将此页面移动到栈顶,表示最近被访问。
如果页面不存在 (栈中无此页面):
检查栈是否已满:
如果栈未满 :
直接将页面放入栈顶。
记录一次中断,因为发生了页面调入。
如果栈已满 :
移除栈底的页面(最不常用的页面),并将新页面放入栈顶。
记录一次中断,因为发生了页面置换。
特点与效率考量
时间复杂度 :每个页面的处理都需要遍历栈以检查是否存在该页面,因此时间复杂度为 $O(N*M)$,其中 $N$ 为栈的大小、$M$ 为作业队列的大小
空间复杂度 :由于使用了一个固定大小的栈来存储页面,空间复杂度为 $O(N)$。
效率问题 :每次查询页面是否存在都需要遍历整个栈,这在栈较大时效率较低。
空间未充分利用 :在栈满时,仅替换栈底的页面而不考虑页面的访问频率,可能导致不是最优的置换决策。
倒是可以通过使用双向链表和哈希表的组合来实现更高效的 LRU 算法,那样可以在 $O(1)$ (实际上计算也不少常数)时间复杂度内完成页面的查询、添加和删除操作。
考虑使用更多的高级数据结构,平衡树(如红黑树)或优先队列,来优化页面的存储和检索效率。
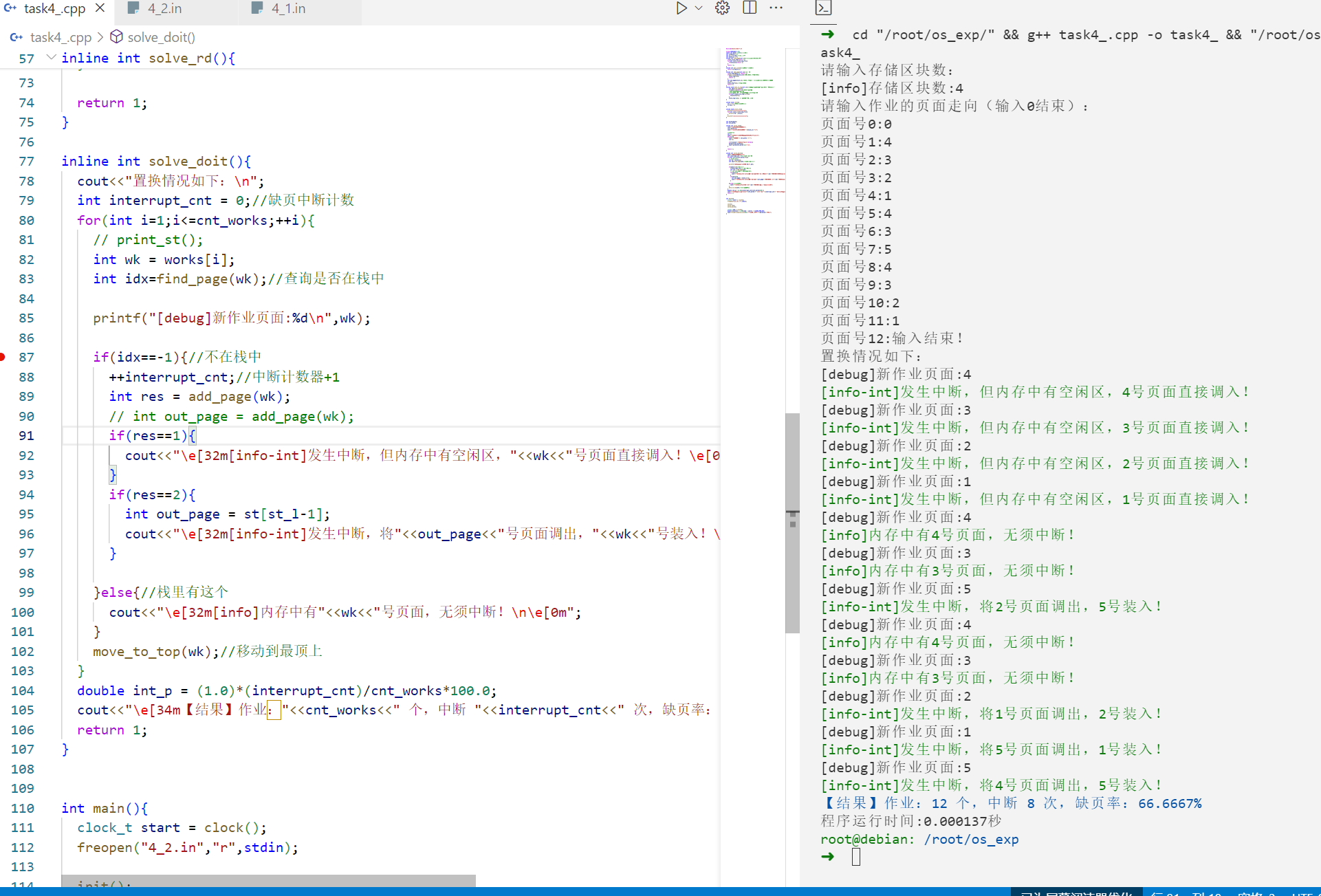
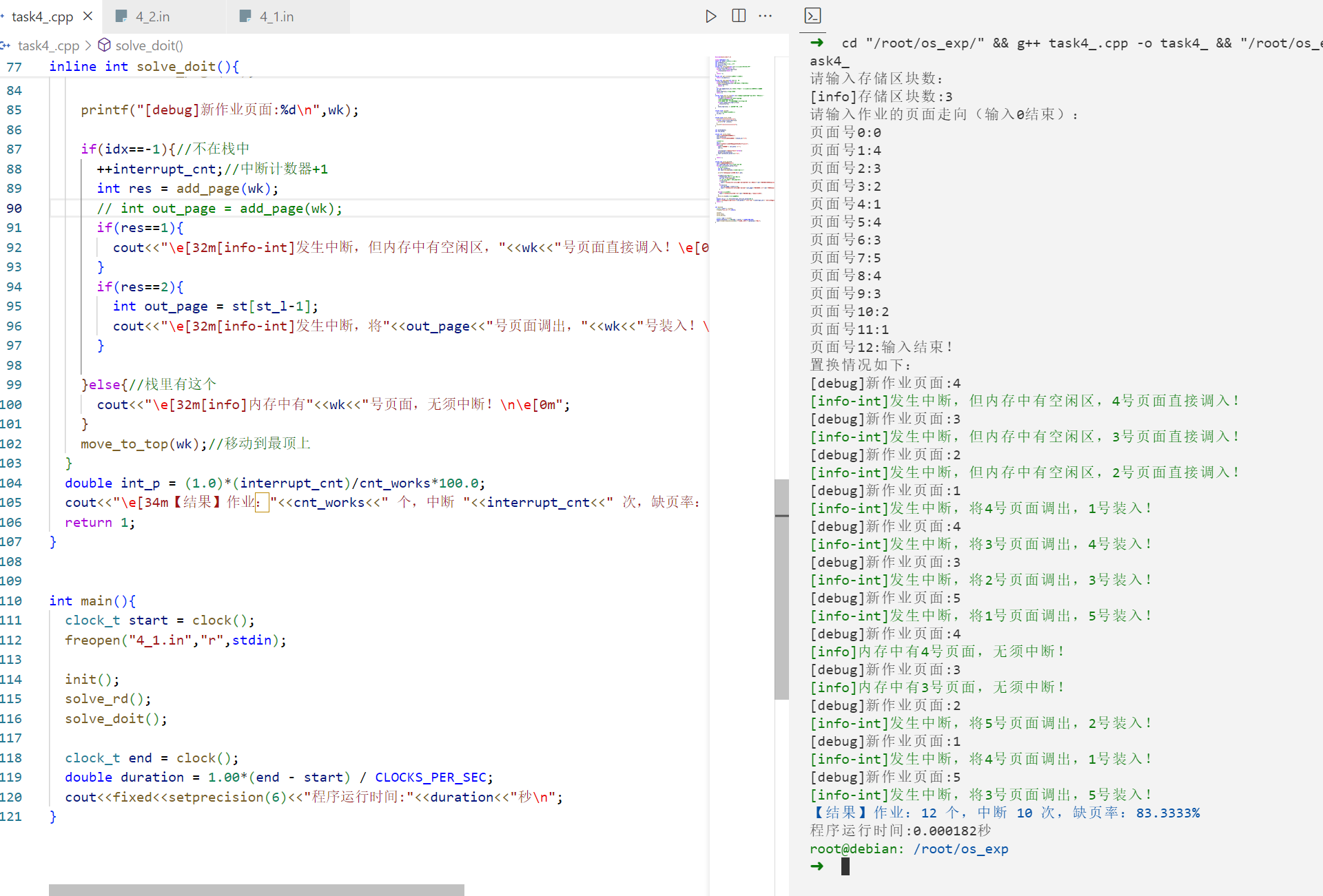
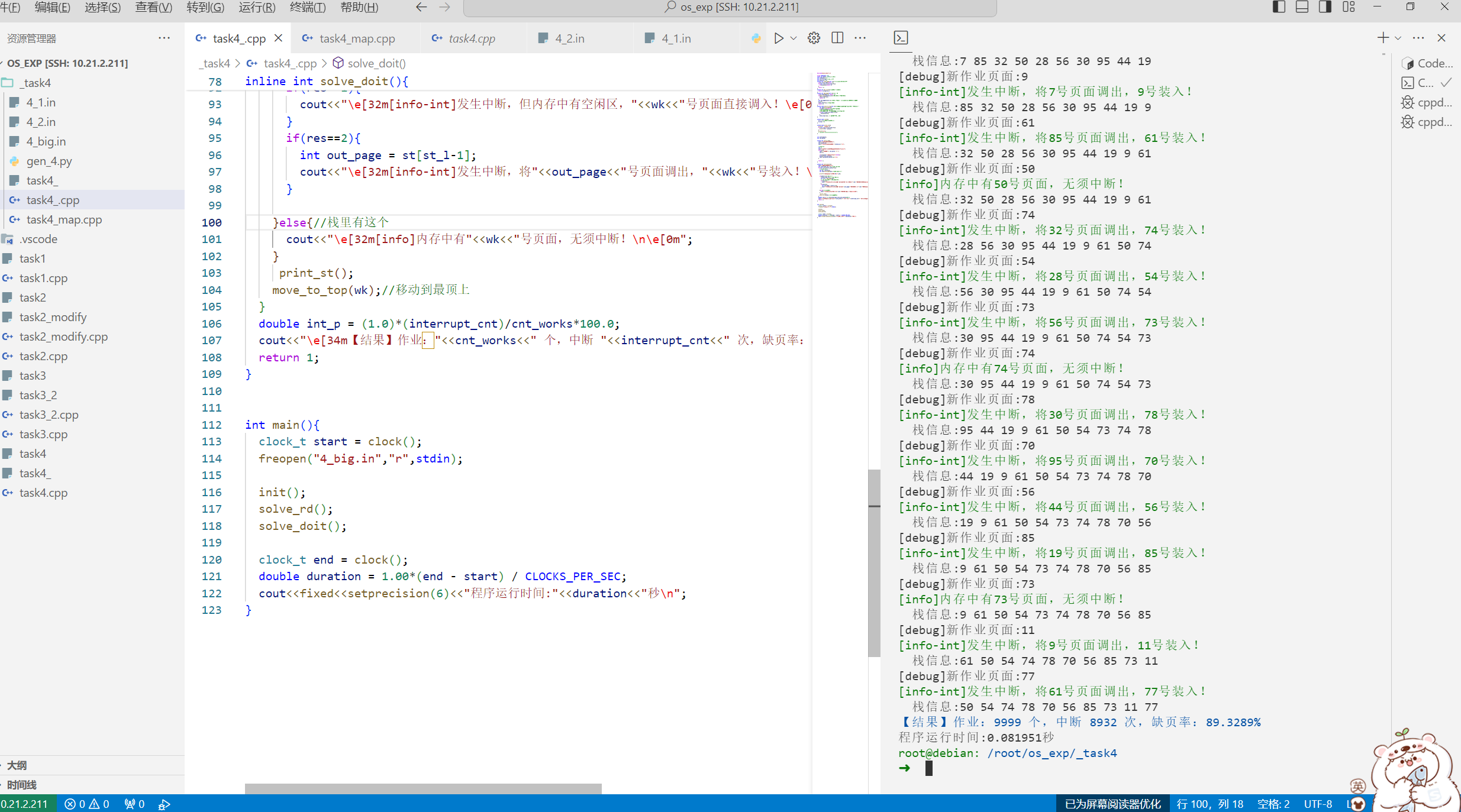
运行: 样例1: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 ➜ cd "/root/os_exp/" && g++ task4_.cpp -o task4_ && "/root/os_exp/" t ask4_ 请输入存储区块数: [info]存储区块数:3 请输入作业的页面走向(输入0结束): 页面号0:0 页面号1:4 页面号2:3 页面号3:2 页面号4:1 页面号5:4 页面号6:3 页面号7:5 页面号8:4 页面号9:3 页面号10:2 页面号11:1 页面号12:输入结束! 置换情况如下: [debug]新作业页面:4 [info-int]发生中断,但内存中有空闲区,4号页面直接调入! [debug]新作业页面:3 [info-int]发生中断,但内存中有空闲区,3号页面直接调入! [debug]新作业页面:2 [info-int]发生中断,但内存中有空闲区,2号页面直接调入! [debug]新作业页面:1 [info-int]发生中断,将4号页面调出,1号装入! [debug]新作业页面:4 [info-int]发生中断,将3号页面调出,4号装入! [debug]新作业页面:3 [info-int]发生中断,将2号页面调出,3号装入! [debug]新作业页面:5 [info-int]发生中断,将1号页面调出,5号装入! [debug]新作业页面:4 [info]内存中有4号页面,无须中断! [debug]新作业页面:3 [info]内存中有3号页面,无须中断! [debug]新作业页面:2 [info-int]发生中断,将5号页面调出,2号装入! [debug]新作业页面:1 [info-int]发生中断,将4号页面调出,1号装入! [debug]新作业页面:5 [info-int]发生中断,将3号页面调出,5号装入! 【结果】作业:12 个,中断 10 次,缺页率:83.3333% 程序运行时间:0.000182秒 root@debian: /root/os_exp
带栈信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 root@debian: /root/os_exp/_task4 ➜ cd "/root/os_exp/_task4/" && g++ task4_.cpp -o task4_ && "/root/os _exp/_task4/" task4_请输入存储区块数: [info]存储区块数:3 请输入作业的页面走向(输入0结束): 页面号0:0 页面号1:4 页面号2:3 页面号3:2 页面号4:1 页面号5:4 页面号6:3 页面号7:5 页面号8:4 页面号9:3 页面号10:2 页面号11:1 页面号12:输入结束! 置换情况如下: [debug]新作业页面:4 [info-int]发生中断,但内存中有空闲区,4号页面直接调入! 栈信息:4 [debug]新作业页面:3 [info-int]发生中断,但内存中有空闲区,3号页面直接调入! 栈信息:4 3 [debug]新作业页面:2 [info-int]发生中断,但内存中有空闲区,2号页面直接调入! 栈信息:4 3 2 [debug]新作业页面:1 [info-int]发生中断,将4号页面调出,1号装入! 栈信息:3 2 1 [debug]新作业页面:4 [info-int]发生中断,将3号页面调出,4号装入! 栈信息:2 1 4 [debug]新作业页面:3 [info-int]发生中断,将2号页面调出,3号装入! 栈信息:1 4 3 [debug]新作业页面:5 [info-int]发生中断,将1号页面调出,5号装入! 栈信息:4 3 5 [debug]新作业页面:4 [info]内存中有4号页面,无须中断! 栈信息:4 3 5 [debug]新作业页面:3 [info]内存中有3号页面,无须中断! 栈信息:3 5 4 [debug]新作业页面:2 [info-int]发生中断,将5号页面调出,2号装入! 栈信息:4 3 2 [debug]新作业页面:1 [info-int]发生中断,将4号页面调出,1号装入! 栈信息:3 2 1 [debug]新作业页面:5 [info-int]发生中断,将3号页面调出,5号装入! 栈信息:2 1 5 【结果】作业:12 个,中断 10 次,缺页率:83.3333% 程序运行时间:0.000148秒
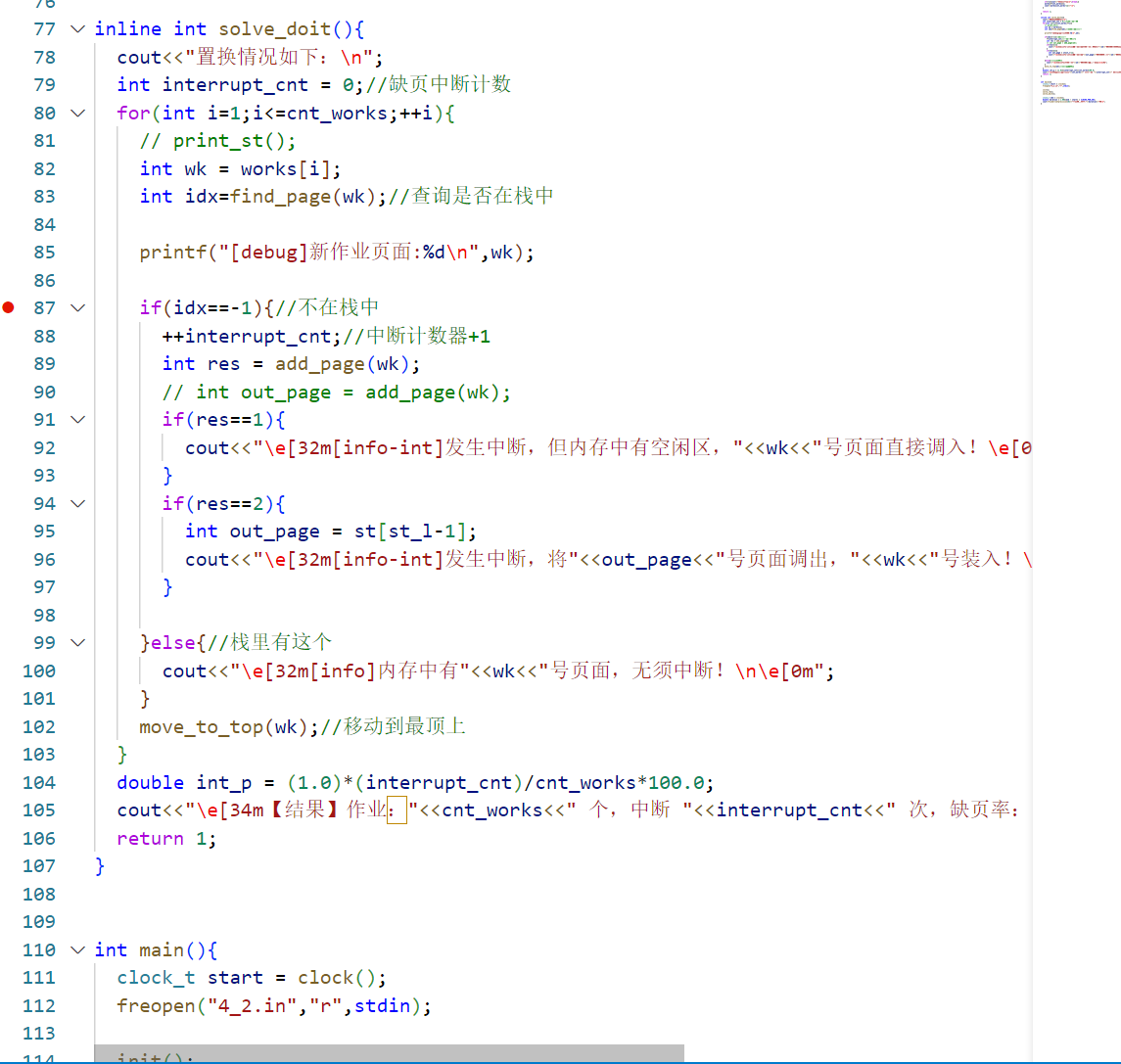
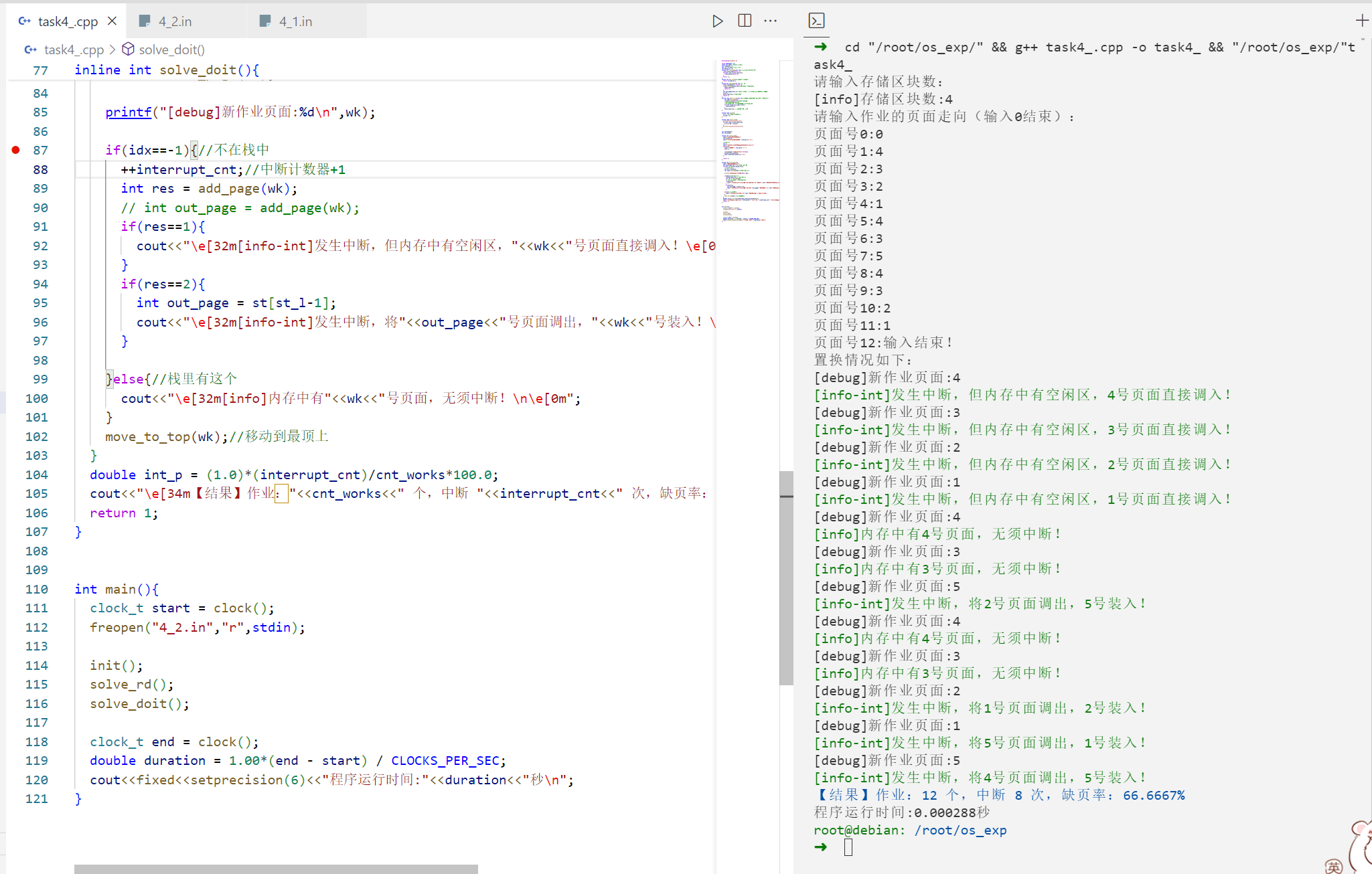
样例2: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 ➜ cd "/root/os_exp/" && g++ task4_.cpp -o task4_ && "/root/os_exp/" t ask4_ 请输入存储区块数: [info]存储区块数:4 请输入作业的页面走向(输入0结束): 页面号0:0 页面号1:4 页面号2:3 页面号3:2 页面号4:1 页面号5:4 页面号6:3 页面号7:5 页面号8:4 页面号9:3 页面号10:2 页面号11:1 页面号12:输入结束! 置换情况如下: [debug]新作业页面:4 [info-int]发生中断,但内存中有空闲区,4号页面直接调入! [debug]新作业页面:3 [info-int]发生中断,但内存中有空闲区,3号页面直接调入! [debug]新作业页面:2 [info-int]发生中断,但内存中有空闲区,2号页面直接调入! [debug]新作业页面:1 [info-int]发生中断,但内存中有空闲区,1号页面直接调入! [debug]新作业页面:4 [info]内存中有4号页面,无须中断! [debug]新作业页面:3 [info]内存中有3号页面,无须中断! [debug]新作业页面:5 [info-int]发生中断,将2号页面调出,5号装入! [debug]新作业页面:4 [info]内存中有4号页面,无须中断! [debug]新作业页面:3 [info]内存中有3号页面,无须中断! [debug]新作业页面:2 [info-int]发生中断,将1号页面调出,2号装入! [debug]新作业页面:1 [info-int]发生中断,将5号页面调出,1号装入! [debug]新作业页面:5 [info-int]发生中断,将4号页面调出,5号装入! 【结果】作业:12 个,中断 8 次,缺页率:66.6667% 程序运行时间:0.000137秒
带栈信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 root@debian: /root/os_exp/_task4 ➜ cd "/root/os_exp/_task4/" && g++ task4_.cpp -o task4_ && "/root/os _exp/_task4/" task4_请输入存储区块数: [info]存储区块数:4 请输入作业的页面走向(输入0结束): 页面号0:0 页面号1:4 页面号2:3 页面号3:2 页面号4:1 页面号5:4 页面号6:3 页面号7:5 页面号8:4 页面号9:3 页面号10:2 页面号11:1 页面号12:输入结束! 置换情况如下: [debug]新作业页面:4 [info-int]发生中断,但内存中有空闲区,4号页面直接调入! 栈信息:4 [debug]新作业页面:3 [info-int]发生中断,但内存中有空闲区,3号页面直接调入! 栈信息:4 3 [debug]新作业页面:2 [info-int]发生中断,但内存中有空闲区,2号页面直接调入! 栈信息:4 3 2 [debug]新作业页面:1 [info-int]发生中断,但内存中有空闲区,1号页面直接调入! 栈信息:4 3 2 1 [debug]新作业页面:4 [info]内存中有4号页面,无须中断! 栈信息:4 3 2 1 [debug]新作业页面:3 [info]内存中有3号页面,无须中断! 栈信息:3 2 1 4 [debug]新作业页面:5 [info-int]发生中断,将2号页面调出,5号装入! 栈信息:1 4 3 5 [debug]新作业页面:4 [info]内存中有4号页面,无须中断! 栈信息:1 4 3 5 [debug]新作业页面:3 [info]内存中有3号页面,无须中断! 栈信息:1 3 5 4 [debug]新作业页面:2 [info-int]发生中断,将1号页面调出,2号装入! 栈信息:5 4 3 2 [debug]新作业页面:1 [info-int]发生中断,将5号页面调出,1号装入! 栈信息:4 3 2 1 [debug]新作业页面:5 [info-int]发生中断,将4号页面调出,5号装入! 栈信息:3 2 1 5 【结果】作业:12 个,中断 8 次,缺页率:66.6667% 程序运行时间:0.000150秒
一个比较大的样例
数据
执行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 [info-int]发生中断,将19号页面调出,85号装入! 栈信息:9 61 50 54 73 74 78 70 56 85 [debug]新作业页面:73 [info]内存中有73号页面,无须中断! 栈信息:9 61 50 54 73 74 78 70 56 85 [debug]新作业页面:11 [info-int]发生中断,将9号页面调出,11号装入! 栈信息:61 50 54 74 78 70 56 85 73 11 [debug]新作业页面:77 [info-int]发生中断,将61号页面调出,77号装入! 栈信息:50 54 74 78 70 56 85 73 11 77 【结果】作业:9999 个,中断 8932 次,缺页率:89.3289% 程序运行时间:0.081951秒
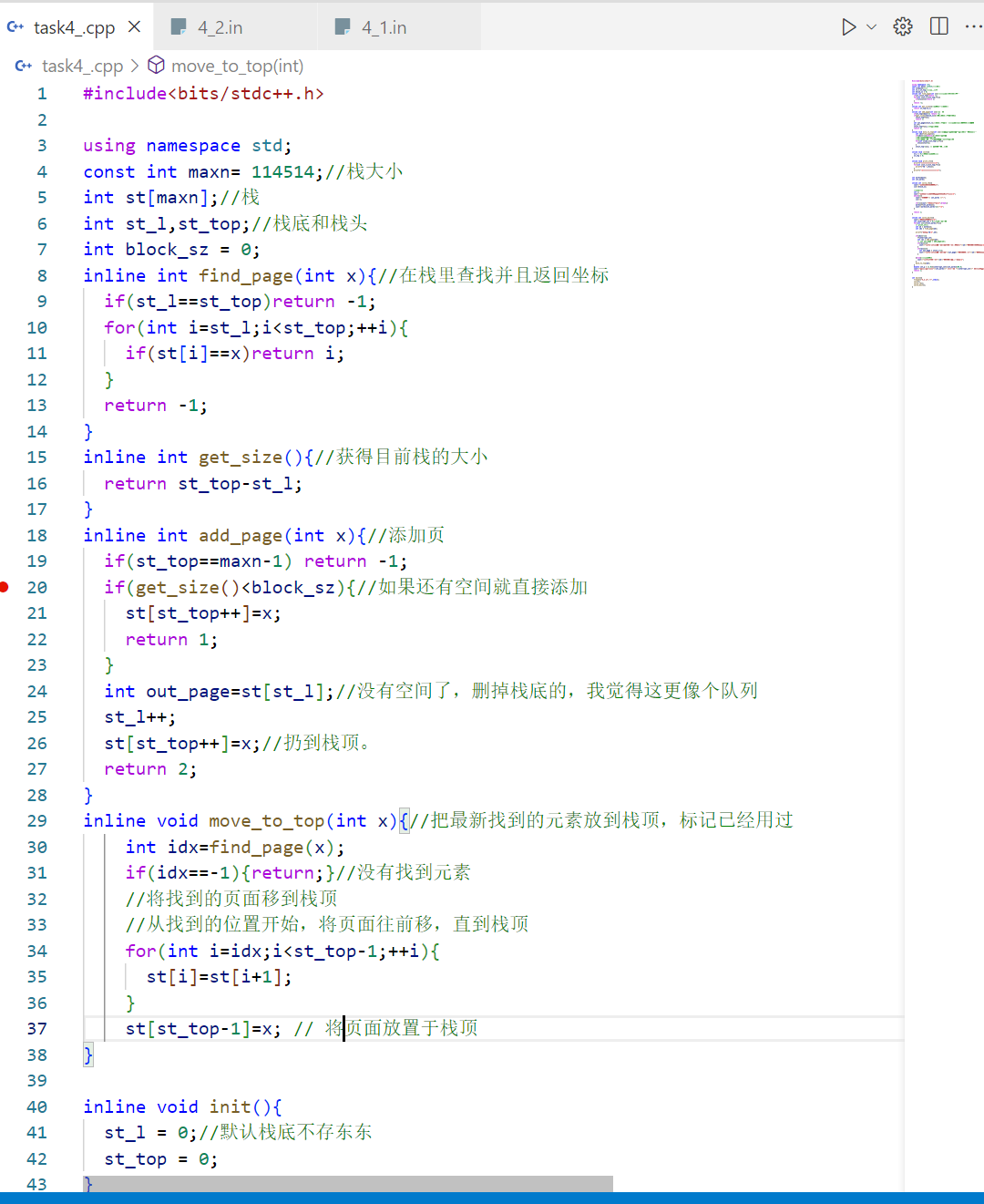
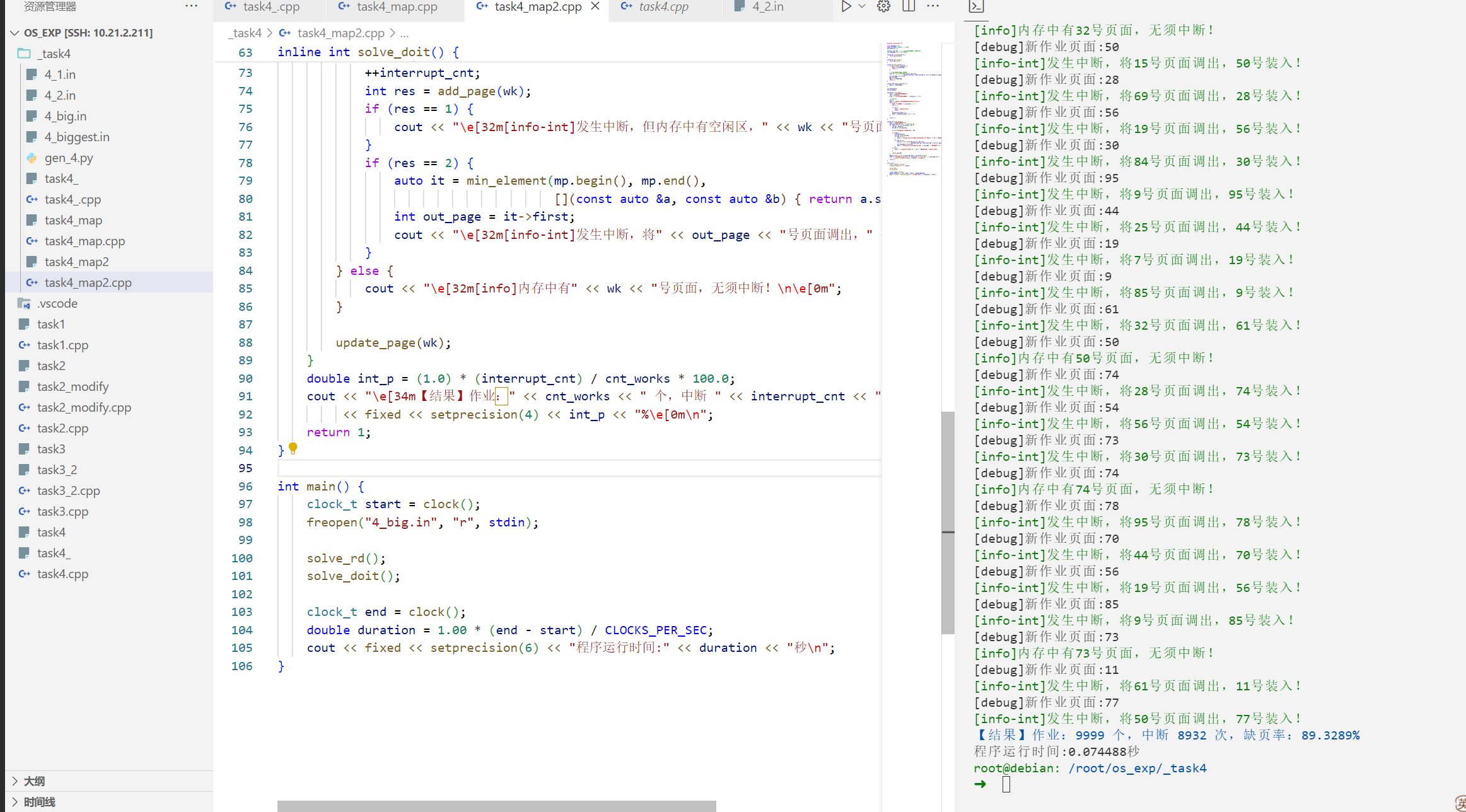
“栈”实现LRU的代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 #include <bits/stdc++.h> using namespace std;const int maxn= 114514 ;int st[maxn];int st_l,st_top;int block_sz = 0 ;inline int find_page (int x) if (st_l==st_top)return -1 ; for (int i=st_l;i<st_top;++i){ if (st[i]==x)return i; } return -1 ; } inline int get_size () return st_top-st_l; } inline int add_page (int x) if (st_top==maxn-1 ) return -1 ; if (get_size ()<block_sz){ st[st_top++]=x; return 1 ; } int out_page=st[st_l]; st_l++; st[st_top++]=x; return 2 ; } inline void move_to_top (int x) int idx=find_page (x); if (idx==-1 ){return ;} for (int i=idx;i<st_top-1 ;++i){ st[i]=st[i+1 ]; } st[st_top-1 ]=x; } inline void init () st_l = 0 ; st_top = 0 ; } inline void print_st () printf (" 栈信息:" ); for (int i=st_l;i<st_top;++i){ printf ("%d " ,st[i]); } printf ("\n" ); } int works[maxn];int cnt_works;inline int solve_rd () cout<<"请输入存储区块数:" ; cin>>block_sz; cout<<"\n[info]存储区块数:" <<block_sz<<"\n" ; int x; cout<<"请输入作业的页面走向(输入0结束):\n" ; while (1 ){ cout<<"页面号" << cnt_works <<":" ; cin>>x; if (!x){cout<<"输入结束!\n" ;break ;} works[++cnt_works]=x; cout<<works[cnt_works-1 ]<<"\n" ; } return 1 ; } inline int solve_doit () cout<<"置换情况如下:\n" ; int interrupt_cnt = 0 ; for (int i=1 ;i<=cnt_works;++i){ int wk = works[i]; int idx=find_page (wk); printf ("[debug]新作业页面:%d\n" ,wk); if (idx==-1 ){ ++interrupt_cnt; int res = add_page (wk); if (res==1 ){ cout<<"\e[32m[info-int]发生中断,但内存中有空闲区," <<wk<<"号页面直接调入!\e[0m\n" ; } if (res==2 ){ int out_page = st[st_l-1 ]; cout<<"\e[32m[info-int]发生中断,将" <<out_page<<"号页面调出," <<wk<<"号装入!\e[0m\n" ; } }else { cout<<"\e[32m[info]内存中有" <<wk<<"号页面,无须中断!\n\e[0m" ; } print_st (); move_to_top (wk); } double int_p = (1.0 )*(interrupt_cnt)/cnt_works*100.0 ; cout<<"\e[34m【结果】作业:" <<cnt_works<<" 个,中断 " <<interrupt_cnt<<" 次,缺页率:" <<fixed<<setprecision (4 )<< int_p<<"%\e[0m\n" ; return 1 ; } int main () clock_t start = clock (); freopen ("4_big.in" ,"r" ,stdin); init (); solve_rd (); solve_doit (); clock_t end = clock (); double duration = 1.00 *(end - start) / CLOCKS_PER_SEC; cout<<fixed<<setprecision (6 )<<"程序运行时间:" <<duration<<"秒\n" ; }
st速度 1 2 3 4 5 6 7 8 9 【结果】作业:12 个,中断 10 次,缺页率:83.3333% 程序运行时间:0.000156秒 【结果】作业:12 个,中断 8 次,缺页率:66.6667% 程序运行时间:0.000154秒 【结果】作业:9999 个,中断 8932 次,缺页率:89.3289% 程序运行时间:0.057903秒 root@debian: /root/os_exp/_task4
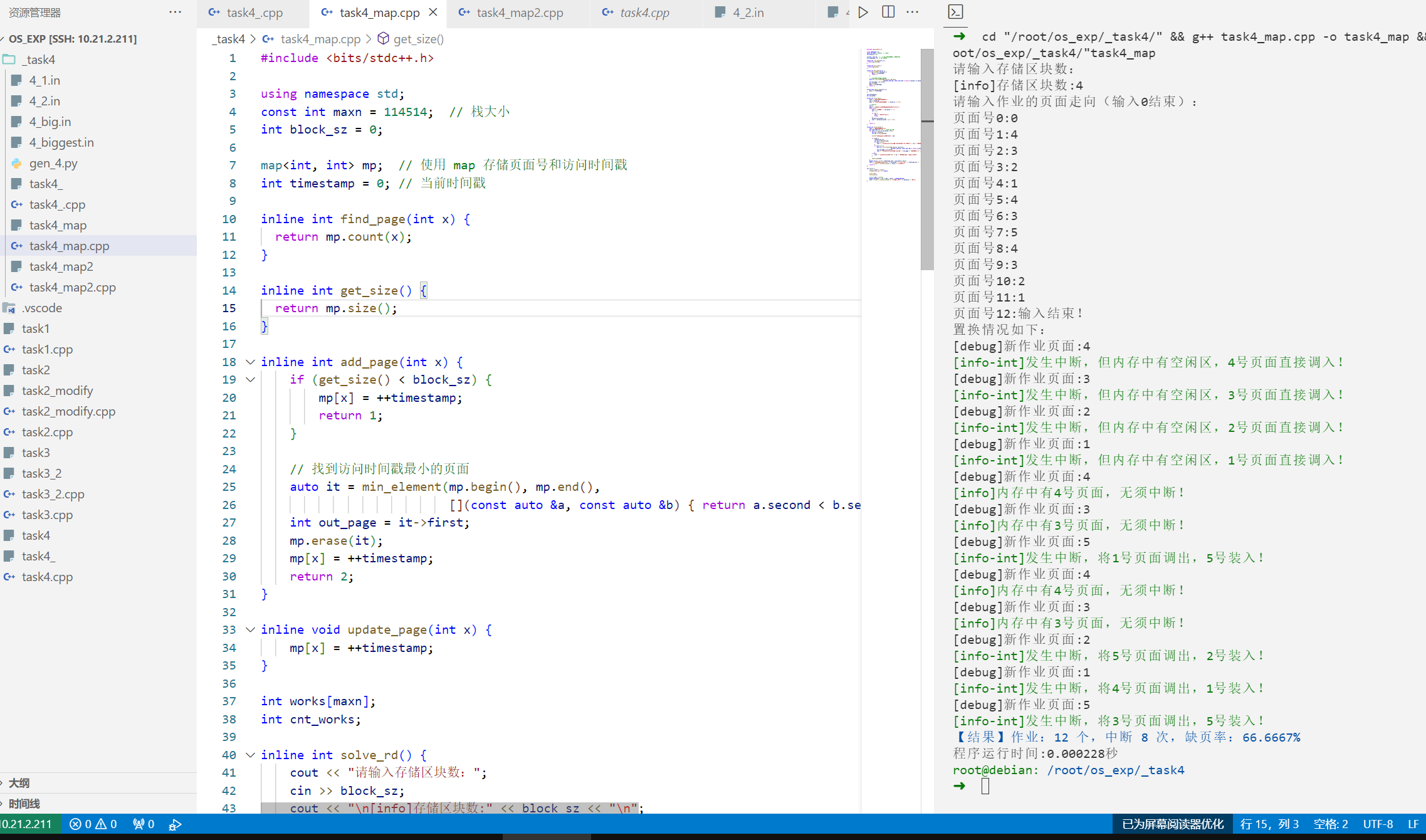
用map优化
$O(logN)$
因为map底层是红黑树,整个过程最麻烦的还是寻找最小值,这样还是$O(N)$的复杂度。但map的底层实现是红黑树,所以如果利用好其排序的话理论应该可以更快。直接用STL的问题就是得需要寻找最小值。
1 2 3 4 5 6 7 8 【结果】作业:12 个,中断 10 次,缺页率:83.3333% 程序运行时间:0.000138秒 【结果】作业:12 个,中断 8 次,缺页率:66.6667% 程序运行时间:0.000228秒 【结果】作业:9999 个,中断 8932 次,缺页率:89.3289% 程序运行时间:0.085279秒
用unordered_map和list
$O(1)$
但是HASH的常数非常大,实际上的效果可能并不如map的$O(N)$的视线,实际也如此,开了O2之后发现实际的执行效率并不高。
1 2 3 4 5 6 7 8 9 【结果】作业:12 个,中断 10 次,缺页率:83.3333% 程序运行时间:0.000141秒 【结果】作业:12 个,中断 8 次,缺页率:66.6667% 程序运行时间:0.000170秒 【结果】作业:9999 个,中断 8932 次,缺页率:89.3289% 程序运行时间:0.070442秒
实际上,这些误差我认为都是常数的问题,而且STL本身有常数,实际上的效率也不是很理想。复杂度是一回事,但是STL里面也蛮慢的。
实验五、FIFO算法模拟 一、实验目的 一个作业有多少个进程,处理机只分配固定的主存页面供该作业执行。往往页面数小于进程数,当请求调页程序调进一个页面时,可能碰到主存中并没有空闲块的情况,此时就产生了在主存中淘汰哪个页面的情况。本实验要求模拟FIFO算法/
二、实验原理 此算法的实质是,总是选择在主存中居留最长时间的页面淘汰。理由是:最早调入主存的页,其不再被访问的可能性最大。
代码: 跟上个实验一样的,但是维护起来要简单很多,先进先出,直接用队列维护就可以。
实现的话:
当需要将一个新的页面装入内存时,先遍历队列,看是否有相等的页号或空位置。
如果找到相等的页号,说明页面已经在内存中,不需要置换。
如果找到空位置,就将新页面装入这个位置。
如果没有找到相等的页号也没有空位置,最先进入的页面移出,并将新页面添加到数组的最后。
实现起来就比较简单了
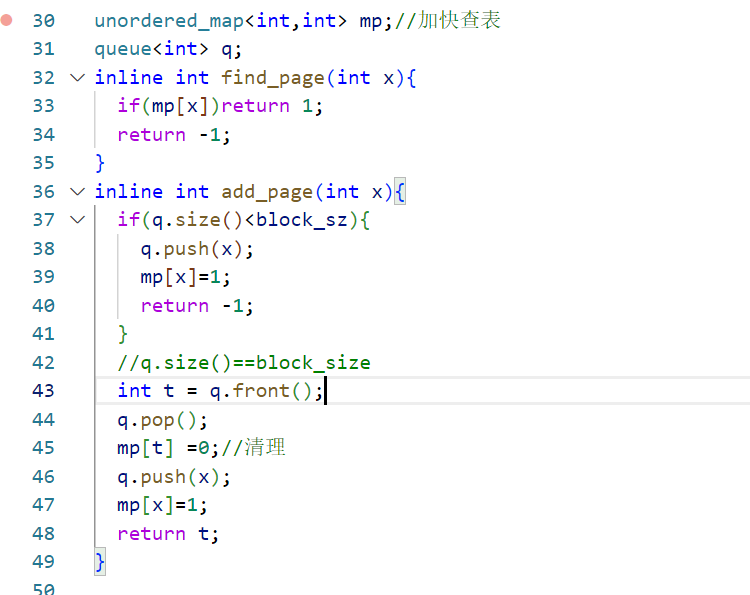
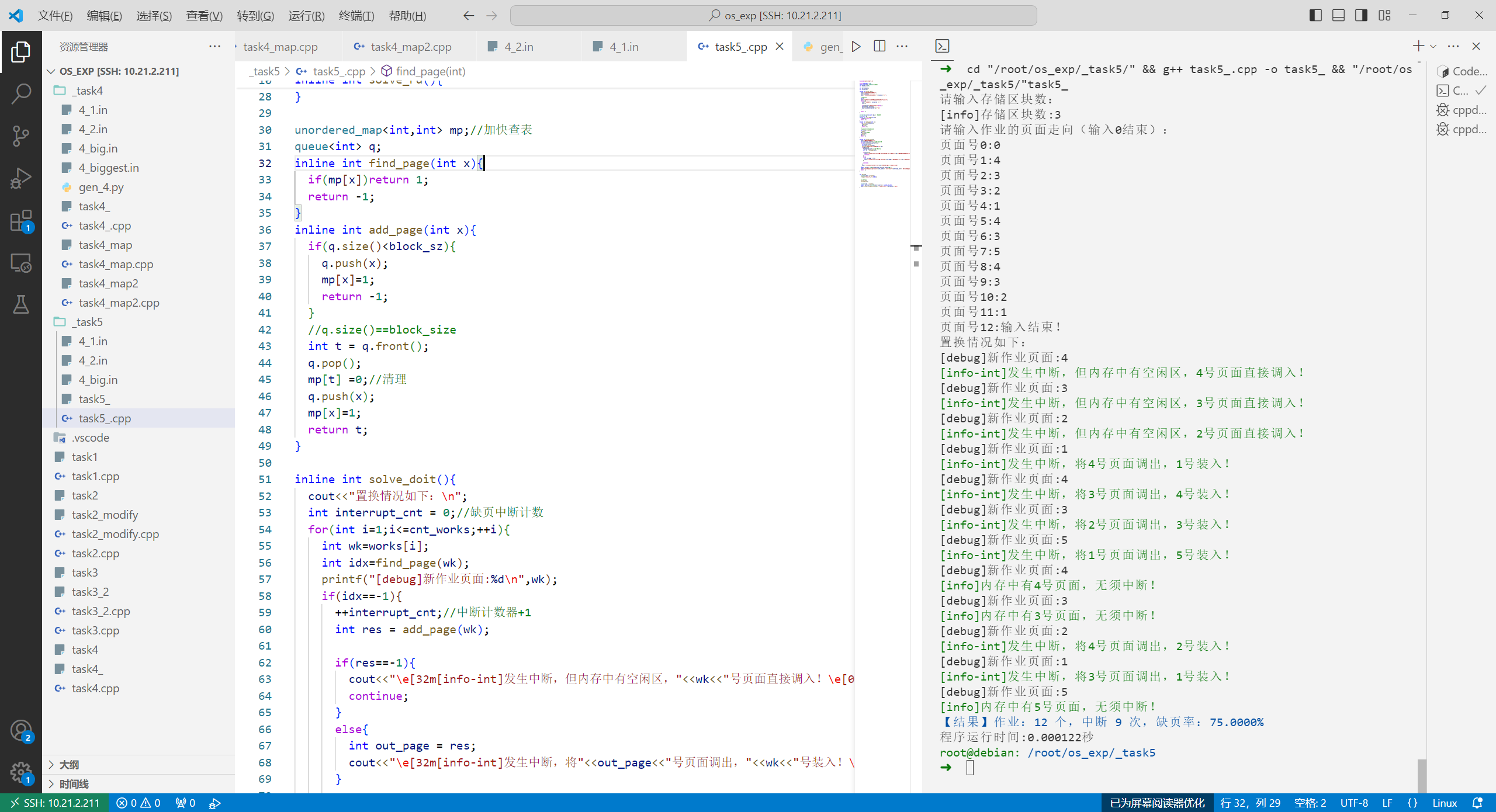
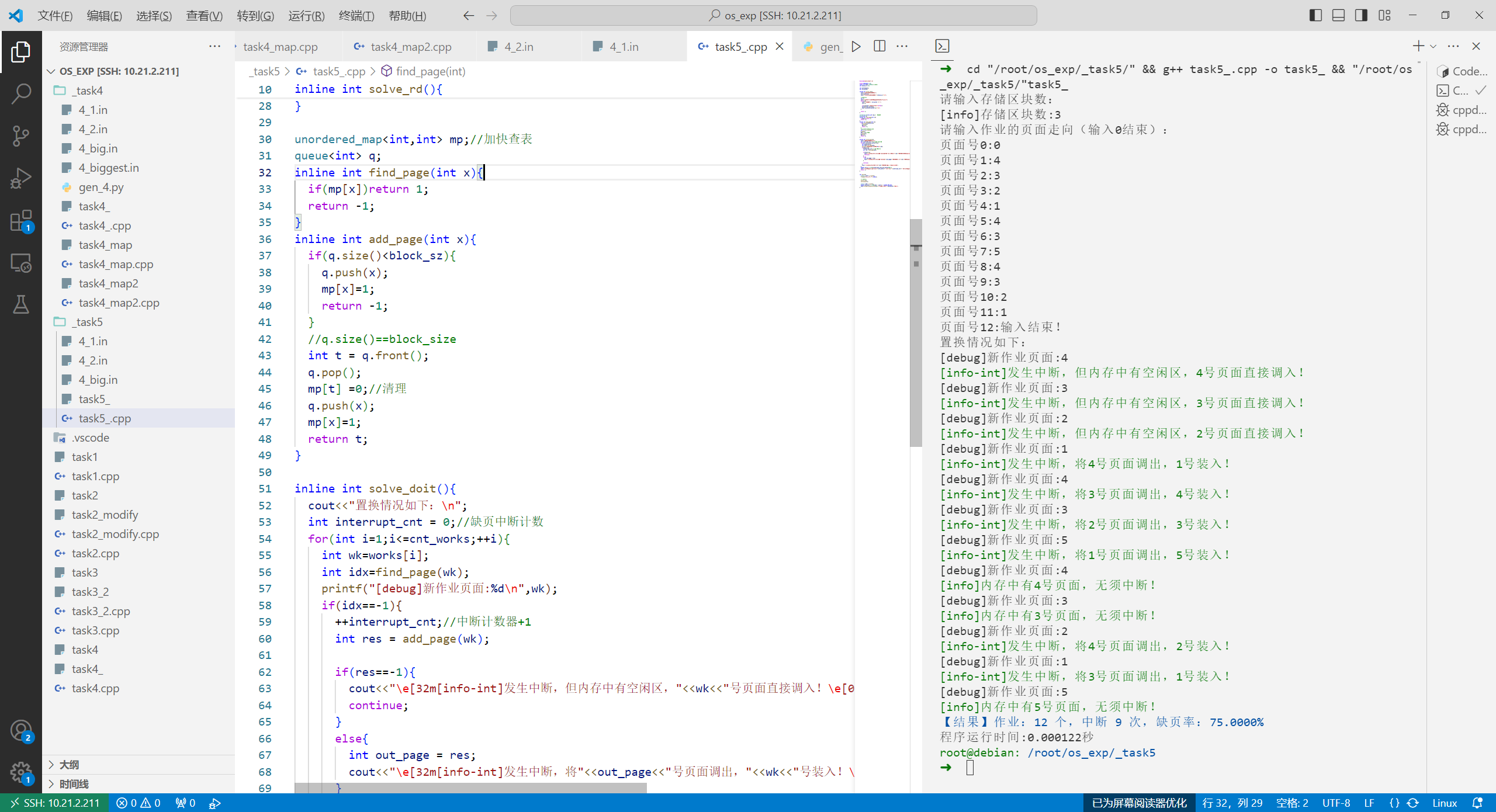
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 #include <bits/stdc++.h> using namespace std;const int maxn= 114514 ;int block_sz = 0 ;int works[maxn];int cnt_works;inline int solve_rd () cout<<"请输入存储区块数:" ; cin>>block_sz; cout<<"\n[info]存储区块数:" <<block_sz<<"\n" ; int x; cout<<"请输入作业的页面走向(输入0结束):\n" ; while (1 ){ cout<<"页面号" << cnt_works <<":" ; cin>>x; if (!x){cout<<"输入结束!\n" ;break ;} works[++cnt_works]=x; cout<<works[cnt_works-1 ]<<"\n" ; } return 1 ; } unordered_map<int ,int > mp; queue<int > q; inline int find_page (int x) if (mp[x])return 1 ; return -1 ; } inline int add_page (int x) if (q.size ()<block_sz){ q.push (x); mp[x]=1 ; return -1 ; } int t = q.front (); q.pop (); mp[t] =0 ; q.push (x); mp[x]=1 ; return t; } inline int solve_doit () cout<<"置换情况如下:\n" ; int interrupt_cnt = 0 ; for (int i=1 ;i<=cnt_works;++i){ int wk=works[i]; int idx=find_page (wk); printf ("[debug]新作业页面:%d\n" ,wk); if (idx==-1 ){ ++interrupt_cnt; int res = add_page (wk); if (res==-1 ){ cout<<"\e[32m[info-int]发生中断,但内存中有空闲区," <<wk<<"号页面直接调入!\e[0m\n" ; continue ; } else { int out_page = res; cout<<"\e[32m[info-int]发生中断,将" <<out_page<<"号页面调出," <<wk<<"号装入!\e[0m\n" ; } continue ; } cout<<"\e[32m[info]内存中有" <<wk<<"号页面,无须中断!\n\e[0m" ; } double int_p = (1.0 )*(interrupt_cnt)/cnt_works*100.0 ; cout<<"\e[34m【结果】作业:" <<cnt_works<<" 个,中断 " <<interrupt_cnt<<" 次,缺页率:" <<fixed<<setprecision (4 )<< int_p<<"%\e[0m\n" ; return 1 ; } int main () clock_t start = clock (); freopen ("4_1.in" ,"r" ,stdin); solve_rd (); solve_doit (); clock_t end = clock (); double duration = 1.00 *(end - start) / CLOCKS_PER_SEC; cout<<fixed<<setprecision (6 )<<"程序运行时间:" <<duration<<"秒\n" ; }
执行结果: 4_1.in 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 ➜ cd "/root/os_exp/_task5/" && g++ task5_.cpp -o task5_ && "/root/os _exp/_task5/" task5_请输入存储区块数: [info]存储区块数:3 请输入作业的页面走向(输入0结束): 页面号0:0 页面号1:4 页面号2:3 页面号3:2 页面号4:1 页面号5:4 页面号6:3 页面号7:5 页面号8:4 页面号9:3 页面号10:2 页面号11:1 页面号12:输入结束! 置换情况如下: [debug]新作业页面:4 [info-int]发生中断,但内存中有空闲区,4号页面直接调入! [debug]新作业页面:3 [info-int]发生中断,但内存中有空闲区,3号页面直接调入! [debug]新作业页面:2 [info-int]发生中断,但内存中有空闲区,2号页面直接调入! [debug]新作业页面:1 [info-int]发生中断,将4号页面调出,1号装入! [debug]新作业页面:4 [info-int]发生中断,将3号页面调出,4号装入! [debug]新作业页面:3 [info-int]发生中断,将2号页面调出,3号装入! [debug]新作业页面:5 [info-int]发生中断,将1号页面调出,5号装入! [debug]新作业页面:4 [info]内存中有4号页面,无须中断! [debug]新作业页面:3 [info]内存中有3号页面,无须中断! [debug]新作业页面:2 [info-int]发生中断,将4号页面调出,2号装入! [debug]新作业页面:1 [info-int]发生中断,将3号页面调出,1号装入! [debug]新作业页面:5 [info]内存中有5号页面,无须中断! 【结果】作业:12 个,中断 9 次,缺页率:75.0000% 程序运行时间:0.000195秒
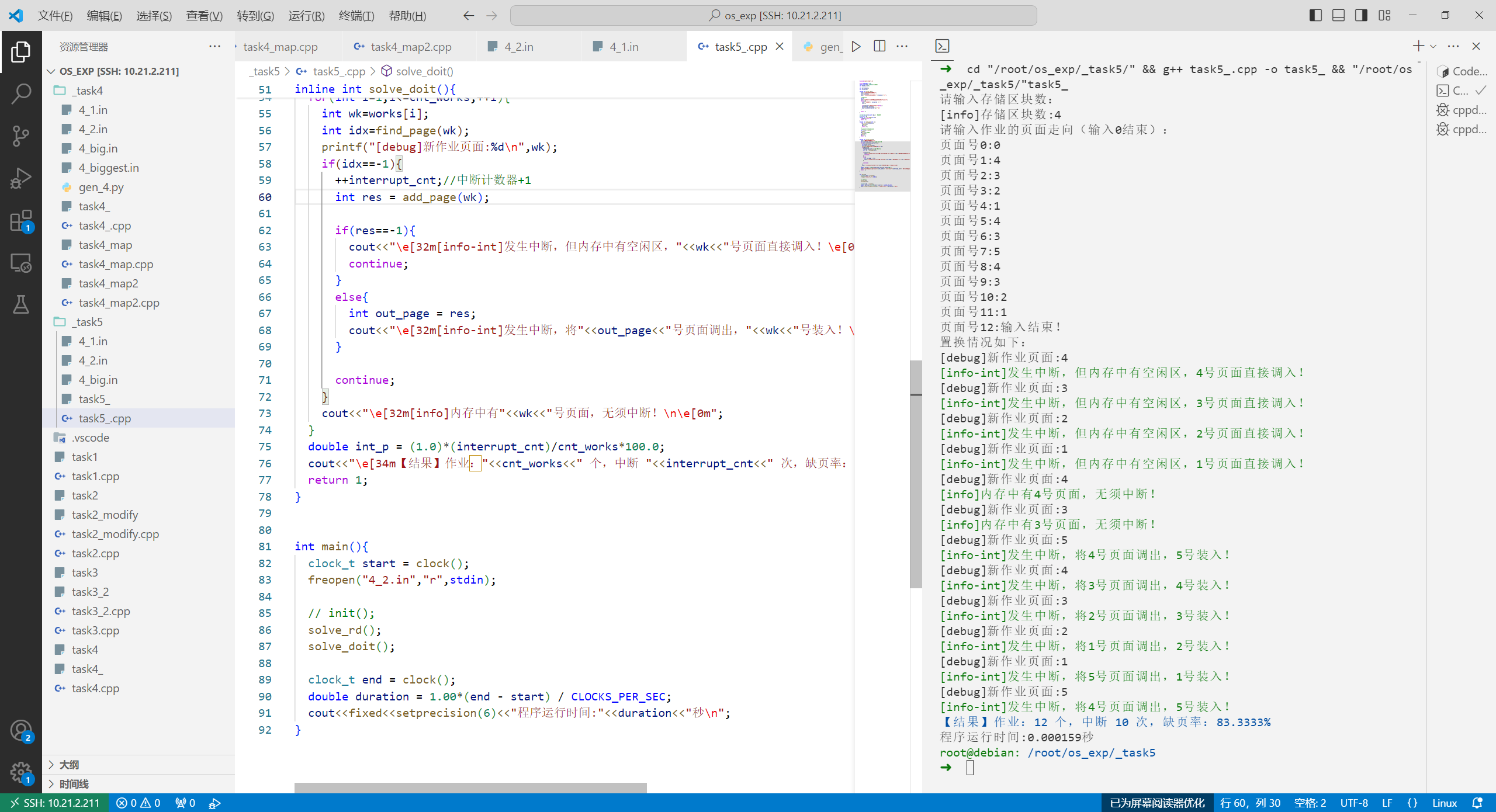
4_2.in 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 请输入存储区块数: [info]存储区块数:4 请输入作业的页面走向(输入0结束): 页面号0:0 页面号1:4 页面号2:3 页面号3:2 页面号4:1 页面号5:4 页面号6:3 页面号7:5 页面号8:4 页面号9:3 页面号10:2 页面号11:1 页面号12:输入结束! 置换情况如下: [debug]新作业页面:4 [info-int]发生中断,但内存中有空闲区,4号页面直接调入! [debug]新作业页面:3 [info-int]发生中断,但内存中有空闲区,3号页面直接调入! [debug]新作业页面:2 [info-int]发生中断,但内存中有空闲区,2号页面直接调入! [debug]新作业页面:1 [info-int]发生中断,但内存中有空闲区,1号页面直接调入! [debug]新作业页面:4 [info]内存中有4号页面,无须中断! [debug]新作业页面:3 [info]内存中有3号页面,无须中断! [debug]新作业页面:5 [info-int]发生中断,将4号页面调出,5号装入! [debug]新作业页面:4 [info-int]发生中断,将3号页面调出,4号装入! [debug]新作业页面:3 [info-int]发生中断,将2号页面调出,3号装入! [debug]新作业页面:2 [info-int]发生中断,将1号页面调出,2号装入! [debug]新作业页面:1 [info-int]发生中断,将5号页面调出,1号装入! [debug]新作业页面:5 [info-int]发生中断,将4号页面调出,5号装入! 【结果】作业:12 个,中断 10 次,缺页率:83.3333% 程序运行时间:0.000159秒 root@debian: /root/os_exp/_task5
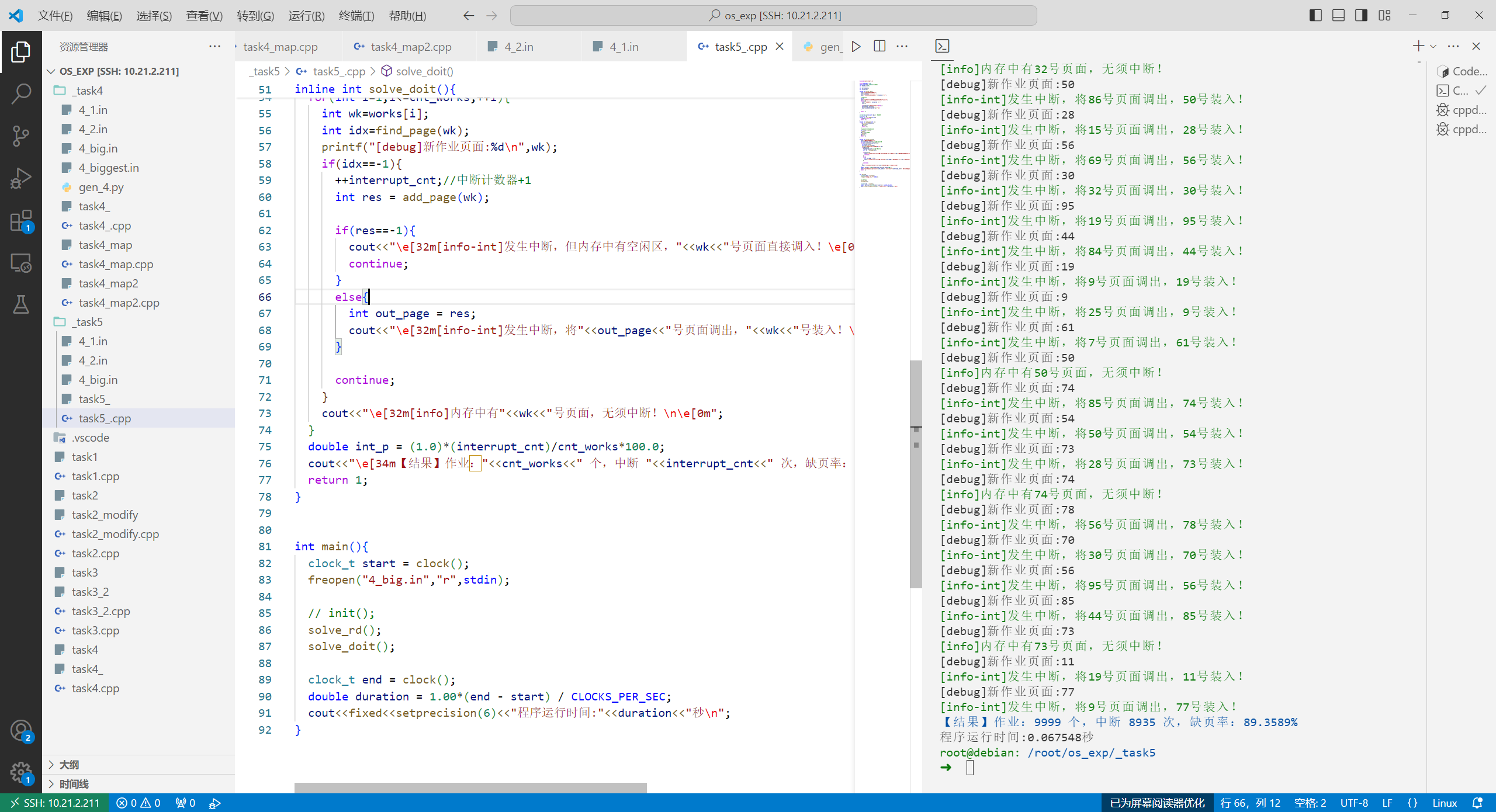
4_big.in 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [debug]新作业页面:74 [info]内存中有74号页面,无须中断! [debug]新作业页面:78 [info-int]发生中断,将56号页面调出,78号装入! [debug]新作业页面:70 [info-int]发生中断,将30号页面调出,70号装入! [debug]新作业页面:56 [info-int]发生中断,将95号页面调出,56号装入! [debug]新作业页面:85 [info-int]发生中断,将44号页面调出,85号装入! [debug]新作业页面:73 [info]内存中有73号页面,无须中断! [debug]新作业页面:11 [info-int]发生中断,将19号页面调出,11号装入! [debug]新作业页面:77 [info-int]发生中断,将9号页面调出,77号装入! 【结果】作业:9999 个,中断 8935 次,缺页率:89.3589% 程序运行时间:0.067548秒
实验六:Linux环境下:实验一 进程控制 一、实验目的: 加深对进程概念的理解,明确进程和程序的区别;掌握Linux操作系统的进程创建和终止操作,体会父进程和子进程的关系及进程状态的变化,及子进程共享父进程资源;进一步认识并发执行的实质,编写并发程序。
二、实验平台: 虚拟机:VMWare 12
1 2 3 4 5 6 7 8 9 OS: Debian GNU/Linux 12 (bookworm) x86_64 Host: VMware Virtual Platform None root@debian: /root/os_exp/_task5 ➜ gcc --version gcc (Debian 12.2.0-14) 12.2.0 Copyright (C) 2022 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
三、实验内容: (1)编写一段程序,使用系统调用fork()创建两个子进程,当此程序运行时,在系统中有一个父进程和两个子进程活动。让每一个进程在屏幕上显示“身份信息”:父进程显示“Parent process! PID=xxx1 PPID=xxx2”;子进程显示“Childx process! PID=xxx PPID=xxx”。多运行几次,观察记录屏幕上的显示结果,并分析原因。 说明:
xxx1为进程号,用getpid()函数可获取进程号;
xxx2为父进程号,用getppid()函数可获取父进程号;
Childx中x为1和2,用来区别两个子进程;
wait()函数用来避免父进程在子进程终止之前终止。
(2)fork()函数:仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
在父进程中,fork返回新创建子进程的进程ID;
在子进程中,fork返回0;
如果出现错误,fork返回一个负值。
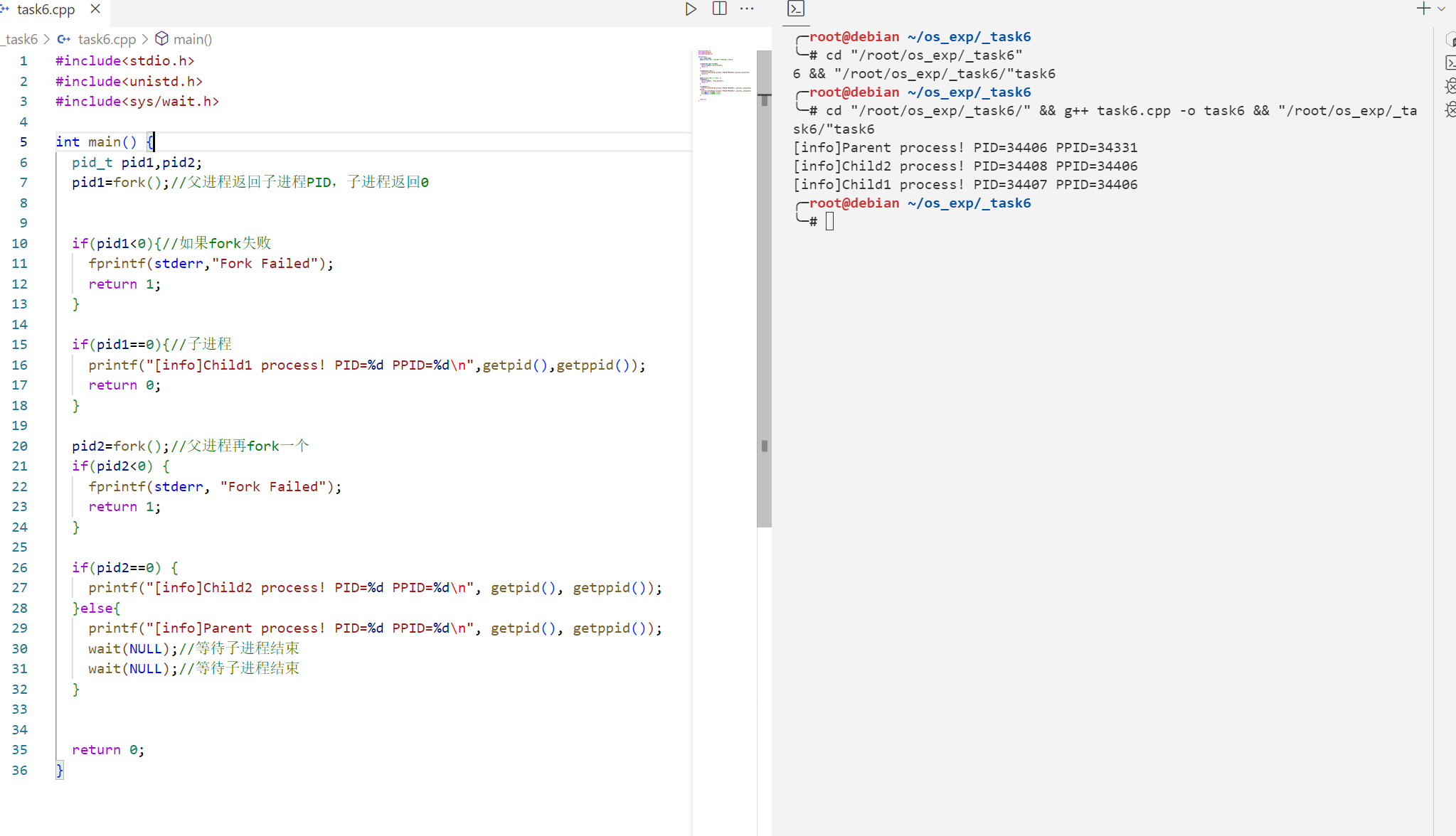
(3)程序源码: fork之后会是产生完全一样的两个进程,但是对于程序的返回值不一样。
fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
题目要求代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <stdio.h> #include <unistd.h> #include <sys/wait.h> int main () pid_t pid1,pid2; pid1=fork(); if (pid1<0 ){ fprintf (stderr,"Fork Failed" ); return 1 ; } if (pid1==0 ){ printf ("[info]Child1 process! PID=%d PPID=%d\n" ,getpid (),getppid ()); return 0 ; } pid2=fork(); if (pid2<0 ) { fprintf (stderr, "Fork Failed" ); return 1 ; } if (pid2==0 ) { printf ("[info]Child2 process! PID=%d PPID=%d\n" , getpid (), getppid ()); }else { printf ("[info]Parent process! PID=%d PPID=%d\n" , getpid (), getppid ()); wait (NULL ); wait (NULL ); } return 0 ; }
运行结果
1 2 3 4 5 ╰─ sk6/"task6 [info]Parent process! PID=34406 PPID=34331 [info]Child2 process! PID=34408 PPID=34406 [info]Child1 process! PID=34407 PPID=34406
实验报告提供代码: 稍微改了下printf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <stdio.h> #include <stdlib.h> #include <sys/wait.h> #include <unistd.h> int main (void ) pid_t pid1, pid2; int count = 0 ; if ((pid1 = fork()) < 0 ) { printf ("创建进程1失败" ); } else { if (pid1 == 0 ) { printf ("[info-child1]Child1 process: " ); printf ("PID=%d PPID=%d \n" , getpid (), getppid ()); count++; printf ("[info-child1]count=%d\n" , count); sleep (2 ); } else { if ((pid2 = fork()) < 0 ) { printf ("创建进程2失败" ); } else { if (pid2 == 0 ) { printf ("[info-child2]Child2 process: " ); printf ("PID=%d PPID=%d \n" , getpid (), getppid ()); count++; printf ("[info-child2]count=%d\n" , count); } else { wait (0 ); wait (0 ); printf ("[info-fa]Parent process: " ); printf ("PID=%d PPID=%d \n" , getpid (), getppid ()); count++; printf ("[info-fa]count=%d\n" , count); exit (0 ); } } } } }
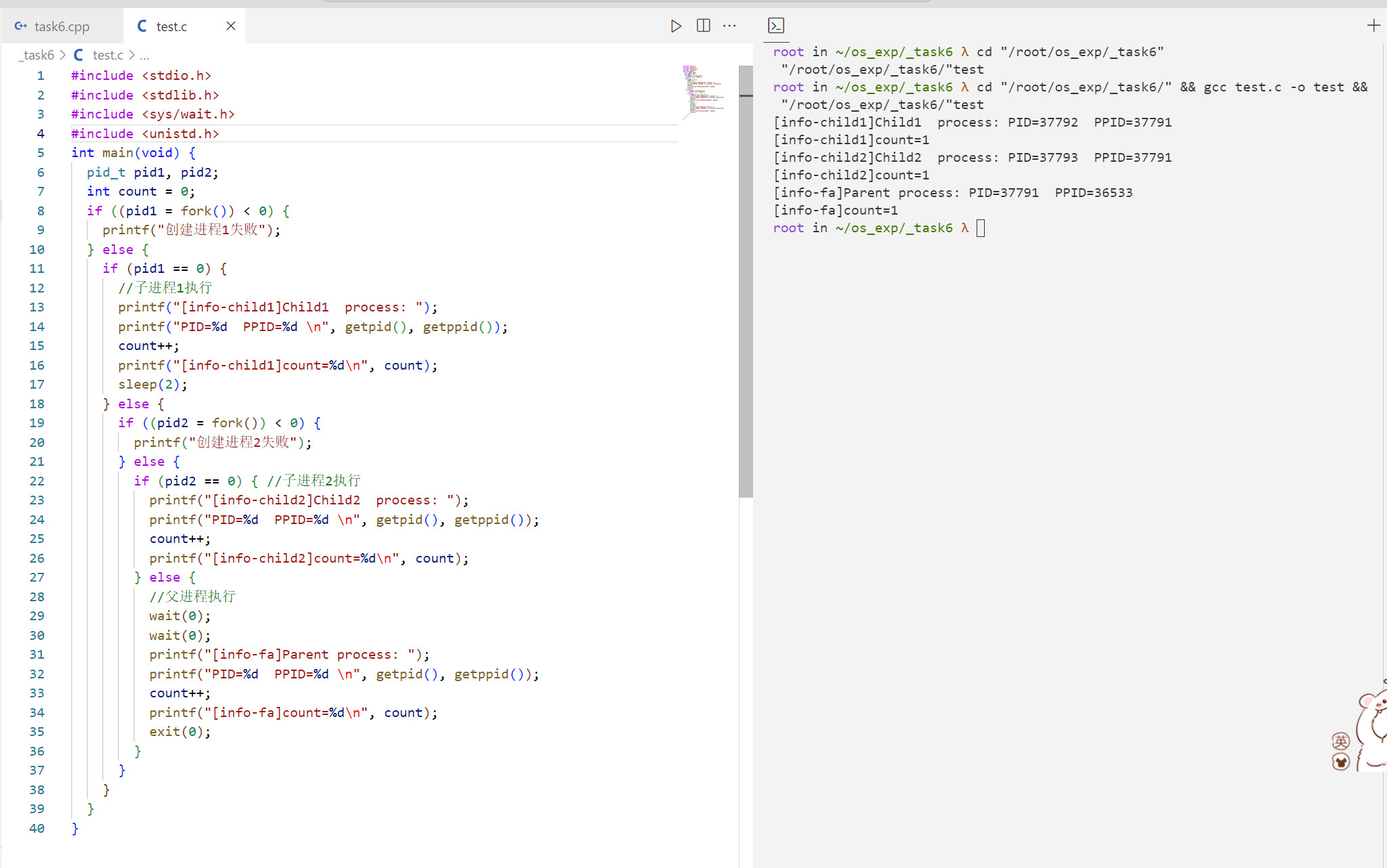
输出
1 2 3 4 5 6 7 8 root in ~/os_exp/_task6 λ cd "/root/os_exp/_task6/" && gcc test.c -o test && "/root/os_exp/_task6/" test [info-child1]Child1 process: PID=37792 PPID=37791 [info-child1]count=1 [info-child2]Child2 process: PID=37793 PPID=37791 [info-child2]count=1 [info-fa]Parent process: PID=37791 PPID=36533 [info-fa]count=1
都是1,因为第一次fork的时候,复制变量就是count=0,子进程复制出来也是count=0,然后进行++再输出就是1了。第二次复制的时候父进程还是count=0,再++就是1。
四、回答问题: (1)分析运行结果中count的值。 可以看到每个进程的count值都是1。
父进程中count初始值为0。当fork()创建子进程1时,子进程1复制了父进程的数据空间,所以子进程1中的count初始值也为0。然后子进程1将count++后输出,child1进程的count值为1。
在fork()子进程2之前,父进程中的count仍为0(因为fork()是复制父进程的数据空间,父进程中的count没有改变)。所以fork()之后,子进程2中的count初始值也为0。子进程2将count++后输出,所以child2进程的count值为1。
父进程等待两个子进程结束后,将自己的count++,所以parent进程的count值也为1。虽然最后三个进程的count值都是1,但是实际上每个进程的count值都是独立的,互不影响。这正是fork()的特点:
fork()被调用一次,但返回两次。在父进程中返回新创建的子进程的PID,在子进程中返回0。这样就可以区分父子进程。
子进程是父进程的副本,它将获得父进程的数据空间、堆、栈等资源的副本。但是父子进程并不共享这些存储空间部分。
父子进程共享正文段,因为正文段是只读的。
所以通过fork()创建的子进程,它们的运行环境、变量值等一开始都与父进程相同,但是后续的修改互不影响。每个进程有自己独立的数据空间。因此会出现三个count=1
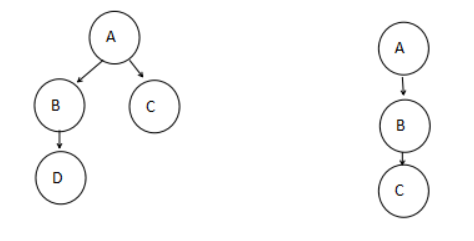
(2)编写程序,创建进程如下图
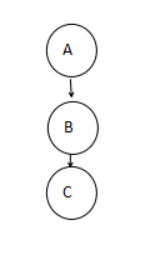
第一个图: A—>B
B->D
总共是4个进程
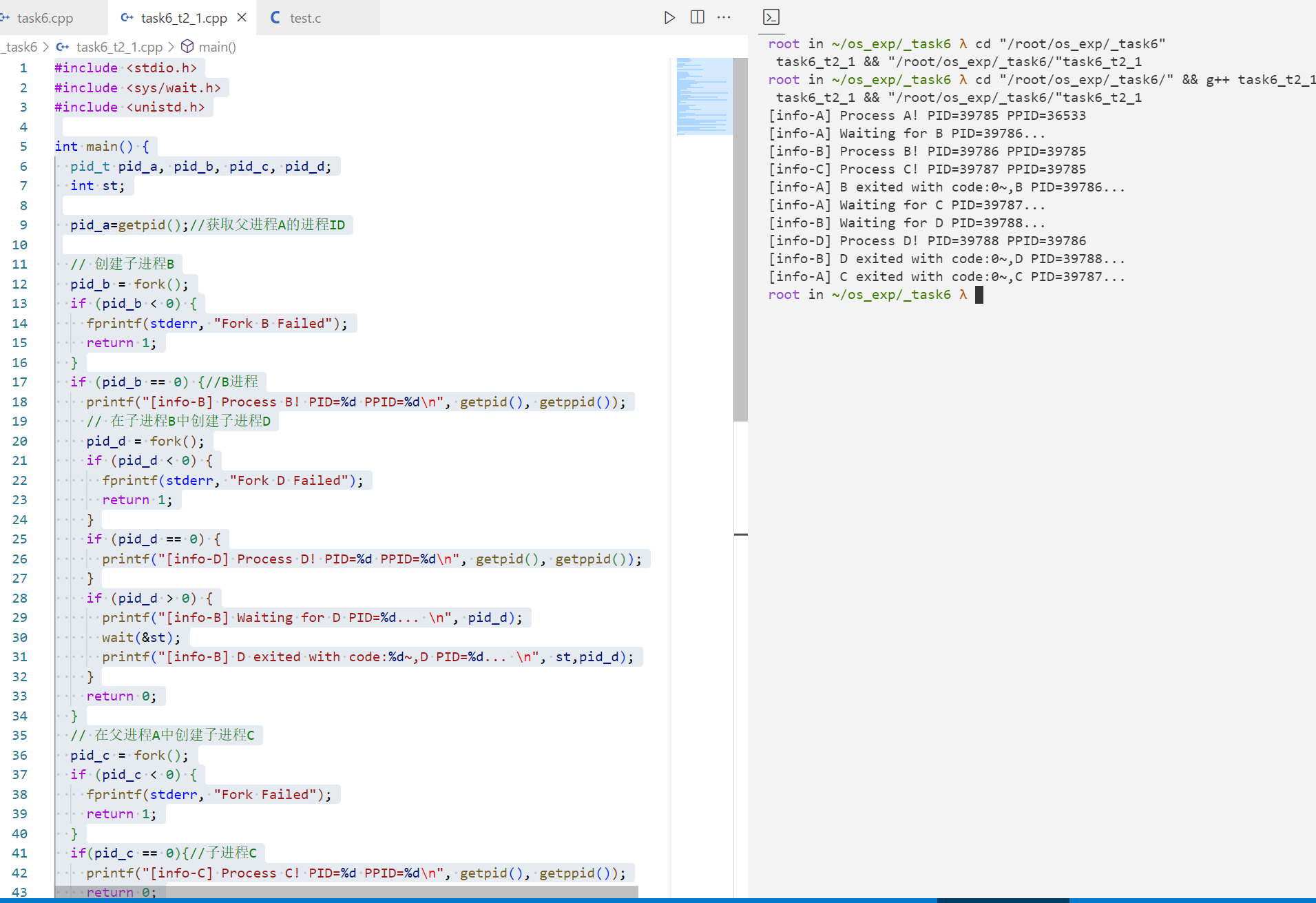
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <stdio.h> #include <sys/wait.h> #include <unistd.h> int main () pid_t pid_a, pid_b, pid_c, pid_d; int st; pid_a=getpid (); pid_b = fork(); if (pid_b < 0 ) { fprintf (stderr, "Fork B Failed" ); return 1 ; } if (pid_b == 0 ) { printf ("[info-B] Process B! PID=%d PPID=%d\n" , getpid (), getppid ()); pid_d = fork(); if (pid_d < 0 ) { fprintf (stderr, "Fork D Failed" ); return 1 ; } if (pid_d == 0 ) { printf ("[info-D] Process D! PID=%d PPID=%d\n" , getpid (), getppid ()); } if (pid_d > 0 ) { printf ("[info-B] Waiting for D PID=%d... \n" , pid_d); wait (&st); printf ("[info-B] D exited with code:%d~,D PID=%d... \n" , st,pid_d); } return 0 ; } pid_c = fork(); if (pid_c < 0 ) { fprintf (stderr, "Fork Failed" ); return 1 ; } if (pid_c == 0 ){ printf ("[info-C] Process C! PID=%d PPID=%d\n" , getpid (), getppid ()); return 0 ; } if (pid_a == getpid ()) { printf ("[info-A] Process A! PID=%d PPID=%d\n" , getpid (), getppid ()); printf ("[info-A] Waiting for B PID=%d... \n" , pid_b); wait (&st); printf ("[info-A] B exited with code:%d~,B PID=%d... \n" , st,pid_b); printf ("[info-A] Waiting for C PID=%d... \n" , pid_c); wait (&st); printf ("[info-A] C exited with code:%d~,C PID=%d... \n" , st,pid_c); } return 0 ; }
输出 1 2 3 4 5 6 7 8 9 10 11 12 13 root in ~/os_exp/_task6 λ cd "/root/os_exp/_task6/" && g++ task6_t2_1.cpp -o task6_t2_1 && "/root/os_exp/_task6/" task6_t2_1 [info-A] Process A! PID=39785 PPID=36533 [info-A] Waiting for B PID=39786... [info-B] Process B! PID=39786 PPID=39785 [info-C] Process C! PID=39787 PPID=39785 [info-A] B exited with code:0~,B PID=39786... [info-A] Waiting for C PID=39787... [info-B] Waiting for D PID=39788... [info-D] Process D! PID=39788 PPID=39786 [info-B] D exited with code:0~,D PID=39788... [info-A] C exited with code:0~,C PID=39787... root in ~/os_exp/_task6 λ
标注一下: 1 2 3 4 5 6 7 8 9 10 11 12 13 root in ~/os_exp/_task6 λ cd "/root/os_exp/_task6/" && g++ task6_t2_1.cpp -o task6_t2_1 && "/root/os_exp/_task6/" task6_t2_1 [info-A] Process A! PID=39785 PPID=36533 [info-A] Waiting for B PID=39786... [info-B] Process B! PID=39786 PPID=39785(A) [info-C] Process C! PID=39787 PPID=39785(A) [info-A] B exited with code:0~,B PID=39786(B)... [info-A] Waiting for C PID=39787... [info-B] Waiting for D PID=39788... [info-D] Process D! PID=39788 PPID=39786(B) [info-B] D exited with code:0~,D PID=39788... [info-A] C exited with code:0~,C PID=39787... root in ~/os_exp/_task6 λ
拓扑图 1 2 3 4 5 6 7 8 9 A (PID=39785) / \ / \ B C (PID=39786) (PID=39787) | | D (PID=39788)
第二个图:
代码: 稍微一改即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <stdio.h> #include <sys/wait.h> #include <unistd.h> int main () pid_t pid_a, pid_b, pid_c; int st; pid_a=getpid (); pid_b = fork(); if (pid_b < 0 ) { fprintf (stderr, "Fork B Failed" ); return 1 ; } if (pid_b == 0 ) { printf ("[info-B] Process B! PID=%d PPID=%d\n" , getpid (), getppid ()); pid_c = fork(); if (pid_c < 0 ) { fprintf (stderr, "Fork C Failed" ); return 1 ; } if (pid_c == 0 ) { printf ("[info-C] Process C! PID=%d PPID=%d\n" , getpid (), getppid ()); } if (pid_c > 0 ) { printf ("[info-B] Waiting for C PID=%d... \n" , pid_c); wait (&st); printf ("[info-B] C exited with code:%d~,C PID=%d... \n" , st,pid_c); } return 0 ; } if (pid_a == getpid ()) { printf ("[info-A] Process A! PID=%d PPID=%d\n" , getpid (), getppid ()); printf ("[info-A] Waiting for B PID=%d... \n" , pid_b); wait (&st); printf ("[info-A] B exited with code:%d~,B PID=%d... \n" , st,pid_b); } return 0 ; }
输出 1 2 3 4 5 6 7 8 9 10 root in ~/os_exp/_task6 λ cd "/root/os_exp/_task6/" && g++ task6_t2_2.cpp -o task6_t2_2 && "/root/os_exp/_task6/" task6_t2_2 [info-A] Process A! PID=40298 PPID=36533 [info-A] Waiting for B PID=40299... [info-B] Process B! PID=40299 PPID=40298 [info-B] Waiting for C PID=40300... [info-C] Process C! PID=40300 PPID=40299 [info-B] C exited with code:0~,C PID=40300... [info-A] B exited with code:0~,B PID=40299... root in ~/os_exp/_task6 λ
拓扑图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 +----------+ | PPID= | | 36533 | +----------+ | +----------+ | PID= | | 40298 (A)| +----------+ | +----------+ | PID= | | 40299 (B)| +----------+ | +----------+ | PID= | | 40300 (C)| +----------+
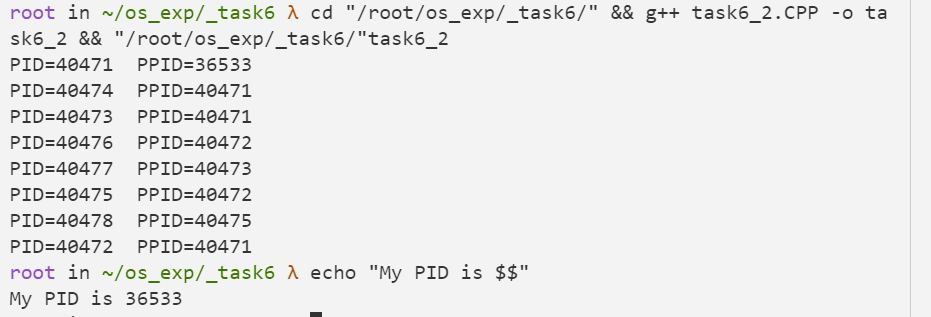
(3)运行如下程序,并分析结果 #include<stdio.h>
运行结果: 1 2 3 4 5 6 7 8 9 10 11 root in ~/os_exp/_task6 λ cd "/root/os_exp/_task6/" && g++ task6_2.CPP -o ta sk6_2 && "/root/os_exp/_task6/" task6_2 PID=40471 PPID=36533 PID=40474 PPID=40471 PID=40473 PPID=40471 PID=40476 PPID=40472 PID=40477 PPID=40473 PID=40475 PPID=40472 PID=40478 PPID=40475 PID=40472 PPID=40471
拓扑结构 1 2 3 4 5 6 7 8 9 +-- PID=40471 (PPID=36533) | +-- PID=40472 (PPID=40471) | | +-- PID=40475 (PPID=40472) | | | +-- PID=40478 (PPID=40475) | | +-- PID=40476 (PPID=40472) | +-- PID=40473 (PPID=40471) | | +-- PID=40477 (PPID=40473) | +-- PID=40474 (PPID=40471)
分析 利用 fork() 创建了多个进程。fork() 函数每调用一次,就会复制当前进程,创建一个新的子进程。在程序中,fork() 被调用三次,所以理论上会创建 $2^3 = 8$ 个进程。PID=40471是原始进程,后面每一级的进程都是由其父进程通过调用 fork() 创建的。
程序通过调用 fork() 函数创建了多个子进程。每次调用 fork() 都会创建一个新的子进程,子进程继承父进程的代码并从 fork() 函数调用处开始执行。
程序中连续调用了三次 fork(),这将导致进程数量呈指数级增长。具体的:
假设初始进程为 P:
第一次 fork() 将创建一个子进程 C1,此时有 2 个进程:P 和 C1。
第二次 fork() 在 P 和 C1 中分别执行,将创建两个新的子进程 C2 和 C3,此时有 4 个进程:P、C1、C2 和 C3。
第三次 fork() 在这 4 个进程中分别执行,将创建 4 个新的子进程 C4、C5、C6 和 C7,最终共有 8 个进程。
每个进程都会执行 printf() 语句,打印出自己的进程 ID(PID)和父进程 ID(PPID)。
根据输出结果,可以推断出进程之间的父子关系:
PID 为 40471 的进程是初始进程 P,其父进程 ID 为 36533(可能是 shell 进程)。
PID 为 40472、40473 和 40474 的进程是 P 的子进程,它们的父进程 ID 都是 40471。
PID 为 40475 和 40476 的进程是 40472 的子进程,它们的父进程 ID 都是 40472。
PID 为 40477 的进程是 40473 的子进程,其父进程 ID 为 40473。
PID 为 40478 的进程是 40475 的子进程,其父进程 ID 为 40475。
程序通过连续调用 fork() 创建了一个进程树,共有 8 个进程,它们之间存在父子关系。每个进程都会打印出自己的 PID 和 PPID,并休眠 3 秒钟。
实验7:Linux环境下:实验二 进程的管道通信 一、实验目的: (1)加深对进程概念的理解,明确进程和程序的区别;
二、实验内容及要求: (1)使用系统调用pipe()建立一条管道线,两个子进程分别向管道写一句话(写的内容自己定,但要有该进程的一些信息);
三、实现: 相关的系统调用
wait() 常用来控制父进程与子进程的同步。
exit() 是进程结束时最常调用的。
pipe() 用于创建一个管道
sleep() 使调用进程睡眠若干时间,之后唤醒。
lockf() 用于对互斥资源加锁和解锁。在本实验中该调用的格式为:
write(fd[1],String,Length) 将字符串String的内容写入 管道的写入口。
read(fd[0],String,Length) 从管道的读入口读出信息放入字符串String中。
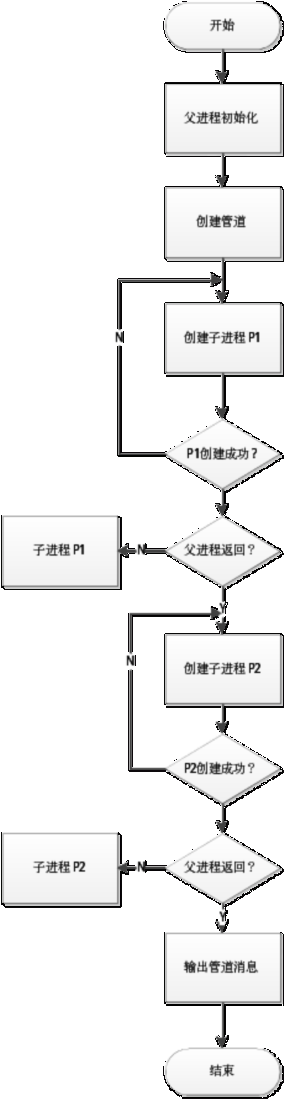
程序流程图 图1 父进程流程图:
图2 子进程P1流程图:
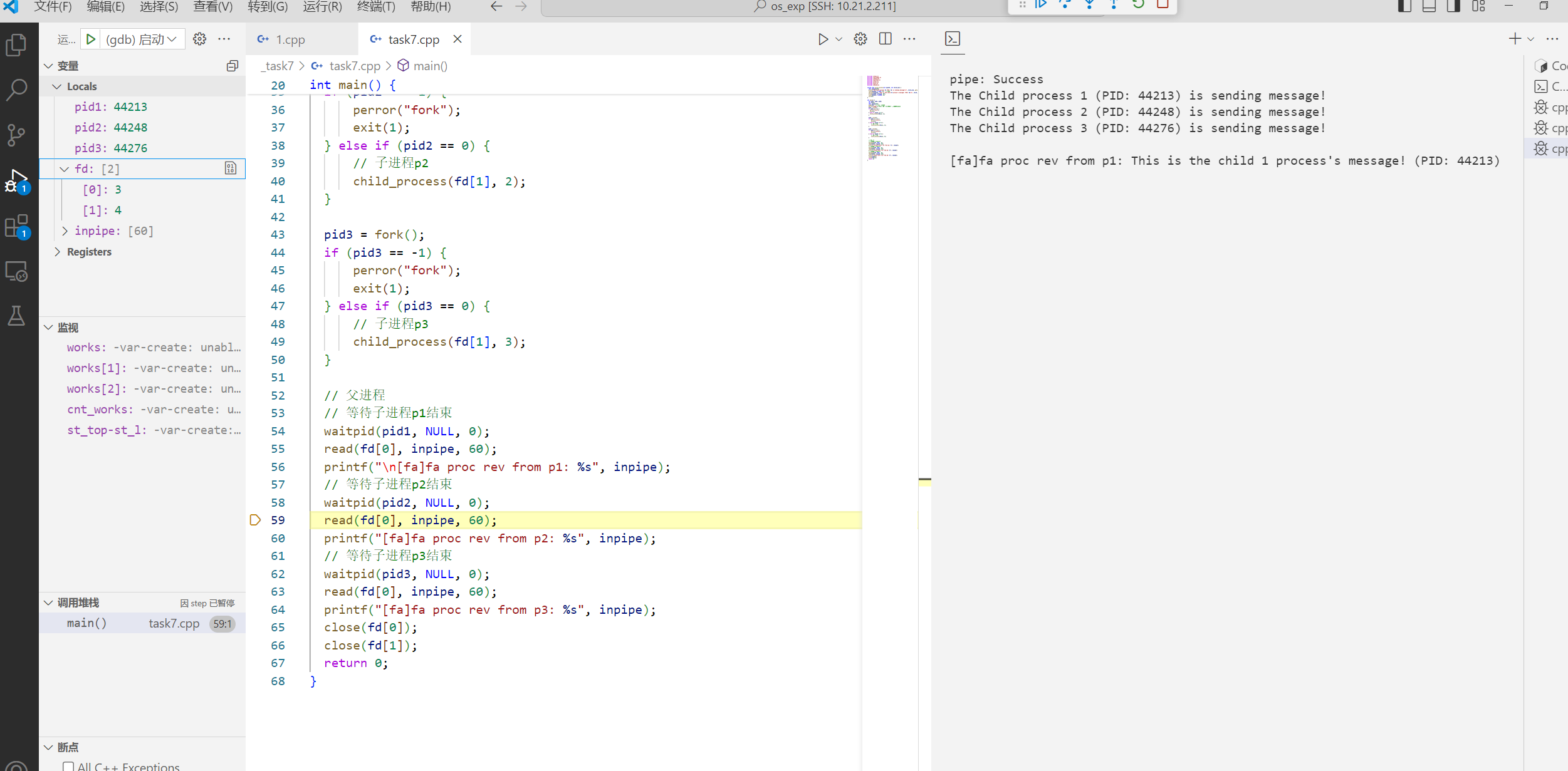
四、运行结果及说明
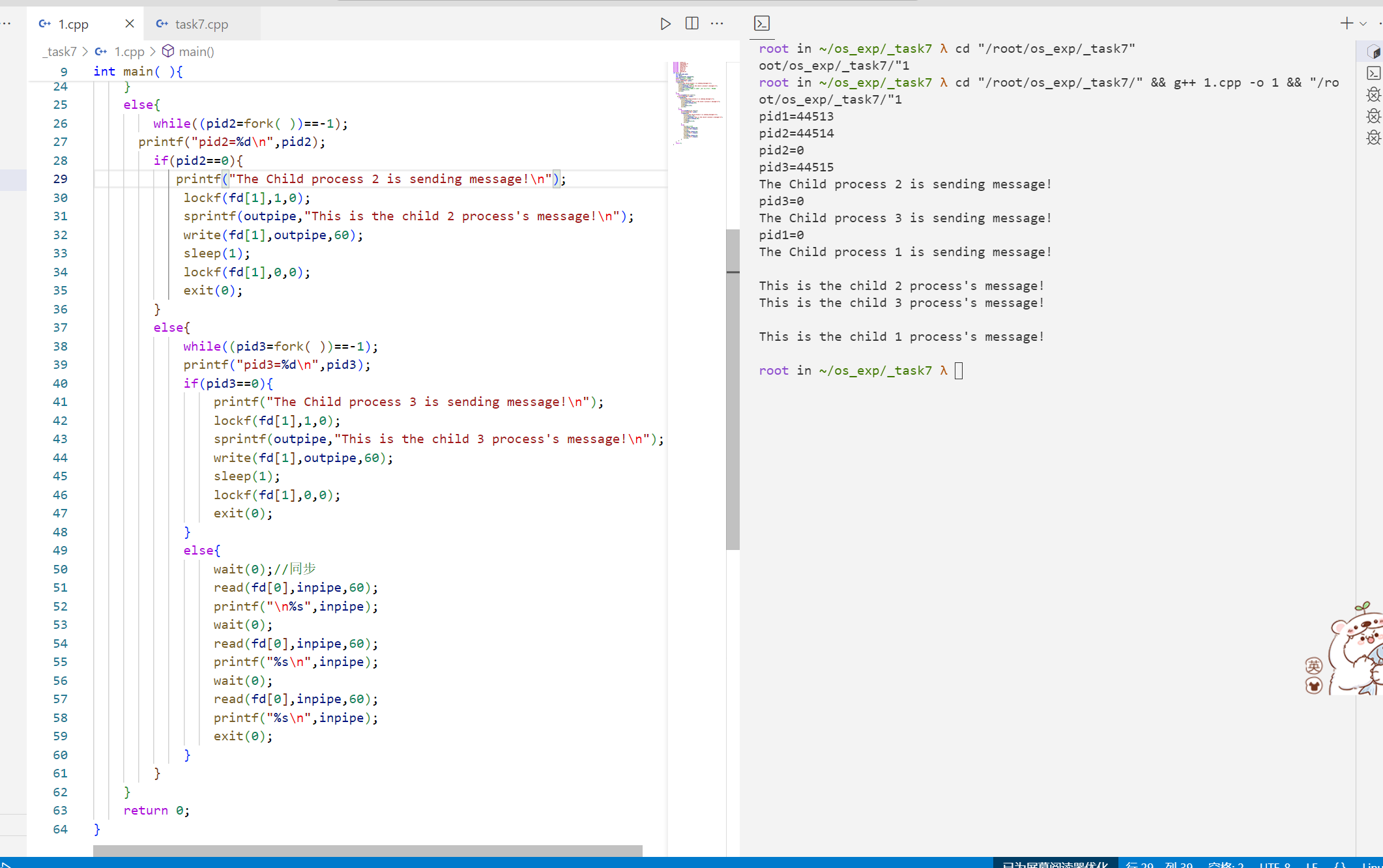
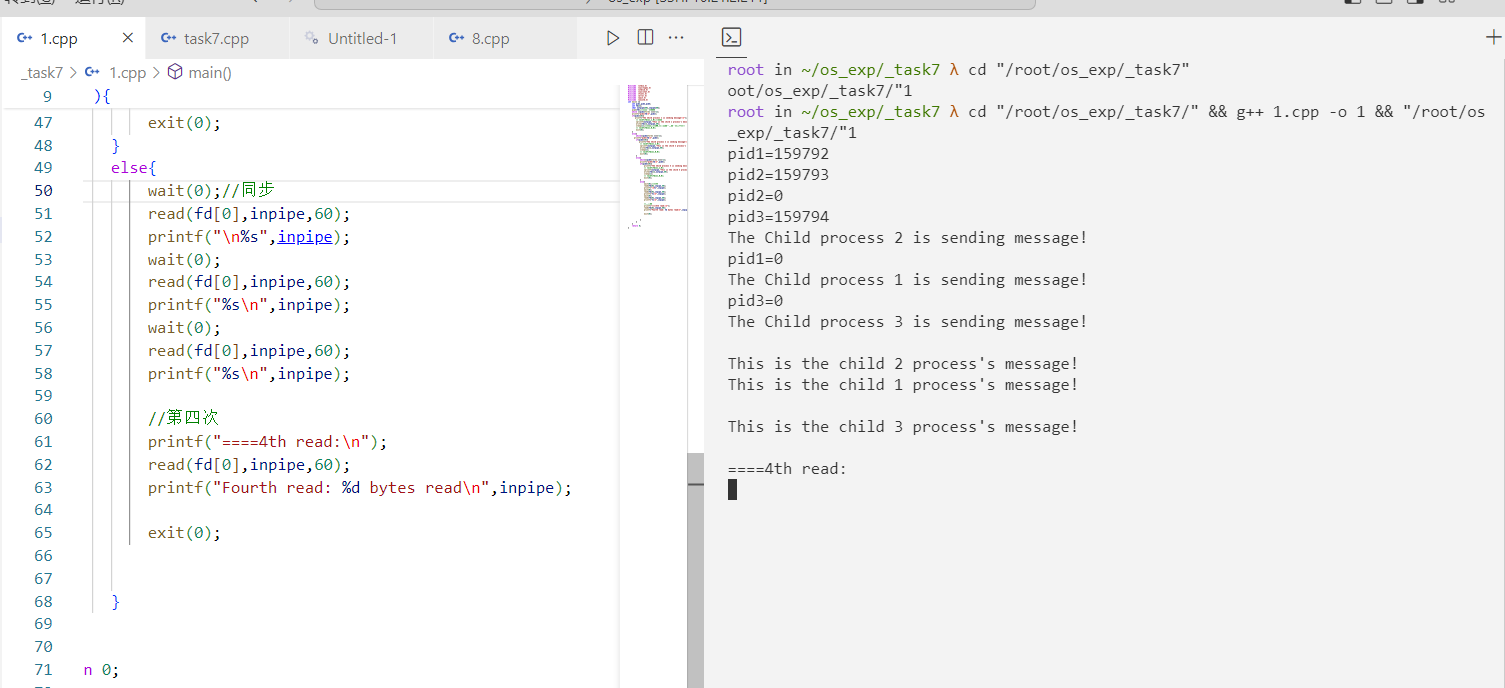
五、提供的源代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #include <stdio.h> #include <sys/types.h> #include <stdlib.h> #include <sys/stat.h> #include <fcntl.h> #include <error.h> #include <wait.h> #include <unistd.h> int main ( ) int pid1,pid2,pid3; int fd[2 ]; char outpipe[60 ],inpipe[60 ]; pipe (fd); while ((pid1=fork( ))==-1 ); printf ("pid1=%d\n" ,pid1); if (pid1==0 ){ printf ("The Child process 1 is sending message!\n" ); lockf (fd[1 ],1 ,0 ); sprintf (outpipe,"This is the child 1 process's message!\n" ); write (fd[1 ],outpipe,60 ); sleep (1 ); lockf (fd[1 ],0 ,0 ); exit (0 ); } else { while ((pid2=fork( ))==-1 ); printf ("pid2=%d\n" ,pid2); if (pid2==0 ){ printf ("The Child process 2 is sending message!\n" ); lockf (fd[1 ],1 ,0 ); sprintf (outpipe,"This is the child 2 process's message!\n" ); write (fd[1 ],outpipe,60 ); sleep (1 ); lockf (fd[1 ],0 ,0 ); exit (0 ); } else { while ((pid3=fork( ))==-1 ); printf ("pid3=%d\n" ,pid3); if (pid3==0 ){ printf ("The Child process 3 is sending message!\n" ); lockf (fd[1 ],1 ,0 ); sprintf (outpipe,"This is the child 3 process's message!\n" ); write (fd[1 ],outpipe,60 ); sleep (1 ); lockf (fd[1 ],0 ,0 ); exit (0 ); } else { wait (0 ); read (fd[0 ],inpipe,60 ); printf ("\n%s" ,inpipe); wait (0 ); read (fd[0 ],inpipe,60 ); printf ("%s\n" ,inpipe); wait (0 ); read (fd[0 ],inpipe,60 ); printf ("%s\n" ,inpipe); exit (0 ); } } } return 0 ; }
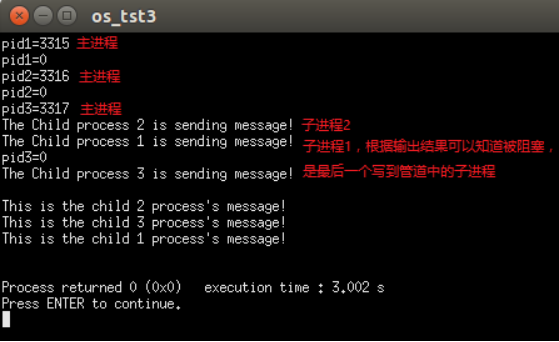
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 root in ~/os_exp/_task7 λ cd "/root/os_exp/_task7/" && g++ 1.cpp -o 1 && "/ro ot/os_exp/_task7/" 1pid1=44806 pid2=44807 pid2=0 The Child process 2 is sending message! pid3=44808 pid3=0 The Child process 3 is sending message! pid1=0 The Child process 1 is sending message! This is the child 2 process's message! This is the child 3 process' s message!This is the child 1 process's message!
另外一个输出
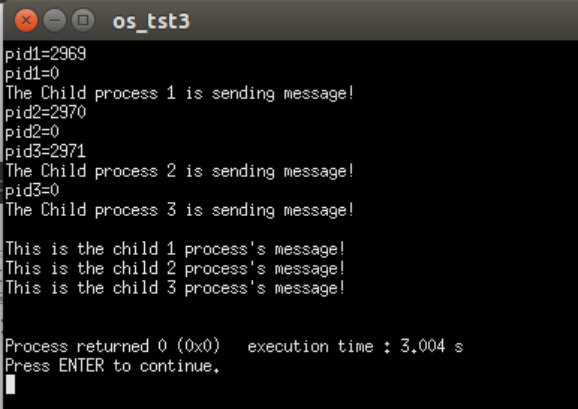
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 root in ~/os_exp/_task7 λ cd "/root/os_exp/_task7/" && g++ 1.cpp -o 1 && "/ro ot/os_exp/_task7/" 1pid1=45542 pid1=0 pid2=45543 The Child process 1 is sending message! pid2=0 The Child process 2 is sending message! pid3=45544 pid3=0 The Child process 3 is sending message! This is the child 1 process's message! This is the child 2 process' s message!This is the child 3 process's message!
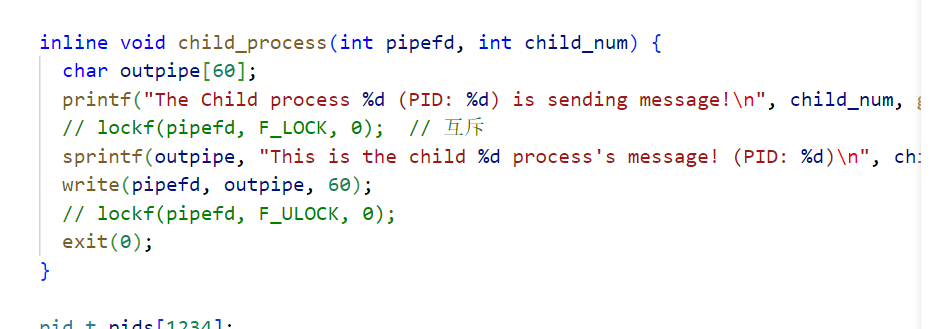
稍微修改了一下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <stdio.h> #include <sys/types.h> #include <stdlib.h> #include <sys/stat.h> #include <fcntl.h> #include <error.h> #include <wait.h> #include <unistd.h> inline void child_process (int pipefd, int child_num) char outpipe[60 ]; printf ("The Child process %d (PID: %d) is sending message!\n" , child_num, getpid ()); lockf (pipefd, F_LOCK, 0 ); sprintf (outpipe, "This is the child %d process's message! (PID: %d)\n" , child_num, getpid ()); write (pipefd, outpipe, 60 ); lockf (pipefd, F_ULOCK, 0 ); exit (0 ); } int main () int pid1, pid2, pid3; int fd[2 ]; char inpipe[60 ]; pipe (fd); perror ("pipe" ); pid1 = fork(); if (pid1 == -1 ) { perror ("fork" ); exit (1 ); } else if (pid1 == 0 ) { child_process (fd[1 ], 1 ); } pid2 = fork(); if (pid2 == -1 ) { perror ("fork" ); exit (1 ); } else if (pid2 == 0 ) { child_process (fd[1 ], 2 ); } pid3 = fork(); if (pid3 == -1 ) { perror ("fork" ); exit (1 ); } else if (pid3 == 0 ) { child_process (fd[1 ], 3 ); } waitpid (pid1, NULL , 0 ); read (fd[0 ], inpipe, 60 ); printf ("\n[fa]fa proc rev from p1: %s" , inpipe); waitpid (pid2, NULL , 0 ); read (fd[0 ], inpipe, 60 ); printf ("[fa]fa proc rev from p2: %s" , inpipe); waitpid (pid3, NULL , 0 ); read (fd[0 ], inpipe, 60 ); printf ("[fa]fa proc rev from p3: %s" , inpipe); close (fd[0 ]); close (fd[1 ]); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 root in ~/os_exp/_task7 λ cd "/root/os_exp/_task7/" && g++ task7.cpp -o task7 && "/root/os_exp/_task7/" task7 pipe: Success The Child process 2 (PID: 44959) is sending message! The Child process 1 (PID: 44958) is sending message! The Child process 3 (PID: 44960) is sending message! [fa]fa proc rev from p1: This is the child 2 process's message! (PID: 44959) [fa]fa proc rev from p2: This is the child 1 process' s message! (PID: 44958)[fa]fa proc rev from p3: This is the child 3 process's message! (PID: 44960) root in ~/os_exp/_task7 λ
六、回答问题
fd[0] 用于管道的读端,
fd[1] 用于管道的写端。
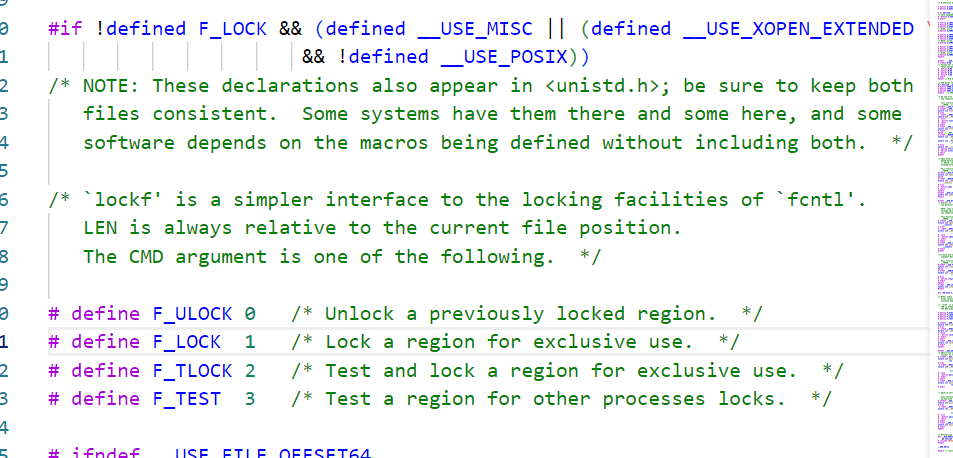
lockf(int fd, int cmd, off_t len);
F_LOCK:锁定文件区域。这里对应1
F_ULOCK:解锁文件区域,允许其他进程访问。这里对应0
如果 len 被设置为 0,则表示从当前位置到文件的末尾都将被锁定或解锁。
(1)指出父进程与两个子进程并发执行的顺序,并说明原因。 根据代码和运行结果:
父进程与三个子进程的并发执行顺序是不确定的,它们是并发执行的。
原因如下:
父进程先通过fork()创建了三个子进程pid1、pid2、pid3,三个子进程几乎同时开始执行。
每个子进程在向管道写入消息前,都调用了lockf(fd[1], F_LOCK, 0)对管道的写端加锁,这保证了同一时刻只有一个进程可以向管道写数据,从而实现了互斥访问。写完后调用lockf(fd[1], F_ULOCK, 0)解锁。
每个子进程向管道写完数据后,都会调用exit(0)退出。而父进程中使用了waitpid或者wait来等待子进程结束。
虽然子进程启动顺序是pid1、pid2、pid3,但由于它们是并发执行的,每个子进程的执行速度受CPU调度、IO等因素影响,所以它们向管道写数据和退出的先后顺序是不确定的。
父进程虽然按pid1、pid2、pid3的顺序waitpid,或者直接原文中的wait,但具体等到哪个子进程先结束是不确定的,取决于子进程的实际执行情况。
所以整体上看,父进程与三个子进程是并发执行的,它们的执行顺序和结束顺序都是不确定的,每次运行的结果可能都不太一样,这就是并发执行的特点。而管道的互斥访问机制保证了并发的正确性。
(2)若不对管道加以互斥控制,会有什么后果?
但是后来经过测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 inline void child_process (int pipefd, int child_num) char outpipe[8192 ]; printf ("The Child process %d (PID: %d) is sending message!\n" , child_num, getpid ()); sprintf (outpipe, "This is the child %d process's message! (PID: %d)\n" , child_num, getpid ()); for (int i=10 ;i<=8000 ;++i)outpipe[i]=child_num%26 +'a' ; outpipe[8000 ]='\0' ; write (pipefd, outpipe,rd_sz); sleep (1 ); exit (0 ); }
目前的内核好像会自动加锁,也就是自动管理这些冲突。
但是从题意来说要这么回答: 如果不对管道加以互斥控制,可能会出现以下问题:
数据混乱或不完整:多个进程同时向管道写数据,由于没有互斥控制,它们的数据可能会交织在一起,导致读出的数据混乱或不完整。例如进程1写入”Hello”,进程2写入”World”,可能读出的是”HeWorllod”这样的混乱数据。
数据丢失:如果多个进程同时写,可能会发生数据覆盖,导致部分数据丢失。比如进程1和进程2同时写,进程1的数据可能会被进程2的数据部分或全部覆盖,导致进程1的部分或全部数据丢失。
程序行为不确定:由于数据混乱或丢失,程序的行为可能变得不确定。例如本来期望读到进程1和进程2的完整数据,但实际读到的是不完整或混乱的数据,这可能导致程序后续的运行出现异常或错误。
在没有使用互斥控制,但每个子进程写入的数据还是能够正确地被父进程读取,没有出现明显的问题。这可能是因为:管道的缓冲区足够大,能够容纳所有子进程写入的数据,没有发生覆盖,原子写入单元没有达到,所以每个子进程的写操作都是一个原子操作,不会被其他进程的写操作打断。
尽管在这种特定情况下没有出现问题,但在一般情况下,特别是多个进程写入的数据量很大或写入操作频繁时,不加互斥控制还是可能会出现数据混乱、丢失等问题。所以为了程序的稳健性和正确性,对共享资源(如管道)进行互斥控制是一个好的编程实践。
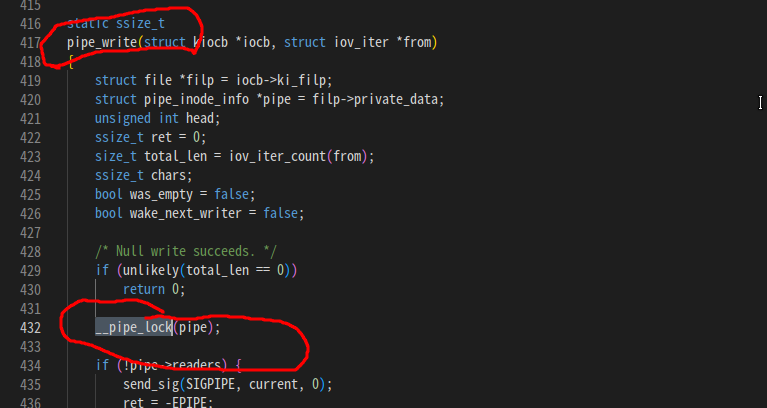
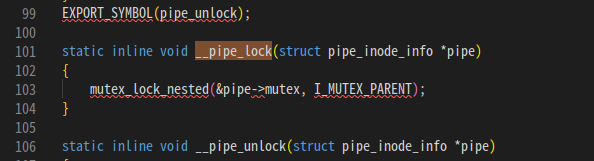
内核源码,管道相关 6.6.3源码fs/pipe.c:432
所以写入管道之前会自动锁一下,因此,上面如果即便是不加控制也会自动锁啦。
(3)说明你是如何实现父子进程之间的同步的。 父子进程之间的同步是通过以下几个机制实现的:
fork()系统调用:
当父进程调用fork()时,它会创建一个子进程,子进程是父进程的一个副本。
在调用fork()之后,父进程和子进程都从fork()的下一条语句开始执行,但是它们有不同的进程ID。
这样,父进程可以通过检查fork()的返回值来区分自己是父进程还是子进程,从而执行不同的代码。
waitpid()系统调用:
父进程在创建子进程后,通过调用waitpid()来等待特定的子进程结束。
waitpid()会阻塞父进程,直到指定的子进程结束。
在代码中,父进程依次等待子进程p1,p2,p3结束,确保在读取管道数据之前,对应的子进程已经完成了写入操作。
exit()系统调用:
每个子进程在完成自己的任务后,通过调用exit()来结束自己的执行。
这会向父进程发送一个信号,告诉父进程这个子进程已经结束了。
父进程在waitpid()中收到这个信号,就知道可以继续执行了。
管道的阻塞特性:
当一个进程尝试从一个空的管道读取数据时,它会被阻塞,直到管道中有数据可读。
同样,当一个进程尝试向一个已满的管道写入数据时,它也会被阻塞,直到管道有足够的空间。
这种阻塞特性自然地实现了一种同步:写进程必须等待读进程读取数据,读进程必须等待写进程写入数据。
lockf()系统调用:
在代码中,每个子进程在写入管道之前,都通过lockf()获取一个排他锁。
这确保了在任何时刻,只有一个子进程在写管道,避免了数据混乱。
子进程写完后,通过lockf()释放锁,允许其他子进程写入。
通过fork()、waitpid()、exit()实现了父进程和子进程的启动和结束同步,通过管道的阻塞特性实现了读写进程之间的同步,通过lockf()实现了子进程写操作之间的同步。这些机制一起确保了程序在并发执行时的正确性。
(4)源代码中,如果父进程执行读消息四次什么结果?
1 2 3 4 printf ("====4th read:\n" );read (fd[0 ],inpipe,60 );printf ("Fourth read: %d bytes read\n" ,inpipe);
这样实际上进程没有执行完exit(0)
如果父进程执行读消息四次,那么第四次读操作的行为将取决于管道的状态:
如果在前三次读操作之后,所有子进程都已经结束,并且管道中没有更多的数据,那么第四次读操作将会阻塞,直到有新的数据被写入管道,或者所有写管道的进程关闭了它们的写文件描述符。
在代码中,只有三个子进程向管道写数据,并且每个子进程在写完数据后就退出了。所以,在父进程完成三次读操作后,管道应该是空的,并且所有写端都已经关闭。
在这种情况下,第四次read调用会立即返回0,表示已经到达了文件的末尾(EOF)。这是因为当管道的写端都关闭时,读端会收到一个EOF信号。
如果在前三次读操作之后,还有一个或多个子进程没有结束,并且它们可能会继续写入数据,那么第四次读操作的行为就像前三次一样:
如果管道中有数据,read调用将立即返回,并读取数据。
如果管道中没有数据,read调用将阻塞,直到有数据可读或所有写端都关闭。
如果父进程在第四次读操作之前没有等待所有子进程结束(即,如果删除或注释掉前三个wait(0)调用),那么第四次读操作可能会读到不完整的数据,或者阻塞,或者收到EOF,取决于子进程的执行进度。
所以,在正常情况下,如果父进程尝试读取四次,第四次读操作将立即返回EOF(读取长度为0)。这可以用作一个信号,表示所有子进程都已经完成了它们的工作,并且管道已经关闭。
(5)父进程发送消息,三个子进程分别读。
1 2 3 4 sprintf (outpipe, "This is a message from the parent process! (PID: %d)\n" , getpid ());write (fd[1 ], outpipe, rd_sz);write (fd[1 ], outpipe, rd_sz);write (fd[1 ], outpipe, rd_sz);
执行结果
1 2 3 4 5 root@debian:~/os_exp/_task7 pipe: Success Child process 2 (PID: 278756) received message: This is a message from the parent process! (PID: 278754) Child process 3 (PID: 278757) received message: This is a message from the parent process! (PID: 278754) Child process 1 (PID: 278755) received message: This is a message from the parent process! (PID: 278754)
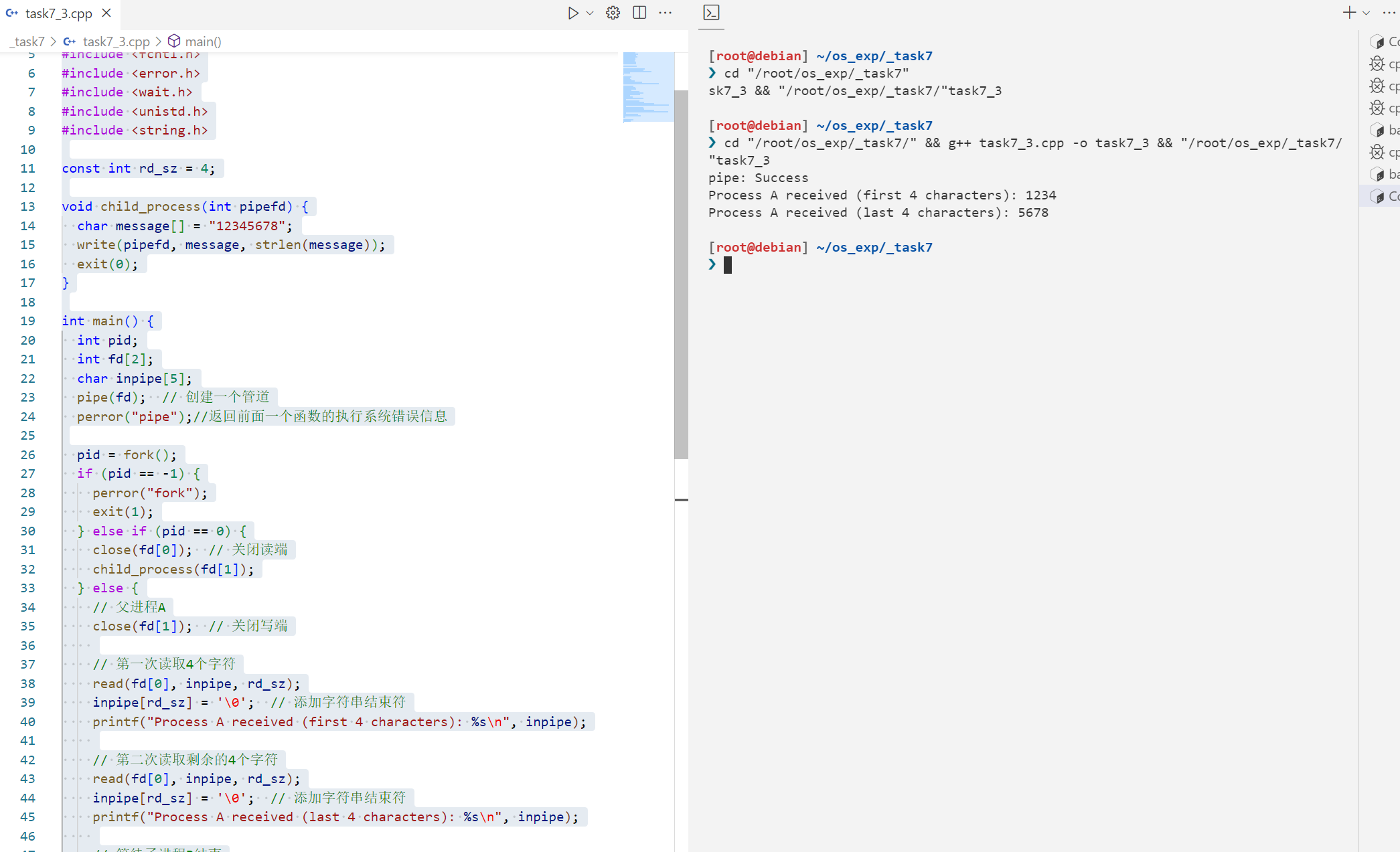
(6)新代码,进程A创建一个子进程B, B发送消息“12345678”,A分两次接收,一次接收4个字符。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <stdio.h> #include <sys/types.h> #include <stdlib.h> #include <sys/stat.h> #include <fcntl.h> #include <error.h> #include <wait.h> #include <unistd.h> #include <string.h> const int rd_sz = 4 ;void child_process (int pipefd) char message[] = "12345678" ; write (pipefd, message, strlen (message)); exit (0 ); } int main () int pid; int fd[2 ]; char inpipe[5 ]; pipe (fd); perror ("pipe" ); pid = fork(); if (pid == -1 ) { perror ("fork" ); exit (1 ); } else if (pid == 0 ) { close (fd[0 ]); child_process (fd[1 ]); } else { close (fd[1 ]); read (fd[0 ], inpipe, rd_sz); inpipe[rd_sz] = '\0' ; printf ("Process A received (first 4 characters): %s\n" , inpipe); read (fd[0 ], inpipe, rd_sz); inpipe[rd_sz] = '\0' ; printf ("Process A received (last 4 characters): %s\n" , inpipe); waitpid (pid, NULL , 0 ); } close (fd[0 ]); return 0 ; }
输出结果
1 2 3 4 5 6 [root@debian] ~/os_exp/_task7 ❯ cd "/root/os_exp/_task7/" && g++ task7_3.cpp -o task7_3 && "/root/os_exp/_task7/ " task7_3pipe: Success Process A received (first 4 characters): 1234 Process A received (last 4 characters): 5678
实验8:Linux环境下 实验三 局部性原理
实验三 局部性原理(数组清零)
一、实验目的:加深对操作系统存储管理的理解 二、实验原理 程序的局部性原理:
程序对比分析
for(i=0;i<1024;i++)
程序是按列把数组中的元素清”0”的,所以,每执行一次test[j][i]=0就会产生一次缺页中断。因为开始时第一页已经在主存了,故程序执行时就可以对元素test[1][1]清零,但下一个元素test[2][1]不在该页,就产生缺页中断。按程序上述的编制方法,每装入一页只对一个元素清零后就要产生缺页中断,于是总共要产生1024*1024-1次缺页中断。
for(i=0;i<1024;i++)
按行清零,每转入一页后就对一行元素全部清零后才产生缺页中断,故总共产生1024-1次缺页中断。
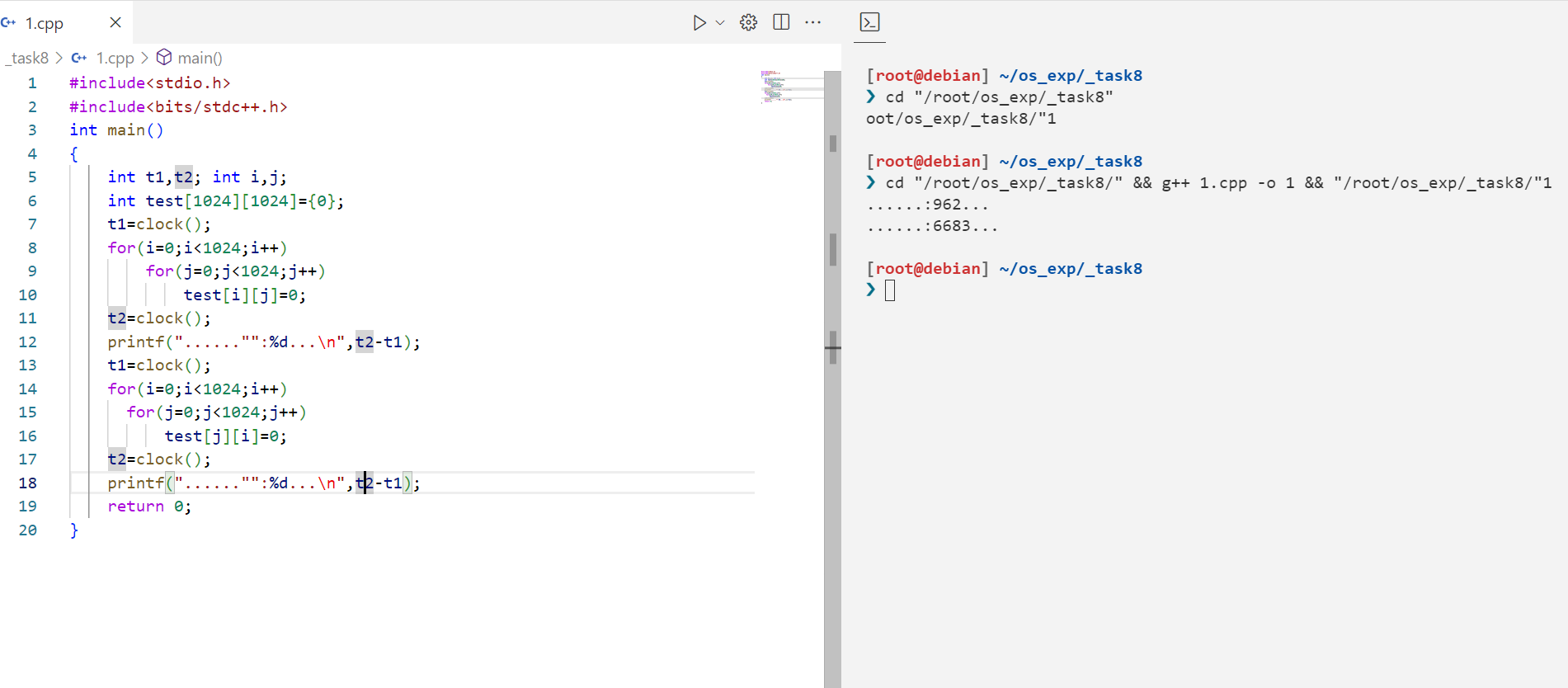
三、实验源代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <stdio.h> int main () int t1,t2; int i,j; int test[1024 ][1024 ]={0 }; t1=clock (); for (i=0 ;i<1024 ;i++) for (j=0 ;j<1024 ;j++) test[i][j]=0 ; t2=clock (); printf ("......" ":%d...\n" ,t2-t1); t1=clock (); for (i=0 ;i<1024 ;i++) for (j=0 ;j<1024 ;j++) test[j][i]=0 ; t2=clock (); printf ("......" ":%d...\n" ,t2-t1); return 0 ; }
四、实验结果:
1 2 3 4 [root@debian] ~/os_exp/_task8 ❯ cd "/root/os_exp/_task8/" && g++ 1.cpp -o 1 && "/root/os_exp/_task8/" 1 ......:962... ......:6683...
在max = 2e4 = 20000的数据量下:
1 2 3 4 [root@debian] ~/os_exp/_task8 ❯ cd "/root/os_exp/_task8/" && g++ 1.cpp -o 1 && "/root/os_exp/_task8/"1 ......:1420745... ......:3117028...
五、实验分析: 实验旨在探究程序局部性原理对程序执行效率的影响。通过比较两种不同的二维数组清零方式,即按行清零和按列清零,可以看出程序局部性原理在实际编程中的重要性。
实验源代码中定义了一个1024x1024的二维数组test,并分别使用两种不同的嵌套循环方式对数组元素进行清零操作。第一种方式是按行清零,即外层循环变量i表示行号,内层循环变量j表示列号,每次对test[i][j]进行清零。第二种方式是按列清零,即外层循环变量i表示列号,内层循环变量j表示行号,每次对test[j][i]进行清零。
实验结果显示,按行清零的方式耗时962毫秒,而按列清零的方式耗时6683毫秒,按列清零的执行时间是按行清零的近7倍。产生如此显著差异的原因就在于程序局部性原理。
程序局部性原理指出,程序在执行过程中,倾向于引用邻近于当前引用位置的数据项,这种倾向性可以分为时间局部性和空间局部性。时间局部性是指一个数据项在被访问后,在不久的将来还会被再次访问;空间局部性是指如果一个数据项被访问,那么与它相邻的数据项也很有可能被访问。
在本实验中,按行清零的方式恰好符合程序的空间局部性。因为二维数组在内存中是以行优先的方式存储的,即数组中相邻行的元素在内存中也是相邻存储的。按行清零时,每次访问完一行的元素后,下一次要访问的元素恰好存储在相邻的内存位置,这样可以最大限度地利用 CPU 高速缓存,减少 CPU 和内存之间的数据交换,从而提高程序执行效率。
反之,按列清零的方式违背了程序的空间局部性原理。因为每次清零完一列的元素后,下一列的元素在内存中并不是相邻存储的,而是相隔了整整一行的存储空间。这样,每次访问下一列元素时,都会导致 CPU 高速缓存未命中,需要从内存中重新读取数据,这就大大增加了数据交换的次数和时间开销,降低了程序执行效率。按列清零的方式还会导致大量的缺页中断。因为每次访问下一列元素时,很可能需要访问不在当前内存页面中的数据,从而导致缺页中断,需要从磁盘中调入所需的页面,这进一步加剧了程序执行效率的下降。
本实验通过两种不同的二维数组清零方式,直观地展示了程序局部性原理对程序执行效率的重大影响。在实际编程中,我们应该充分利用程序的局部性原理,合理安排数据的存储和访问顺序,尽可能减少 CPU 高速缓存的未命中和缺页中断,以提高程序的执行效率。这对于编写高性能、高效率的程序具有重要意义。
本实验也启示我们,在进行算法设计和代码优化时,要充分考虑数据的存储特性和访问模式,避免违背程序局部性原理的数据访问方式,以免带来不必要的性能损失。只有深入理解并灵活运用程序局部性原理,才能写出高质量、高性能的代码。
文件下载 https://p.dabbit.net/blog/pic_bed/sharex/_pn-2024-06-07-22-35-35_Isopod_Victorious_Weary.7z