第十周实训
第十周实训——魔王大帝组
该文档已经不是最新,但是可以来方便阅读,有的新内容直接写在了word里(受时间关系导致)
项目概述
我们实现了一个:
上课的基础功能,包括但不限于以下的功能:
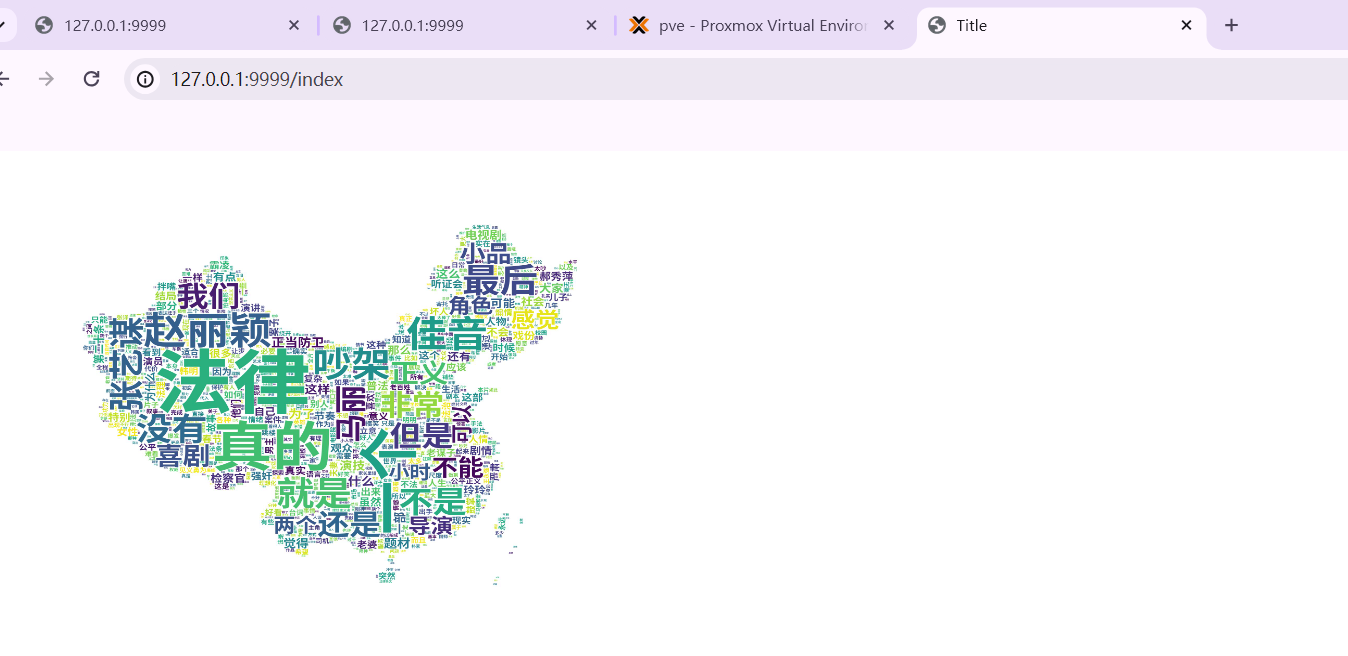
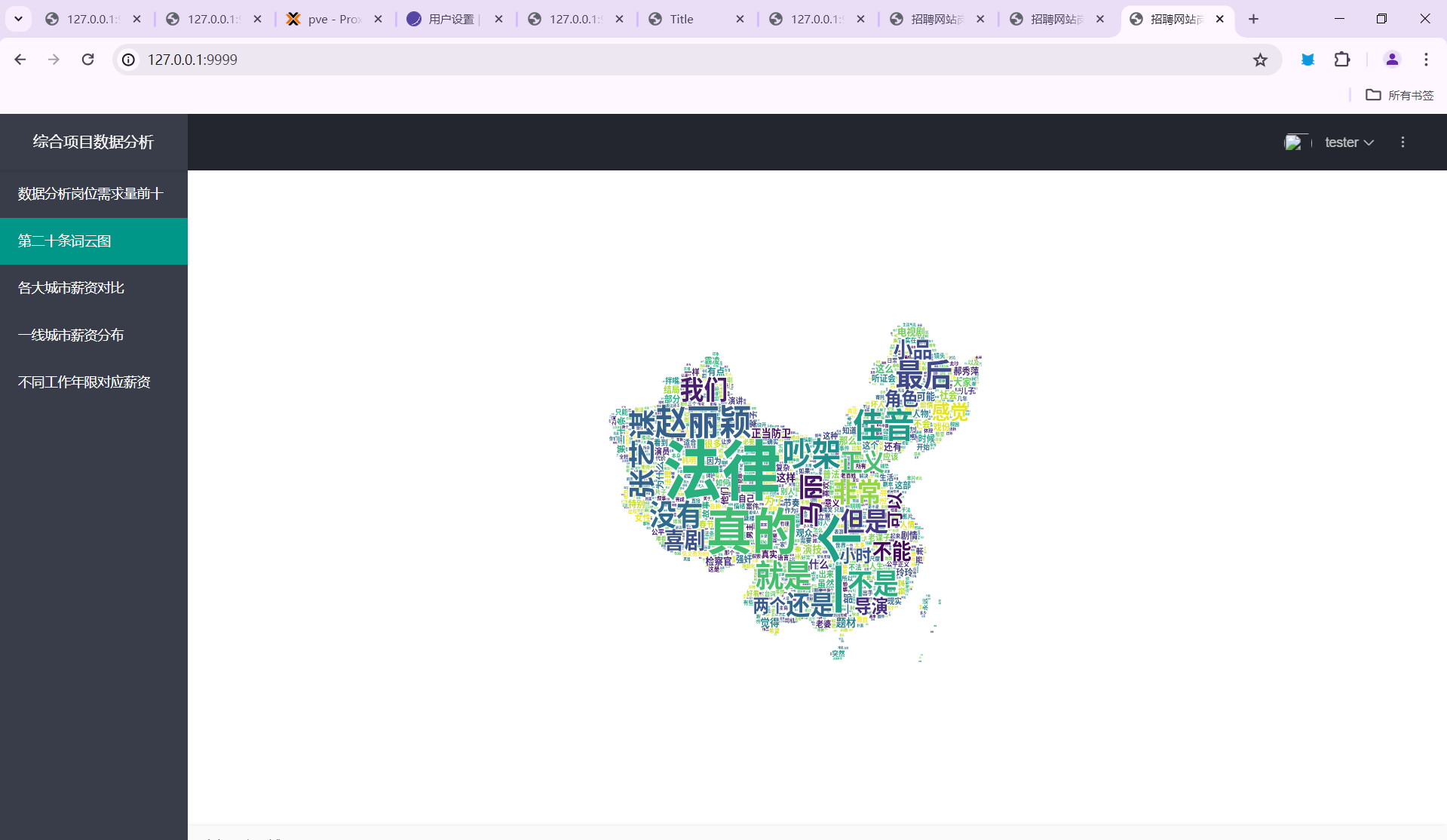
- 第二十条词云图
- 青岛二手房散点图(面积与价格)
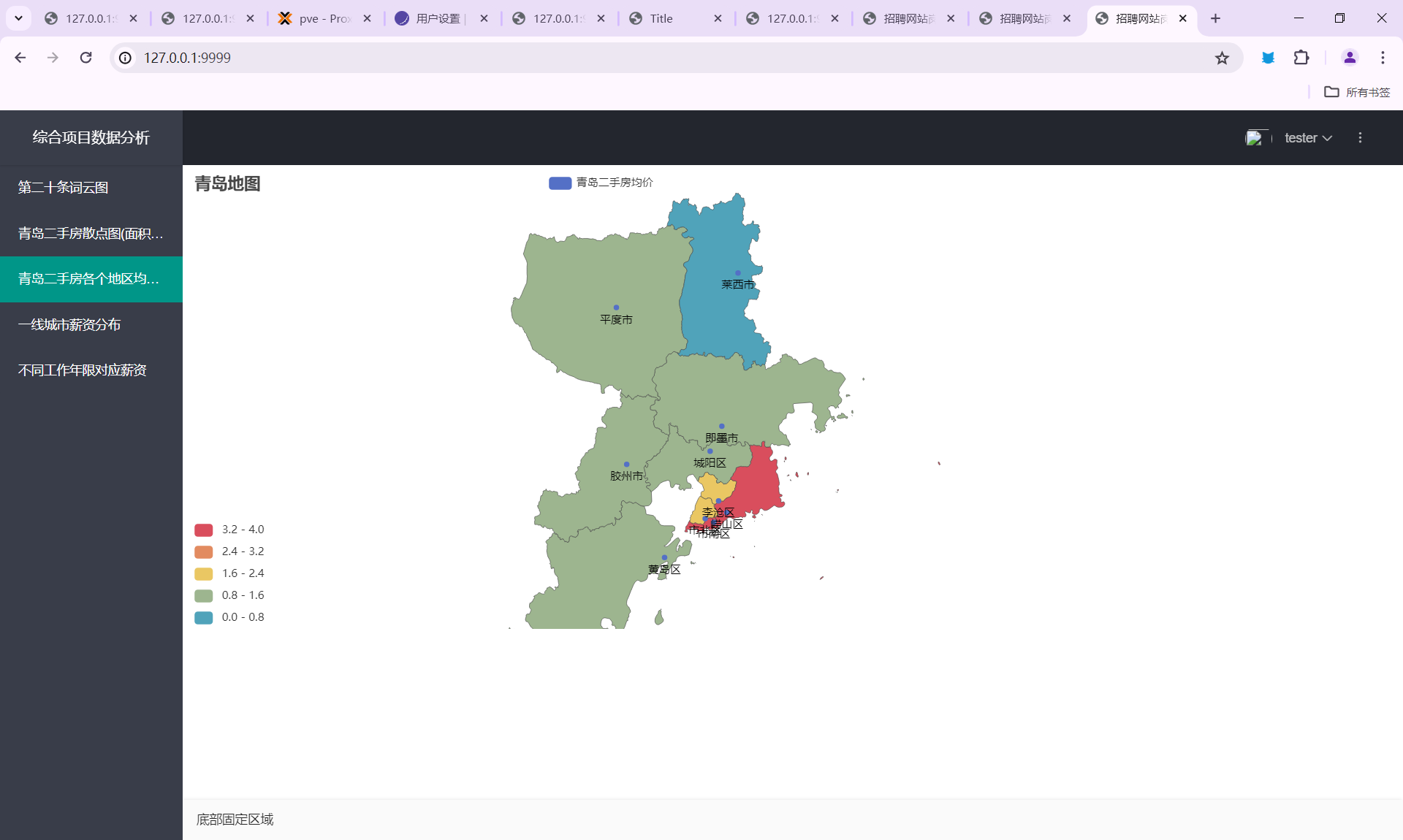
- 青岛二手房各个地区均价情况
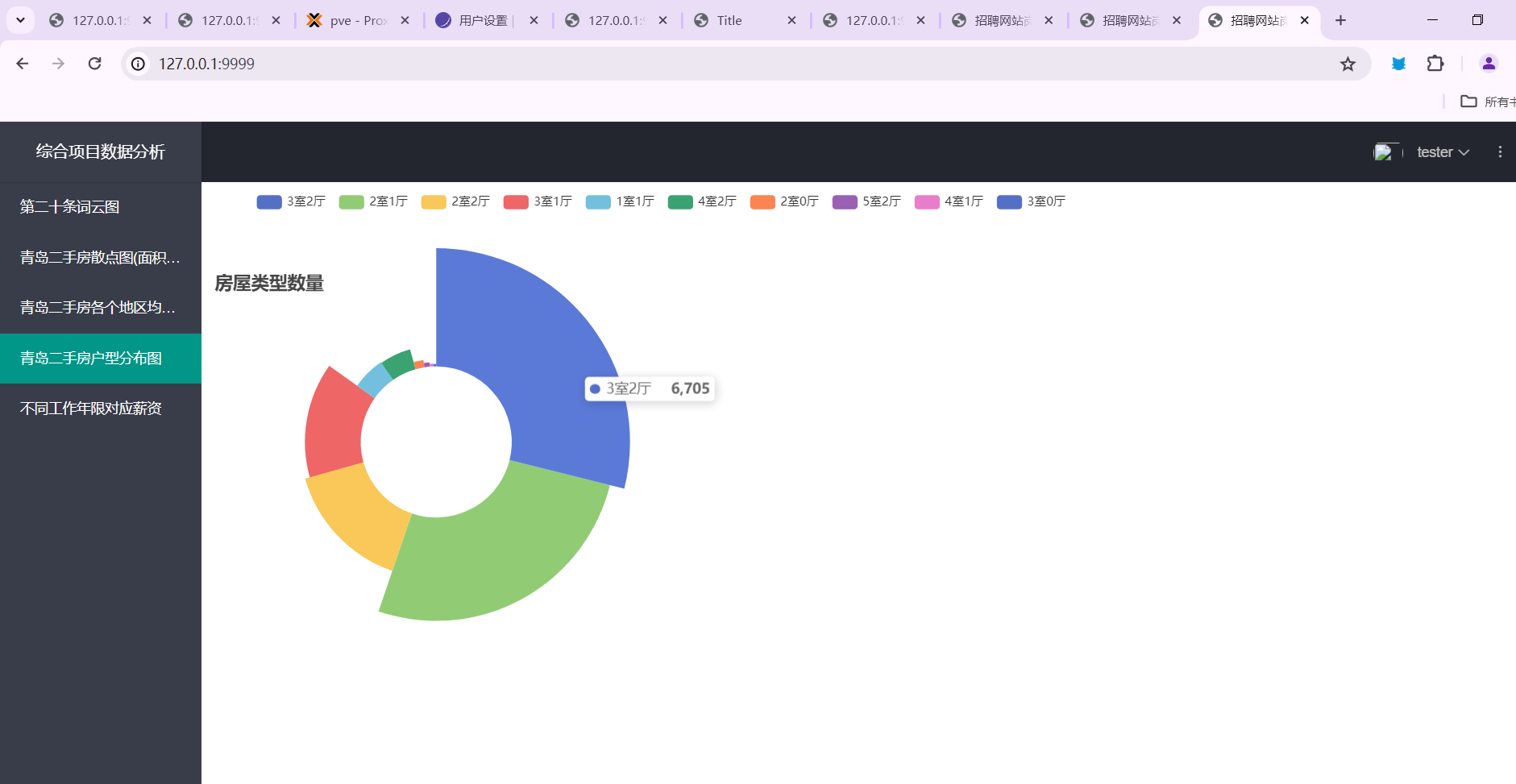
- 青岛二手房户型分布图
- 青岛二手房均价最高的几个小
- 远程代码执行(POC):YOLO人脸识别。
- 远程代码执行(POC):弹你计算器(字面意思)
获得当前豆瓣热映的电影(根据地区,默认
taian(泰安)),然后显示在网页中。- 用户可以点击【查看评论】、【查看封面】和【购票】按钮。
- 【查看评论】会自动爬取前100条评论(接口调用没有写死,可以随便向后申请继续爬取多少条),然后展示给用户。
- 【购票】从豆瓣获得链接后,自动跳转
- 【查看封面】查看该电影的封面。(从豆瓣爬取)
- 【查看评论】会自动根据当前评论通过jieba和wordcloud来生成一张好看的词云图片。(已经将原图的颜色的对比度调整,以便获得更好看的图云图片)
将上述功能转变为API接口,类RESTful,提供功能:
- 获得当前最热门的电影(同时提供
subjectid) - 根据电影的
subjectid(豆瓣提供)来查看评论 - 获得词云:发送
subjectid即可发送回来一个json数据,其中包含base64编码的图片。 - ai画图:发送
subjectid即可。会自动根据当前评论,通过jieba来分词,选取前30条最热门的词汇,调用stable-diffusion XL模型来进行绘画一张符合评论分词的图片。
- 获得当前最热门的电影(同时提供
将上述功能接入qq机器人(通过
Graia框架)(但不限于qq机器人,可以通过框架的嵌套同时接入包括但不限于QQ官方机器人、企业微信机器人、钉钉机器人、Kook机器人、discord等)- 提供功能:用户发送:
/查电影 - 向用户发送最近热门的电影
- 用户选择并发送数字(30秒内,如果超时会提示已经超时)
- 发送电影的基本信息、评论、词云、AI画图的结果。
- 以上功能的实现封装为了单独的类(同时可以随便封装为包),非常方便各种迁移,以及对于多线程或异步的调度非常方便。
- 提供功能:用户发送:
SDUST查新闻,包括但不限于,词云,OPENCV数人头,看新闻,数据库存储~
- 使用了32线程进行快速爬取,可在15分钟内下载3700条以上的新闻全部内容。
- 异步下载图片,结合多线程可以非常快速地下载数据。
- 爬虫请求量非常大,15分钟内请求量超过20000+。
- 支持单线程低调地获取数据。
- 将有关函数全部封装成模块,可以非常方便地导入和使用。
- 封装了获取新闻列表、获取新闻页面内容、获取点击量、异步下载图片等功能。
- 针对不同页面(如泰安校区新闻页)的差异进行了适配。
- 将新闻内容、点击率、标题等存入sqlite数据库。使用sqlalchemy支持多线程操作。
- 下载的图片按年月分类保存到本地文件夹。
- 支持将数据导出为txt、csv等格式,方便其他程序读取使用。
- 根据新闻内容生成了好看的词云图片。
- 尝试对网站进行了简单的漏洞扫描,但因限制未完成。
- 使用sqlite数据库存储爬取的新闻数据,包括新闻标题、发布时间、正文内容、点击量、图片URL等。
- 引入了sqlalchemy库,封装了数据库操作,支持多线程并发读写,便于迁移到MySQL等其他数据库。
- 提供了数据插入和查询的简单接口,可以方便地将爬取的数据入库和进行后续分析。
- 对下载的图片按照年-月的目录结构进行存储归类,便于管理和查看。
- 支持将数据以JSON、txt、csv等通用格式进行导出,方便与其他语言和系统进行交互和分析。
- 利用Python的OpenCV库,对爬取的新闻图片进行人脸和人头检测,可以自动统计一张图片中的人数。为进一步分析提供了思路。
- 对新闻正文内容进行分词处理,并使用wordcloud库生成美观的词云图片,直观展示新闻的热点话题。
- 尝试使用工具对新闻网站进行了初步的漏洞扫描,但由于对方网站有所限制而未能完成。不过这为网络安全研究提供了一个切入点。
- 上面的这个数据库,已经接到了flask上
- 根据上面这个每个新闻可以实时生成词云图
YOLO V8 识别人脸和左眼右眼鼻子等定位~
docker-compose部署!
- ovo
主界面
项目部署地址:
因为这个项目一看就全是漏洞,跑在docker容器里,但还是几天重置一次哦。
- 部署地址:https://magic-dragon.dayi.ink/ (直连)
- 备用部署地址:https://magic-king.dayi.ink/ (cloudflare的负载均衡!防止爆炸)
docker部署
应该是最简单的啦
docker-compose
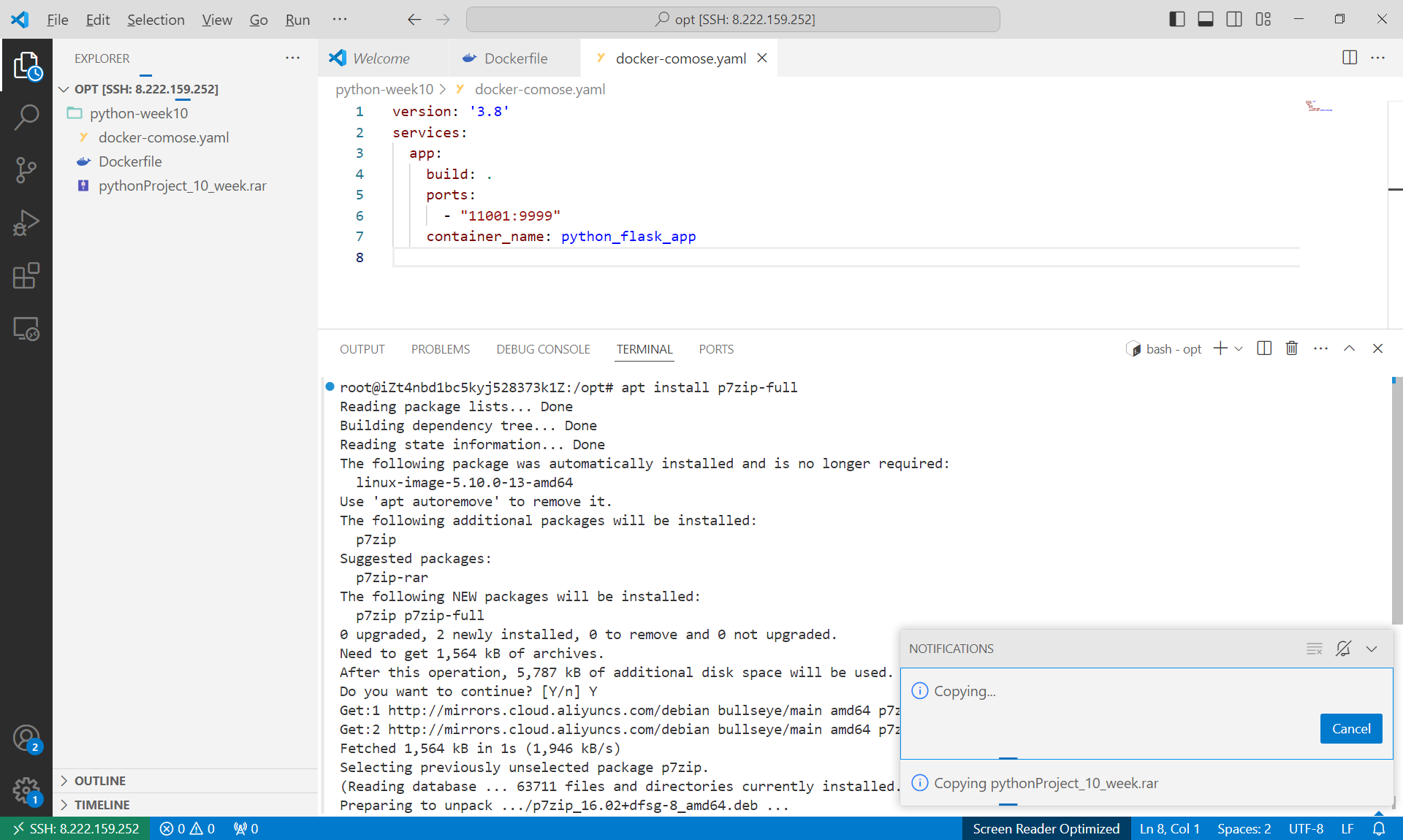
Dockerfile
1 | FROM python:3.9.19-bullseye |
简单build一下
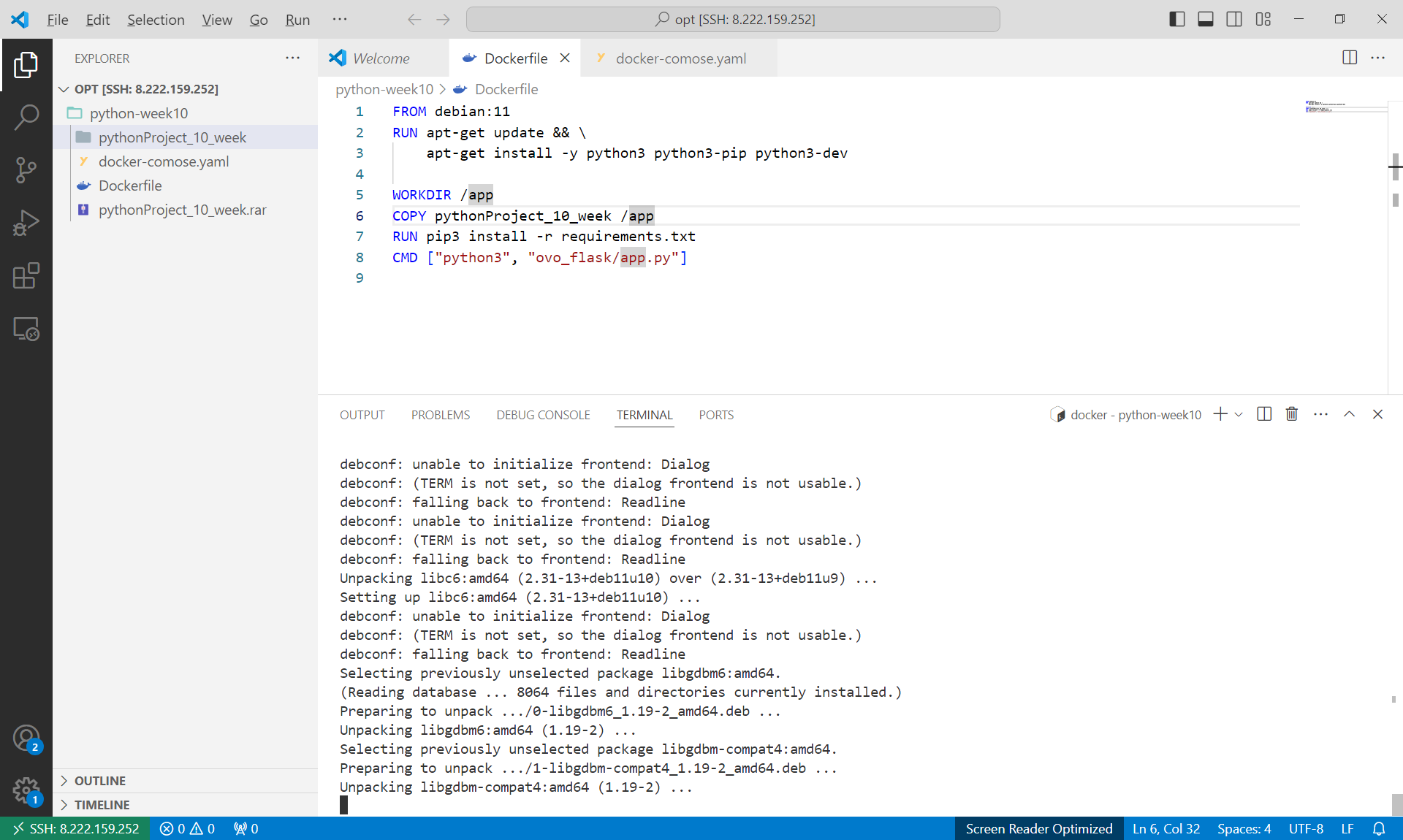
稍微改了一下下
复制文件
当当
AI画图实现细节
SD模型是本地部署的,通过cloudflare隧道接到公网上,用cloudflare的零信任来保证授权,然后用的Stable Diffusion XL模型,根据电影评论,通过jieba分词,来提取前30个最热门的词汇来进行生成提示词(其实还想接入GPT/或者本地AI,来进行生成绘画提示词,但是时间有点不够了)。
具体的实现方法:
其实这个AI绘图其实跟爬虫的类是一个,这样虽然其实是适合分割,但这样放一起可以直接相互调用,方便先实现功能。
使用
get_more_comments方法从豆瓣电影获取指定电影ID的评论数据(可指定获取的评论数量)。使用jieba库对获取到的评论文本进行分词,过滤掉一些常见的无意义词汇,统计词频,选取词频最高的前30个词作为关键词。
使用googletrans库将这些中文关键词翻译成英文。翻译出错时使用原词。
将翻译后的英文关键词按照一定格式拼接,生成Stable Diffusion的prompt文本,例如:
1
"(((best quality))),(((ultra detailed))),(((masterpiece))),illustration," + ",".join(prompt_keywords)
TAG自动翻译:
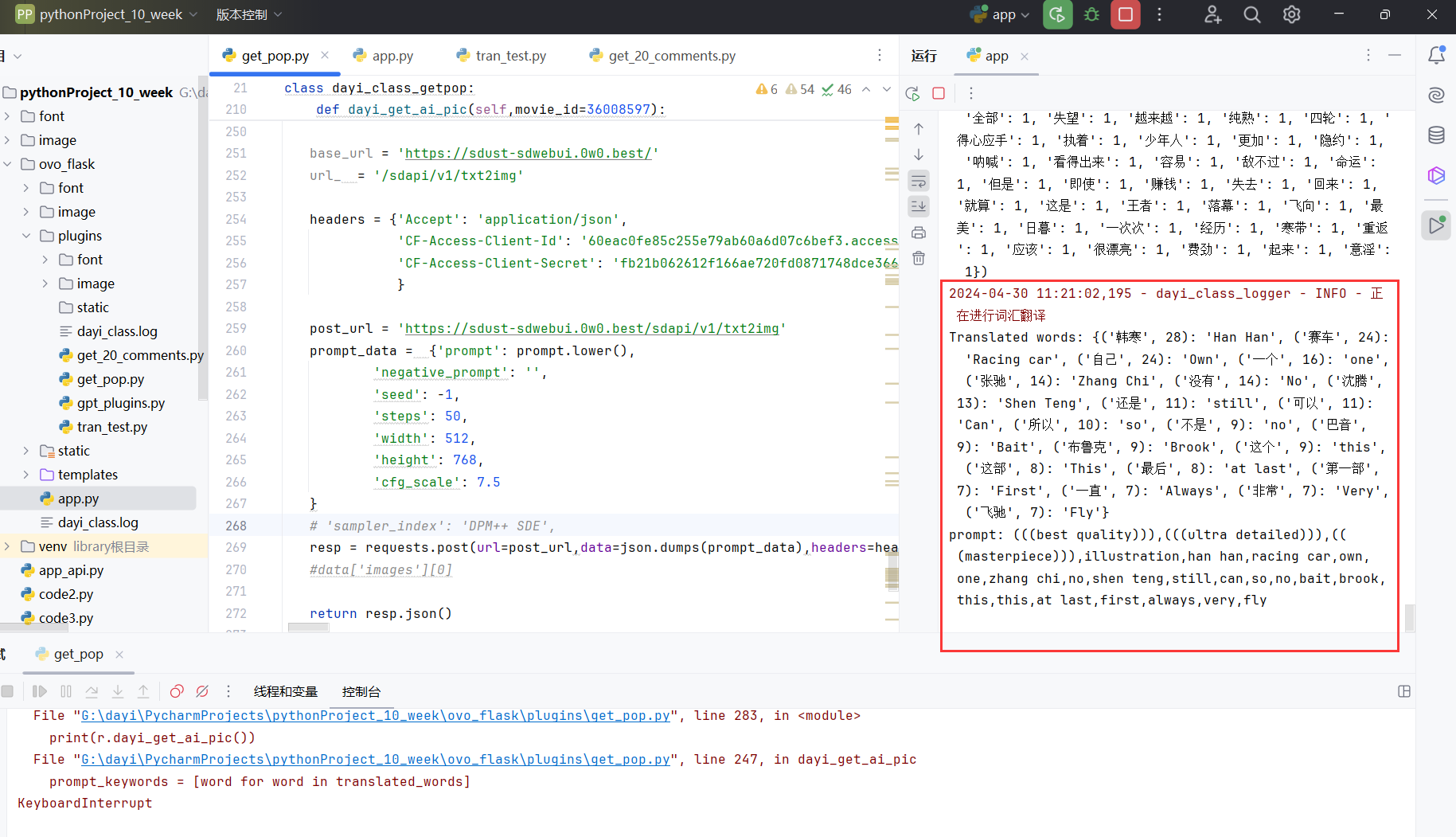
设置Stable Diffusion的inference参数,如negative_prompt,seed,steps,width,height,cfg_scale等。
向本地部署的Stable Diffusion API接口(https://sdust-sdwebui.0w0.best/sdapi/v1/txt2img 本接口由cloudflare隧道反代,通过cloudflare零信任进行认证客户端授权)发送POST请求,请求参数为第4步生成的prompt文本和第5步设置的其他参数。
零信任的授权可以直接塞headers里
接口返回base64编码的图片数据,对其进行解码并返回数据
具体的过程如图:
通过豆瓣影评关键词提取,中英互译,自动生成Stable Diffusion的prompt,实现了根据电影评论自动生成相关插画的功能。生成的插画效果好坏很大程度上取决于prompt设计的合理性以及Stable Diffusion模型的生成能力。
不过实际上还不错:
这个是特斯拉大战猩球崛起好像是
更多的AI图
只是样例啦。
华强买瓜

星际穿越


词云: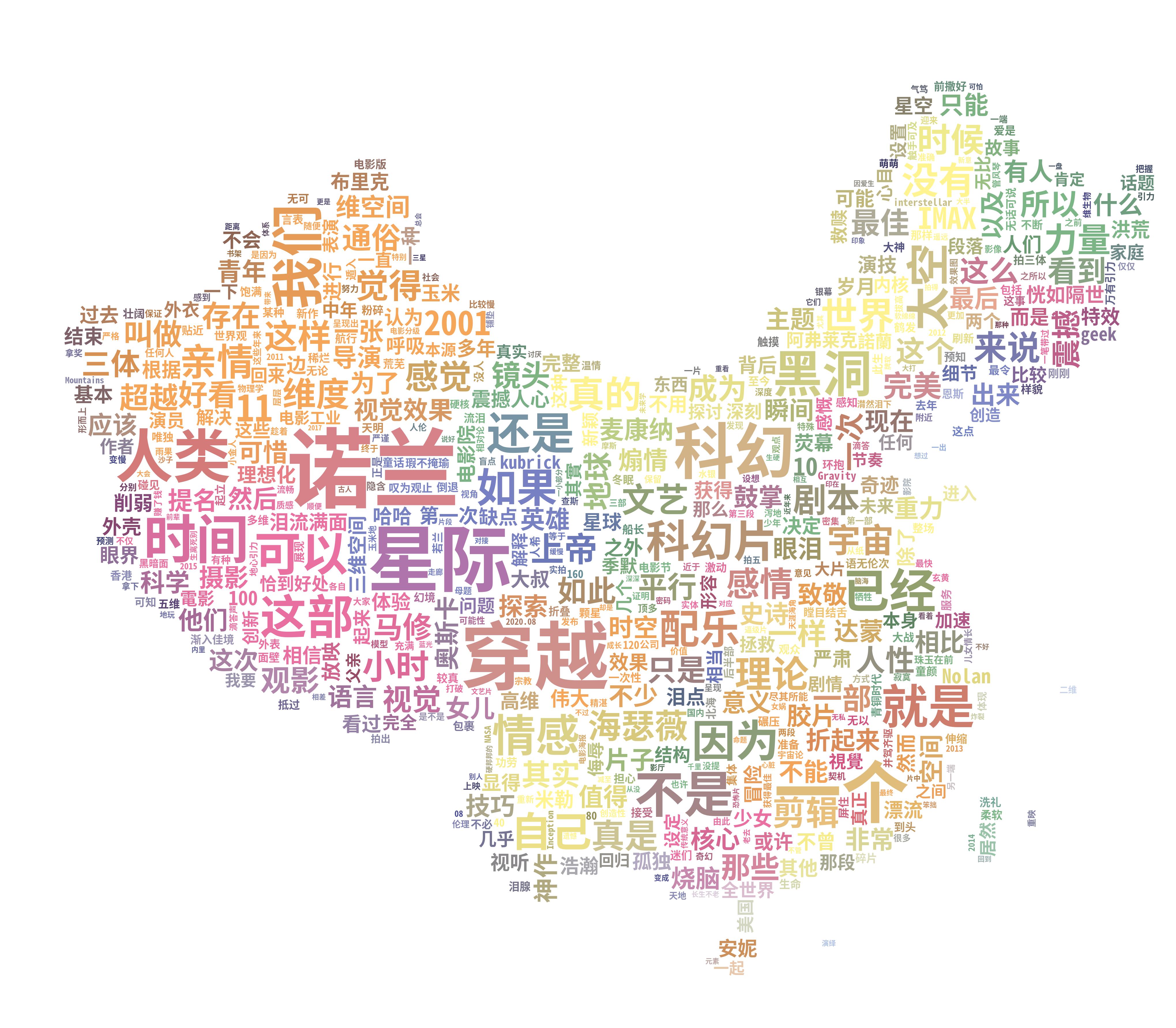
熊出没逆转时空

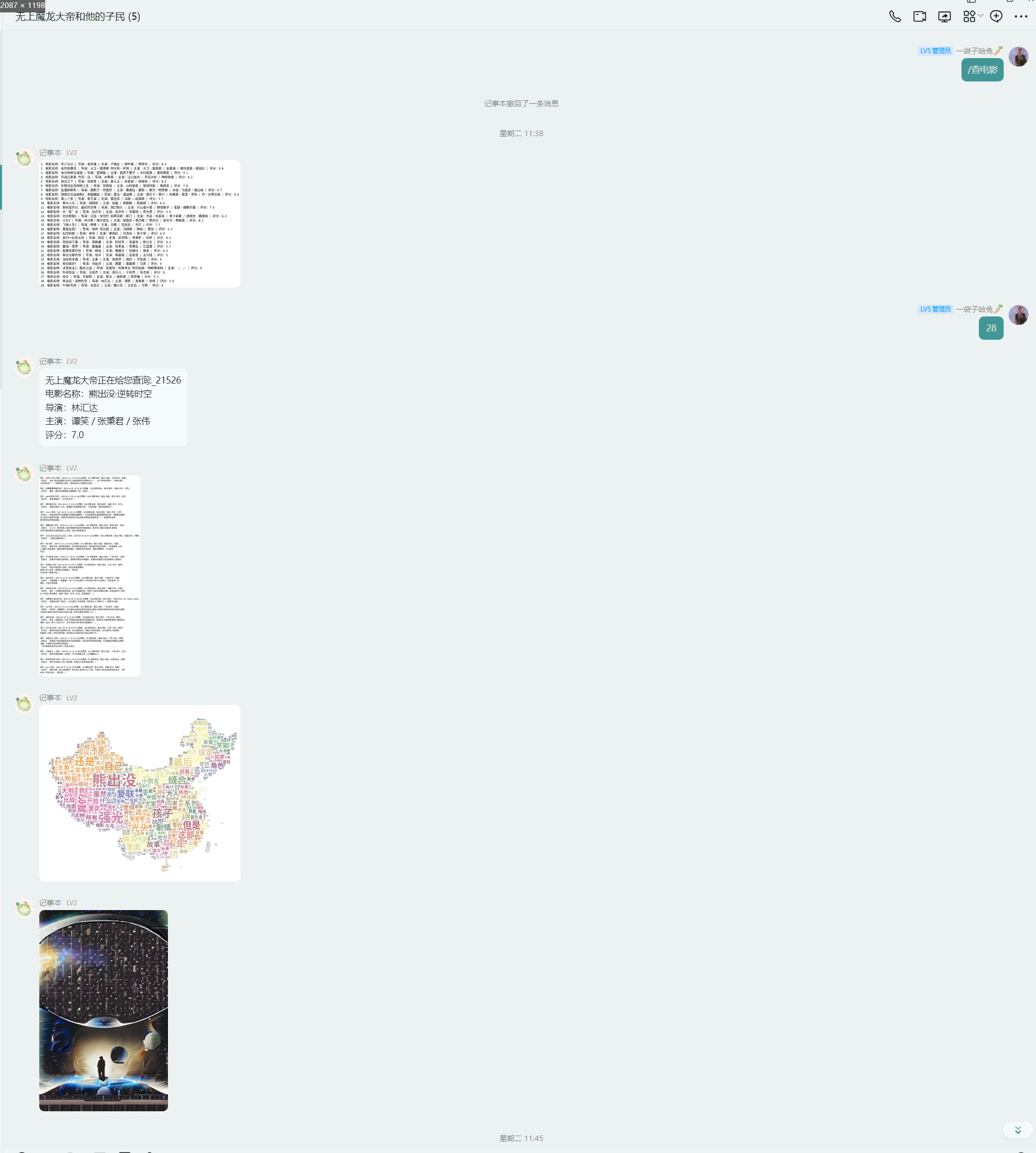
间谍过家家

哈尔滨的移动城堡
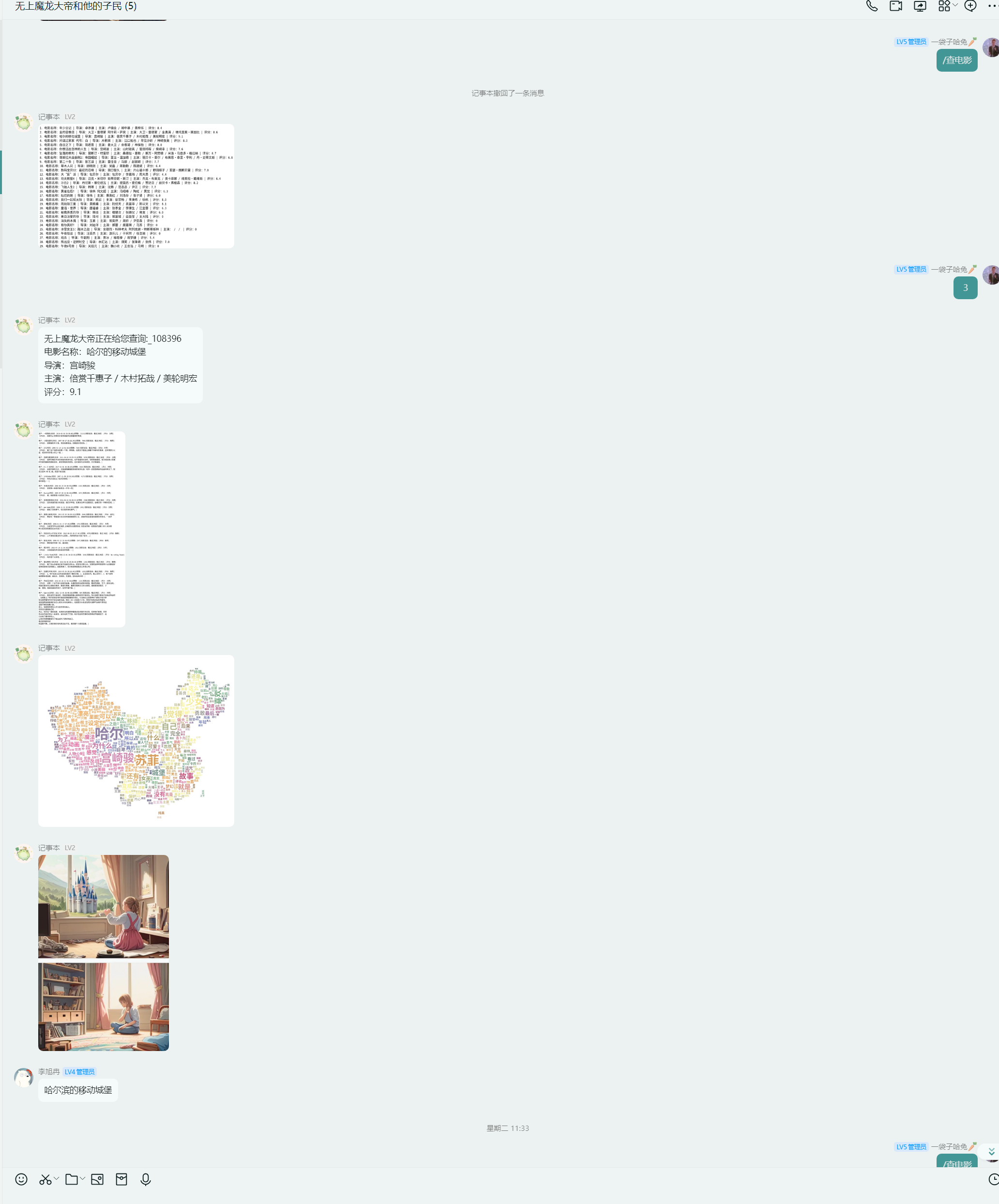
黄雀在后
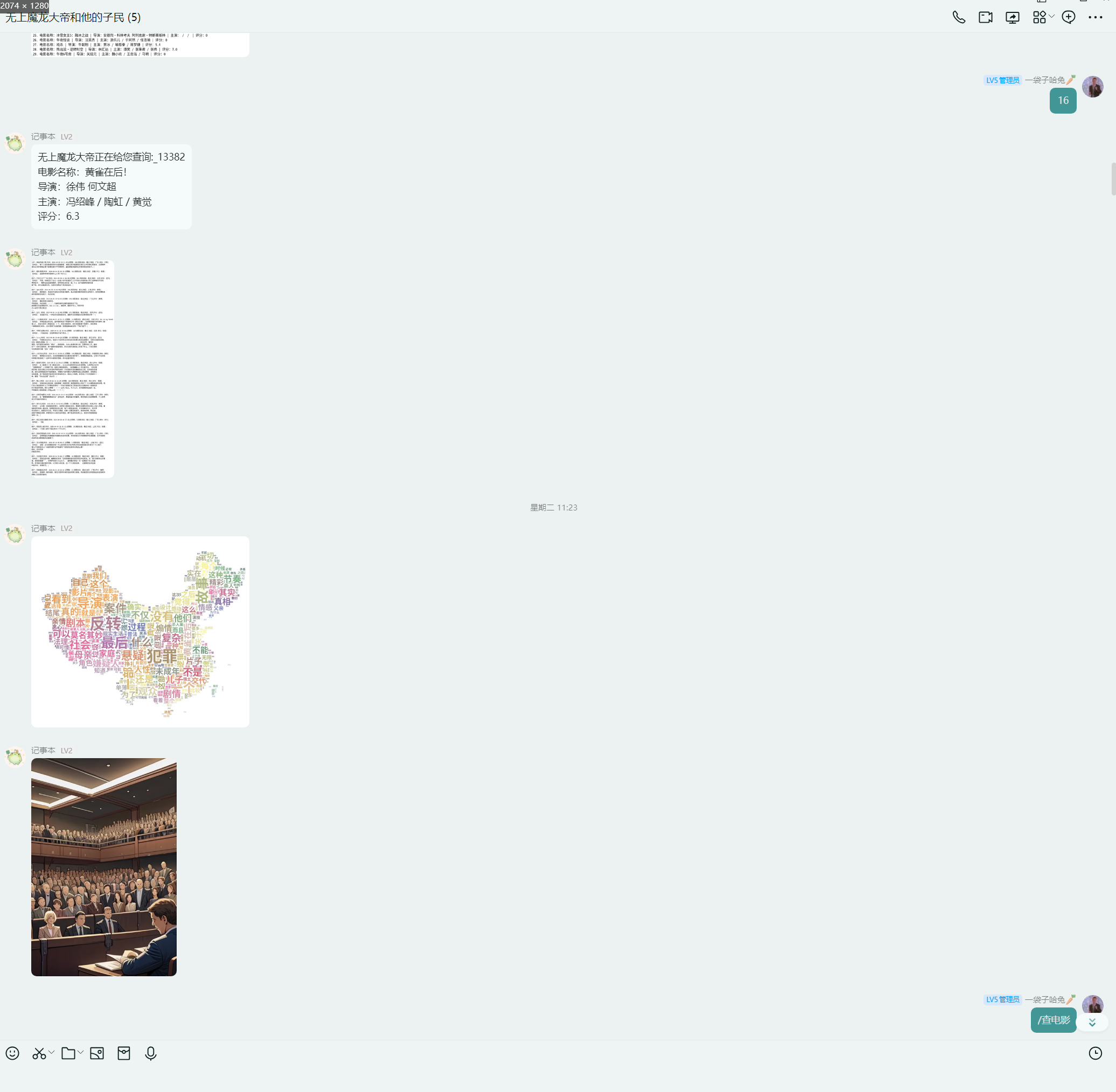
飞驰人生2
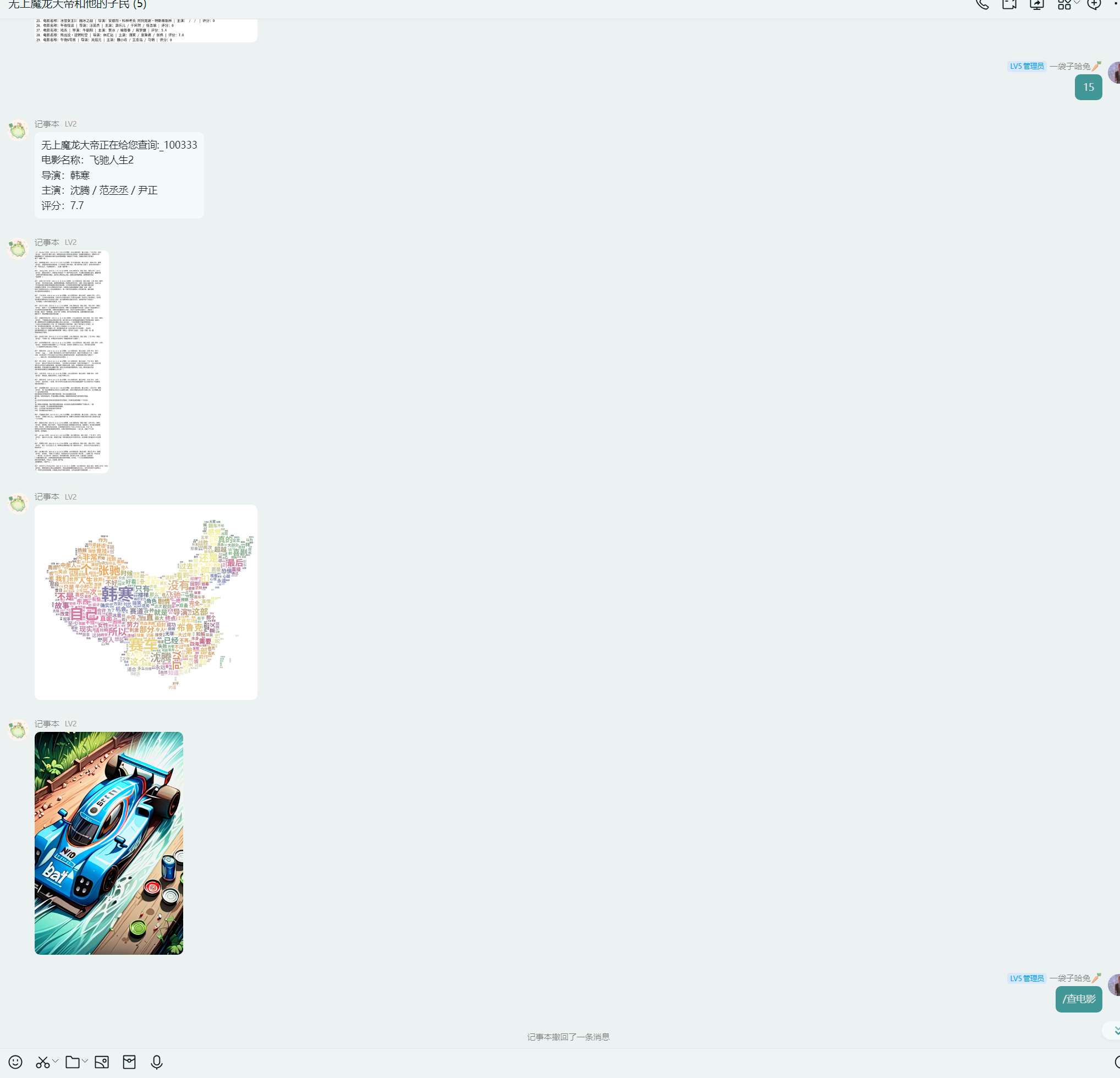
QQ机器人实现
使用的graia(多组件组成,主要是AGLP3.0 https://github.com/GraiaProject/ )框架,该框架基于开源项目mirai-http-api(AGLP3.0 https://github.com/project-mirai/mirai-api-http ),然后以插件形式接入mirai(AGLP3.0 https://github.com/mamoe/mirai ) 通过overflow(https://github.com/MrXiaoM/overflow AGLP3.0)然后接入onebot V11(协议)接到LLOneBot。
正因为这个嵌套,反而是每步可以支持了更多的协议,其实完全可以直接接入钉钉、企业微信、kook等。
具体的代码还是看下附录,这里简单写一下。
查询逻辑
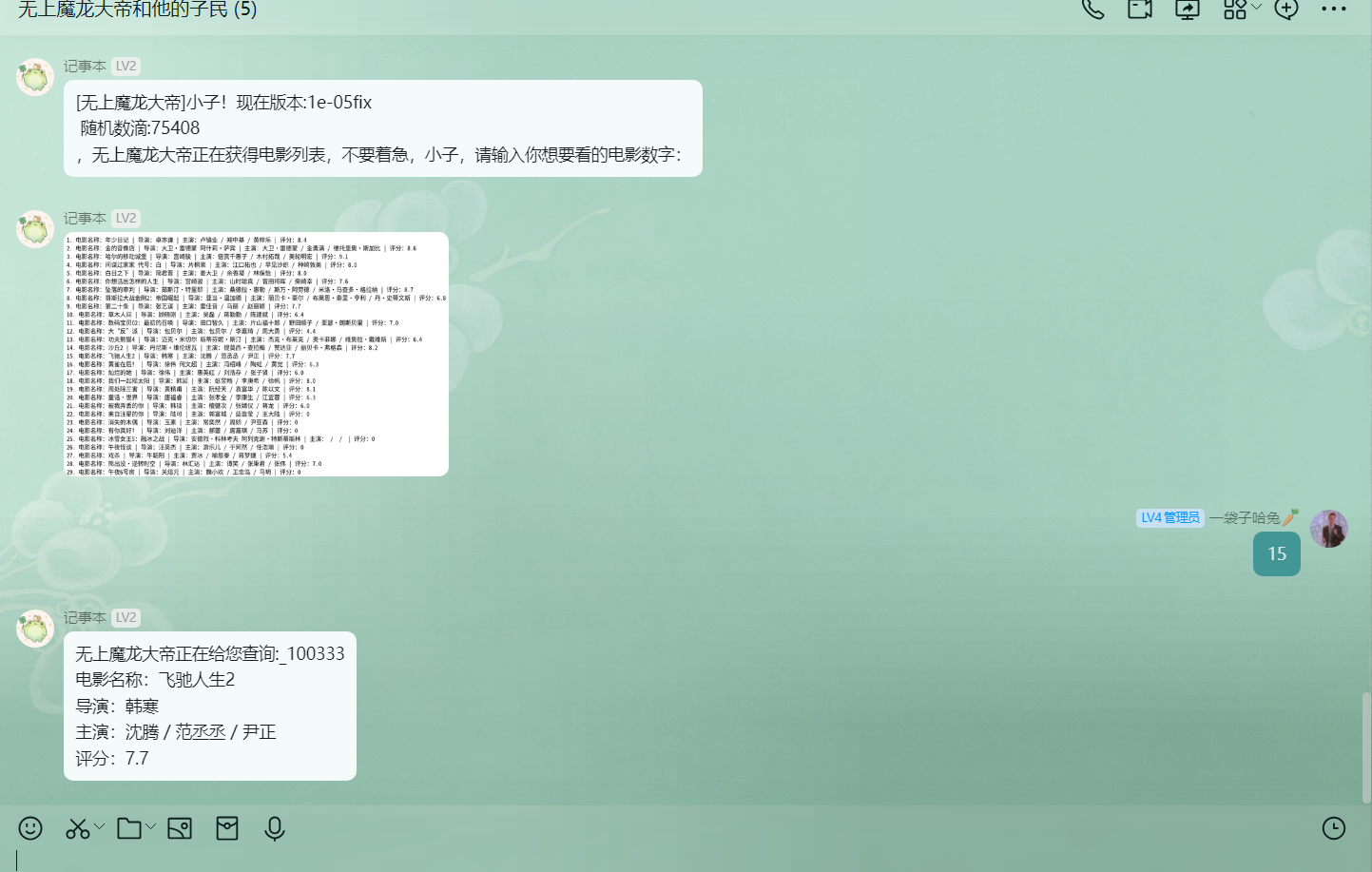
/查电影
1 | [无上魔龙大帝]小子!现在版本:1e-05fix |
选择查询的电影

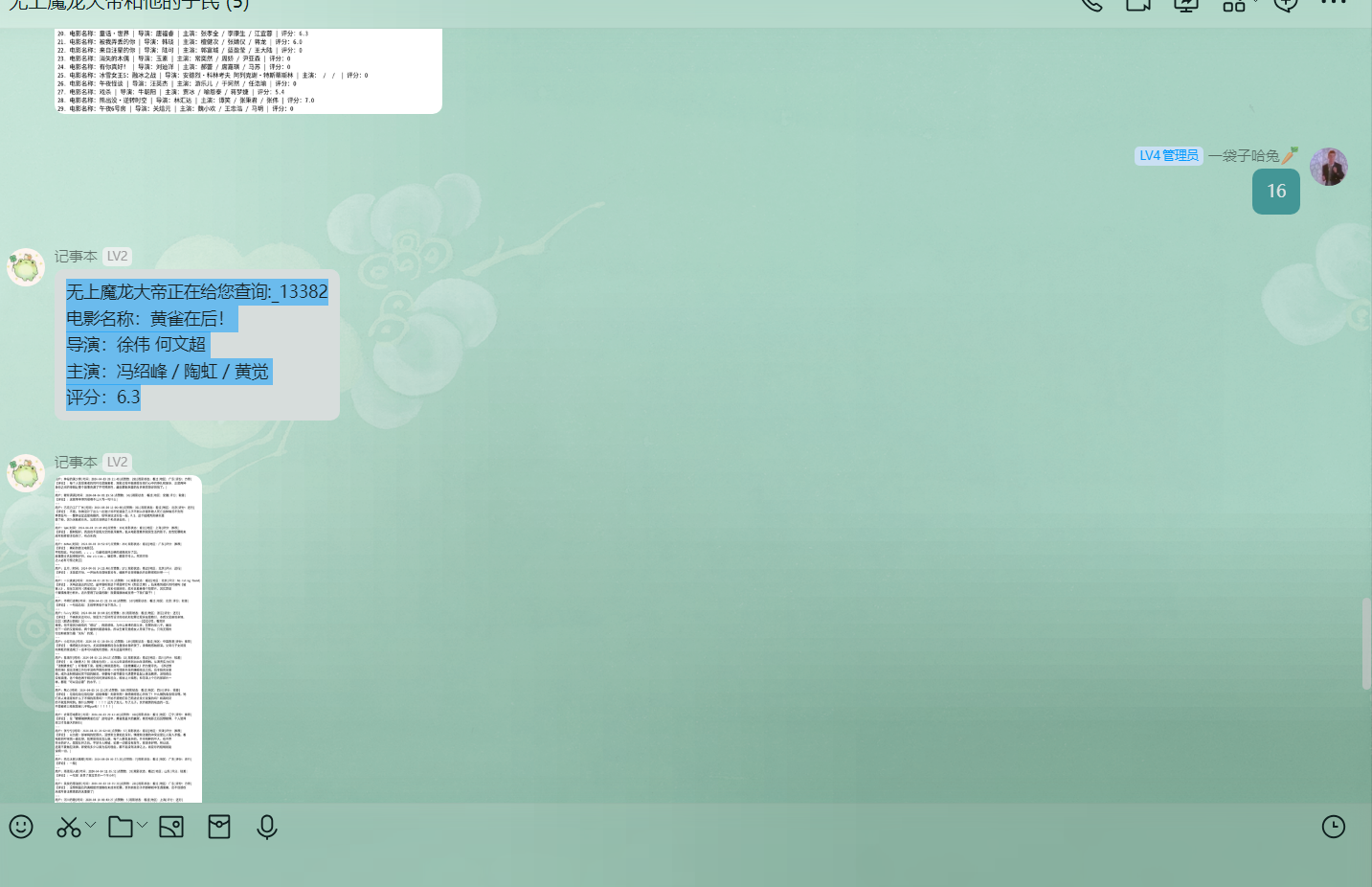
1 | 无上魔龙大帝正在给您查询:_13382 |
先发送评论信息

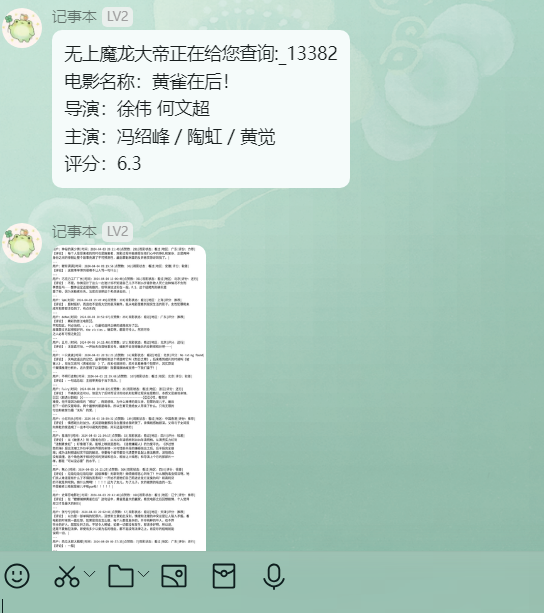
然后调用flask的API发送词云
这个图有精心调过,你会发现其实挺好看的。

最后发送SDXL根据关键词TAG生成出来的图片
比如猩球崛起:


AI画图
AI 画图调用,发送的图实际上都是base64
查询逻辑代码
1 | from modules.jerry_ask.query_movie import dayi_movie_query |
错误输出
实际运行的时候很难说不出现一点错误,所以还是有错误提示的。

类逻辑
其实看这个小图就可以看明白大概!
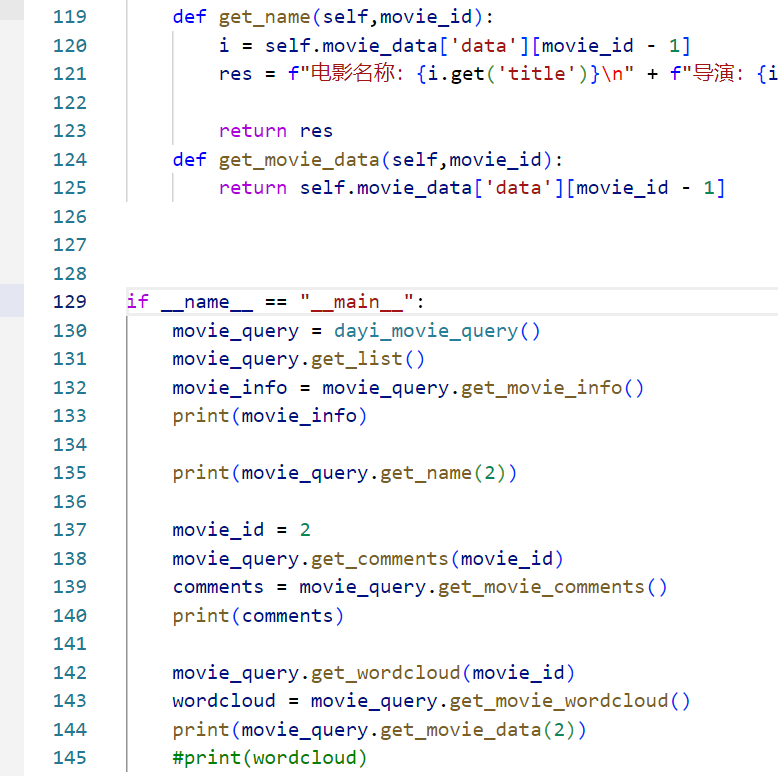
把API调用稍微封装一下,然后直接调用python的类就可以实现全部的功能,这样同时可以有助于多线程、异步稳定性,而且封起来可以提升写代码的幸福感哦~
类逻辑:具体的
封装了与电影数据相关的各种操作,包括获取热门电影列表、获取电影评论、生成评论词云以及调用AI绘图接口生成电影相关的图片。通过将这些功能封装在一个类中,我们可以更方便地管理和调用这些功能,同时也提高了代码的可读性和可维护性。
dayi_movie_query类的主要方法及其功能:
get_list(self):- 发送GET请求到指定的API接口(
http://127.0.0.1:9999/api/get_popular_movie),获取热门电影列表。 - 解析返回的JSON数据,提取电影信息,并将其格式化为字符串。
- 将格式化后的电影信息存储在
movie_info_str实例变量中。
- 发送GET请求到指定的API接口(
get_comments(self, movie_id):- 根据给定的电影ID,发送GET请求到指定的API接口(
http://127.0.0.1:9999/api/get_comments/{movie_id}),获取该电影的评论数据。 - 解析返回的JSON数据,提取评论信息,并将其格式化为字符串。
- 将格式化后的评论信息存储在
comments实例变量中。
- 根据给定的电影ID,发送GET请求到指定的API接口(
get_wordcloud(self, movie_id):- 根据给定的电影ID,发送GET请求到指定的API接口(
http://127.0.0.1:9999/api/get_wordcloud/{movie_id}),获取该电影评论的词云数据。 - 解析返回的JSON数据,将词云数据存储在
wordcloud实例变量中。
- 根据给定的电影ID,发送GET请求到指定的API接口(
get_ai_pic(self, movie_id):- 根据给定的电影ID,发送GET请求到指定的API接口(
http://127.0.0.1:9999/api/ai_draw/{movie_id}),调用AI绘图接口生成与该电影相关的图片。 - 解析返回的JSON数据,将生成的图片URL存储在
ai_pic实例变量中。
- 根据给定的电影ID,发送GET请求到指定的API接口(
get_movie_info(self),get_movie_comments(self),get_movie_wordcloud(self):- 这些方法用于获取先前存储在实例变量中的电影信息、评论和词云数据。
get_name(self, movie_id):- 根据给定的电影ID,从电影数据中提取电影名称、导演、主演和评分信息,并将其格式化为字符串。
get_movie_data(self, movie_id):- 根据给定的电影ID,从电影数据中获取该电影的完整数据。
API接口
概述
此API是基于Flask框架构建的Web服务,用于提供与电影相关的信息,包括当前热映电影列表、电影评论、词云生成以及AI生成图像的功能。API通过调用前面定义的dayi_class_getpop类实例来实现这些功能。
API功能详解
1. 获取当前热映电影 (/api/get_popular_movie)
功能:返回当前热映电影的列表。
方法:GET
参数:无
实现:
- 调用
get_now_playing_movies方法获取电影数据。 - 如果成功,将电影数据返回给客户端;如果发生异常,返回错误代码和错误信息。
- 调用
请求方法:GET
返回格式:
- 成功返回:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23{
"code": "200",
"data": [
{
"title": "电影标题",
"score": "评分",
"release_year": "上映年份",
"duration": "时长",
"region": "制片地区",
"director": "导演",
"actors": ["演员1", "演员2"],
"category": ["类别1", "类别2"],
"enough": "是否足够的评分信息",
"showed": "是否已上映",
"star": "星级",
"subject": "电影ID",
"votecount": "投票数",
"poster_url": "海报链接",
"img_url": "图片链接",
"ticket_url": "购票链接"
}
]
}- 错误返回:
1
2
3
4{
"code": "400",
"data": "错误信息描述"
}
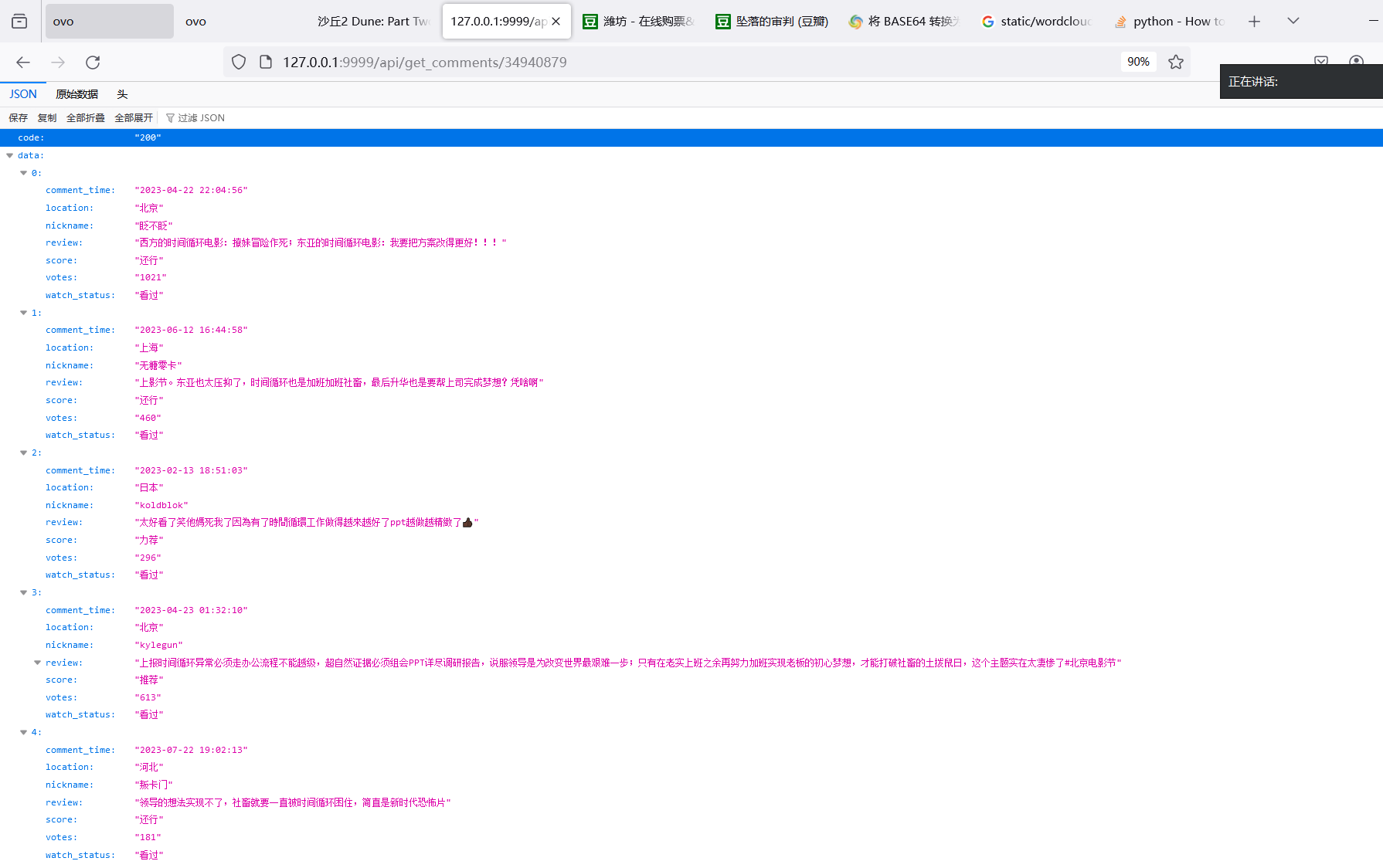
2. 获取电影评论 (/api/get_comments/<int:movie_id>)
功能:根据电影ID返回该电影的前20条评论。
方法:GET
参数:
- movie_id (int): 电影的唯一标识符。
实现:
- 调用
get_top_20_comments方法,传入电影ID。 - 如果成功,将评论数据返回给客户端;如果发生异常,返回错误代码和错误信息。
- 调用
请求方法:GET
返回格式:
- 成功返回:
1
2
3
4
5
6
7
8
9
10
11
12
13
14{
"code": "200",
"data": [
{
"review": "评论内容",
"nickname": "评论者昵称",
"score": "评分等级",
"votes": "赞同数",
"watch_status": "观影状态",
"comment_time": "评论时间",
"location": "评论者地点"
}
]
}- 错误返回:
1
2
3
4{
"code": "400",
"data": "错误信息描述"
}
3. 获取词云图片 (/api/get_wordcloud/<int:movie_id>)
功能:根据电影ID生成该电影评论的词云,并以Base64编码的图片形式返回。
方法:GET
参数:
- movie_id (int): 电影的唯一标识符。
实现:
- 调用
generate_word_cloud方法,传入电影ID,获取词云图片的路径。 - 将图片文件读取为二进制数据,然后进行Base64编码。
- 如果成功,将编码后的图片数据返回给客户端;如果发生异常,返回错误代码和错误信息。
- 调用
请求方法:GET
返回格式:
- 成功返回:
1
2
3
4{
"code": "200",
"data": "Base64编码的图片数据"
}- 错误返回:
1
2
3
4{
"code": "400",
"data": "错误信息描述"
}
4. AI绘图 (/api/ai_draw/<int:movie_id>)
功能:根据电影ID使用AI技术生成相关图像,并返回生成结果。
方法:GET
参数:
- movie_id (int): 电影的唯一标识符。
实现:
- 调用
dayi_get_ai_pic方法,传入电影ID,获取AI生成的图像数据。 - 如果成功,将图像数据返回给客户端;如果发生异常,返回错误代码和错误信息。
- 调用
请求方法:GET
返回格式:
- 成功返回:
1
2
3
4
5
6
7{
"code": "200",
"data": {
"image_url": "生成的图片链接",
"other_details": "其他相关信息"
}
}- 错误返回:
1
2
3
4{
"code": "400",
"data": "错误信息描述"
}
错误处理
- 在每个API调用中,异常都被捕获并处理,确保在出现问题时能提供明确的反馈给客户端。错误信息包括状态码和异常描述,有助于调试和问题追踪。
安全和性能考虑
- 安全性:API应确保所有外部输入都进行适当的验证和清理,防止注入攻击等安全风险。这可太多风险了,我有一万种方法把这个服务器干死,有几千种方法注入,有几百种方法直接拿shell。不过,就赌的,你不会来注我OVO。
- 性能:使用缓存(如在
dayi_class_getpop类中实现的)可以提高响应速度并减轻服务器负担。
结论
此API为用户提供了一系列与电影相关的服务,包括获取信息、生成词云和AI图像等。它利用了现代Web技术和数据处理技术,通过清晰的接口设计和有效的异常处理,提供了一个健壮的服务。针对未来的改进,可以考虑进一步增强安全措施并优化性能,以提供更高质量的用户体验。
API接口输出和返回
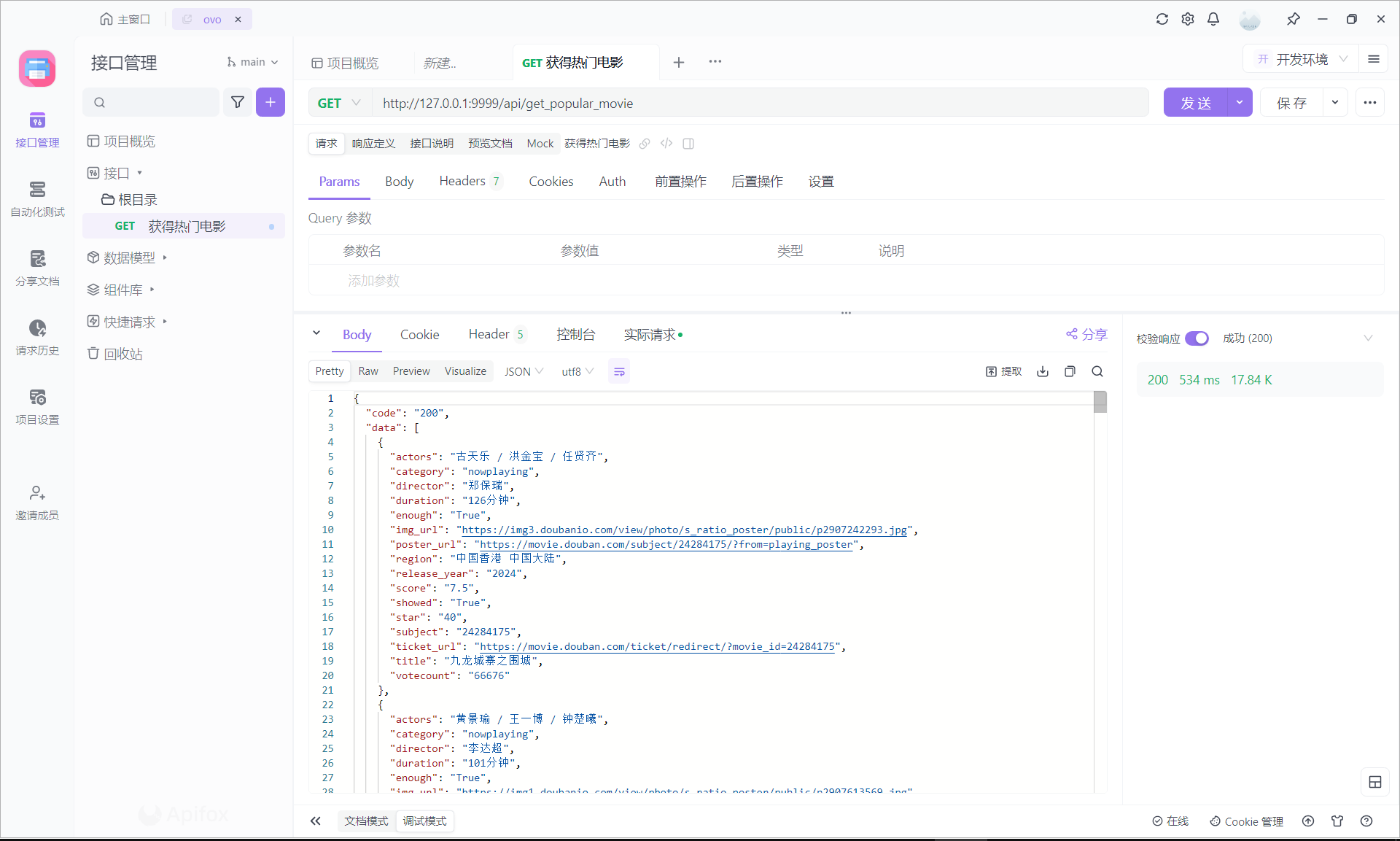
1. 获得当前热门电影/api/get_popular_movie
响应速度:534ms,因为这个接口没有用到缓存,所以我觉得已经超级快啦。
罗小黑战记ovo
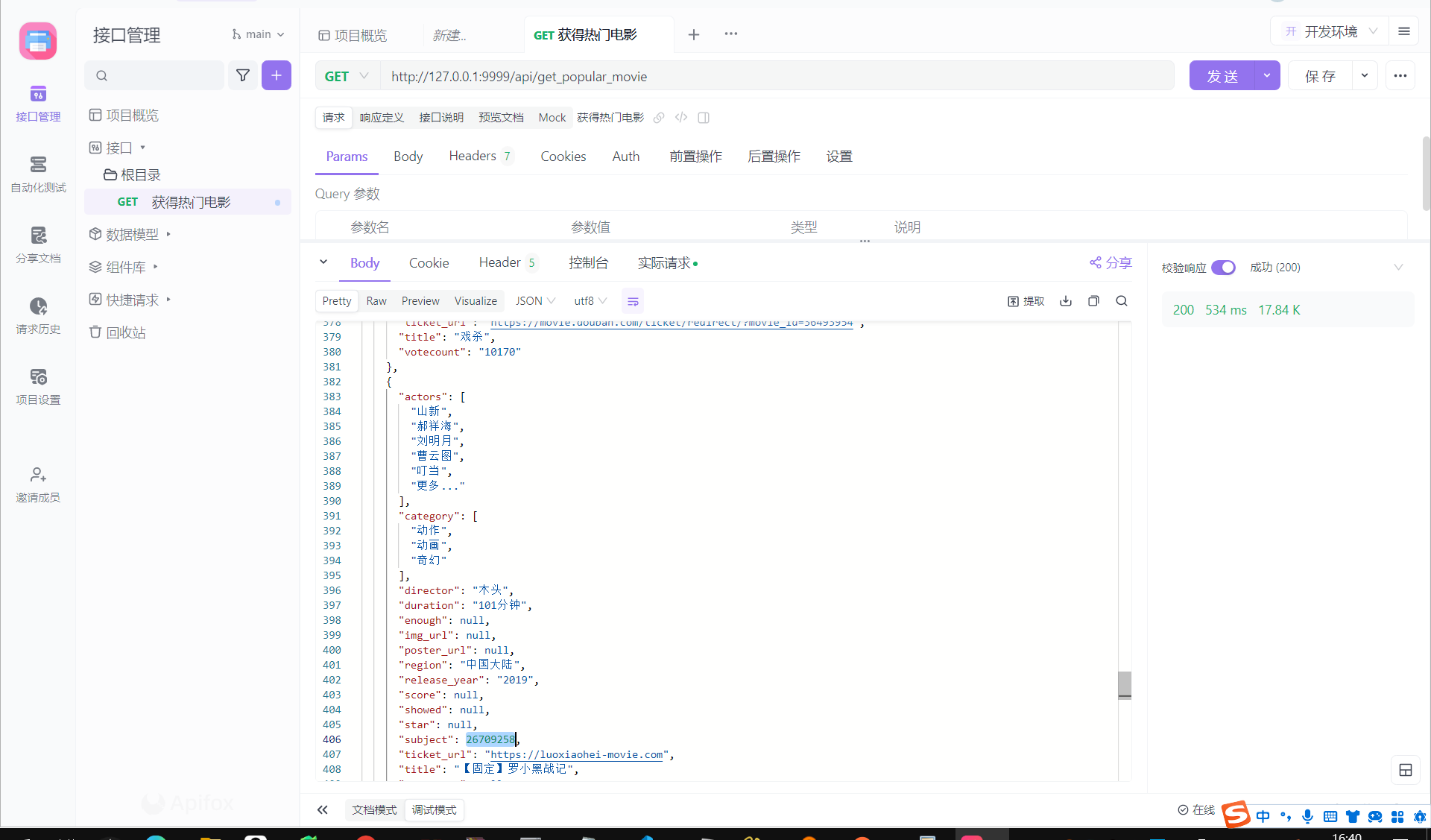
2. 获得电影的豆瓣评论 /api/get_comments/<int:movie_id>
1.31s我觉得响应速度还不错,因为后端是新的请求,现爬的。
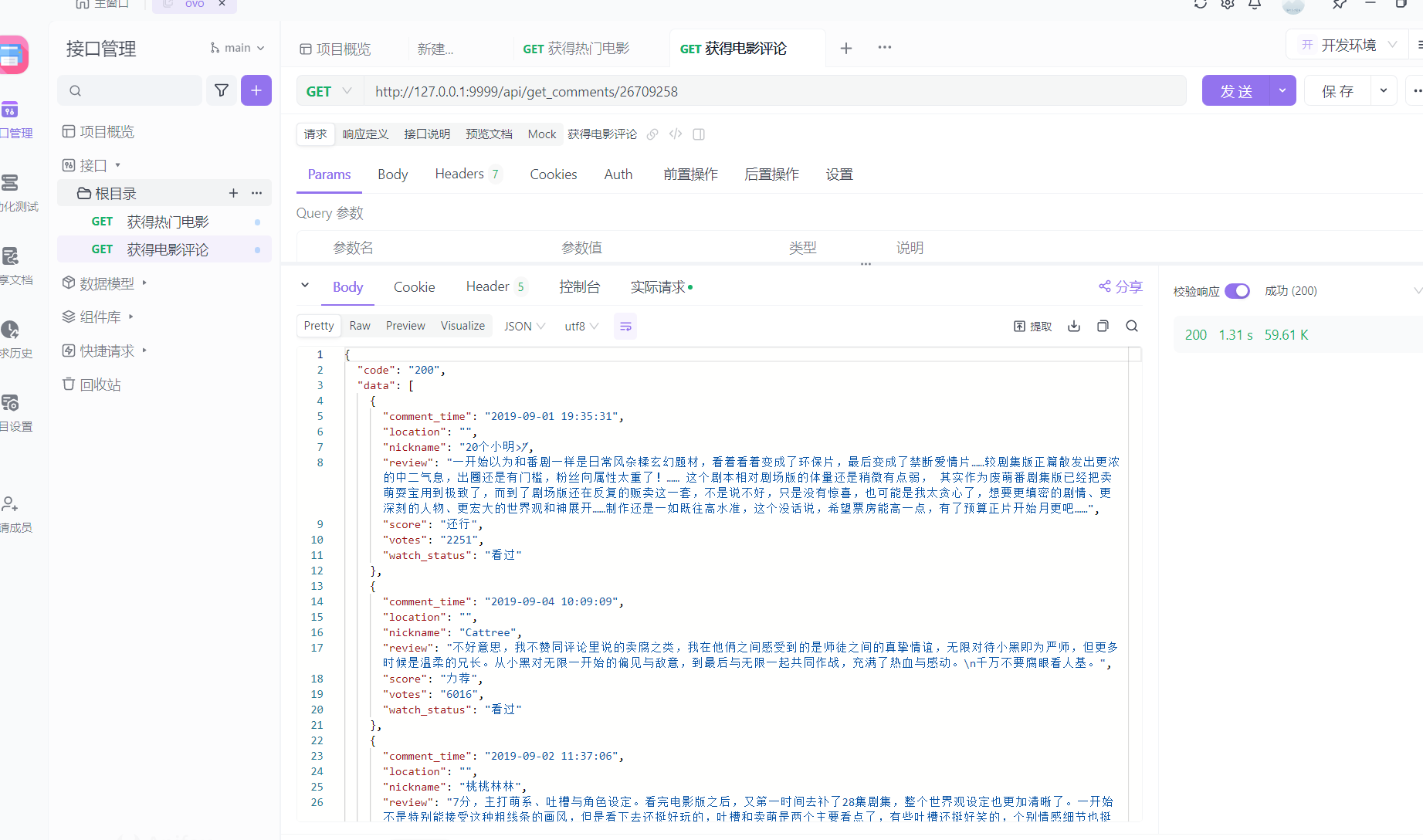
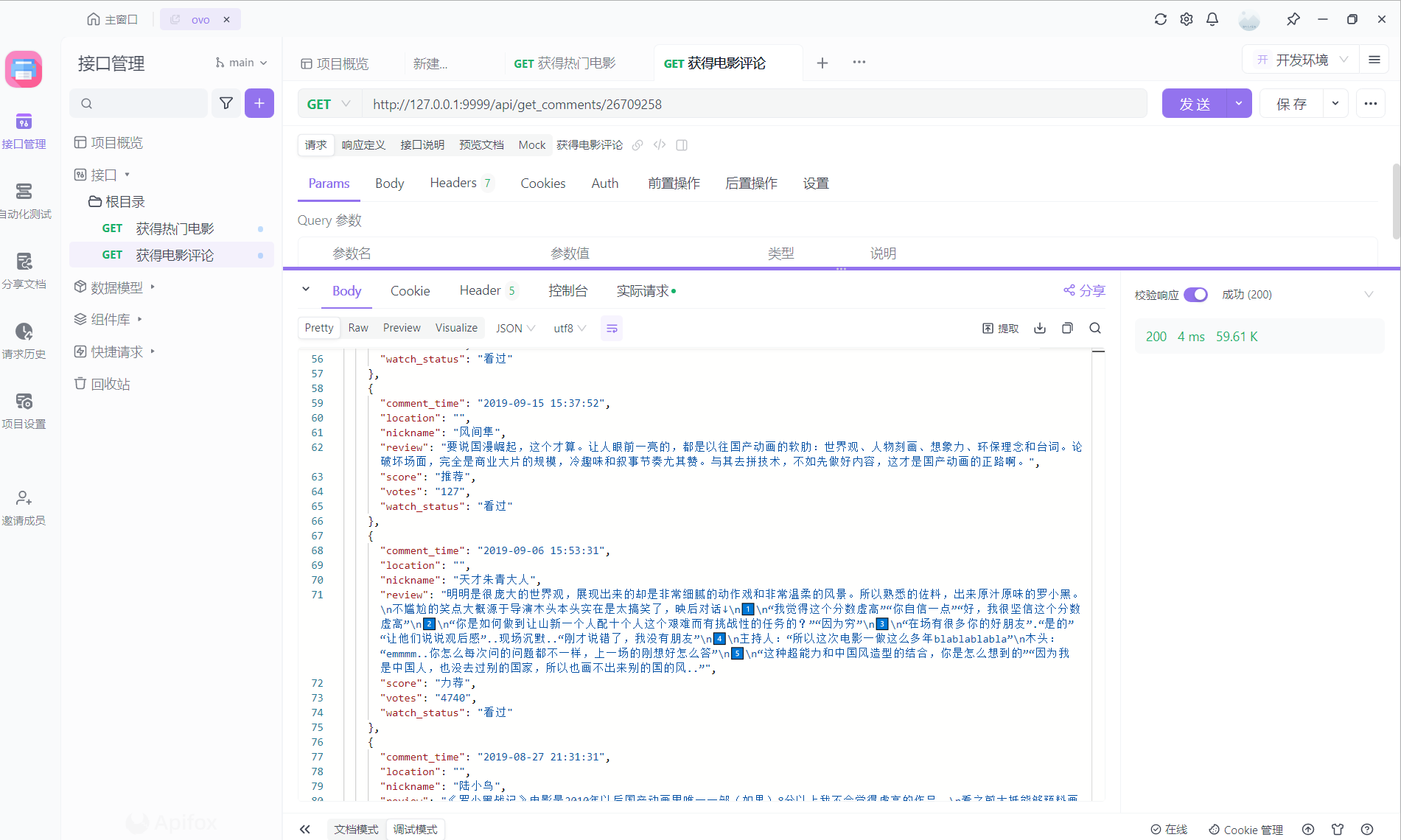
第二次请求:4ms (这个是有缓存的啦)
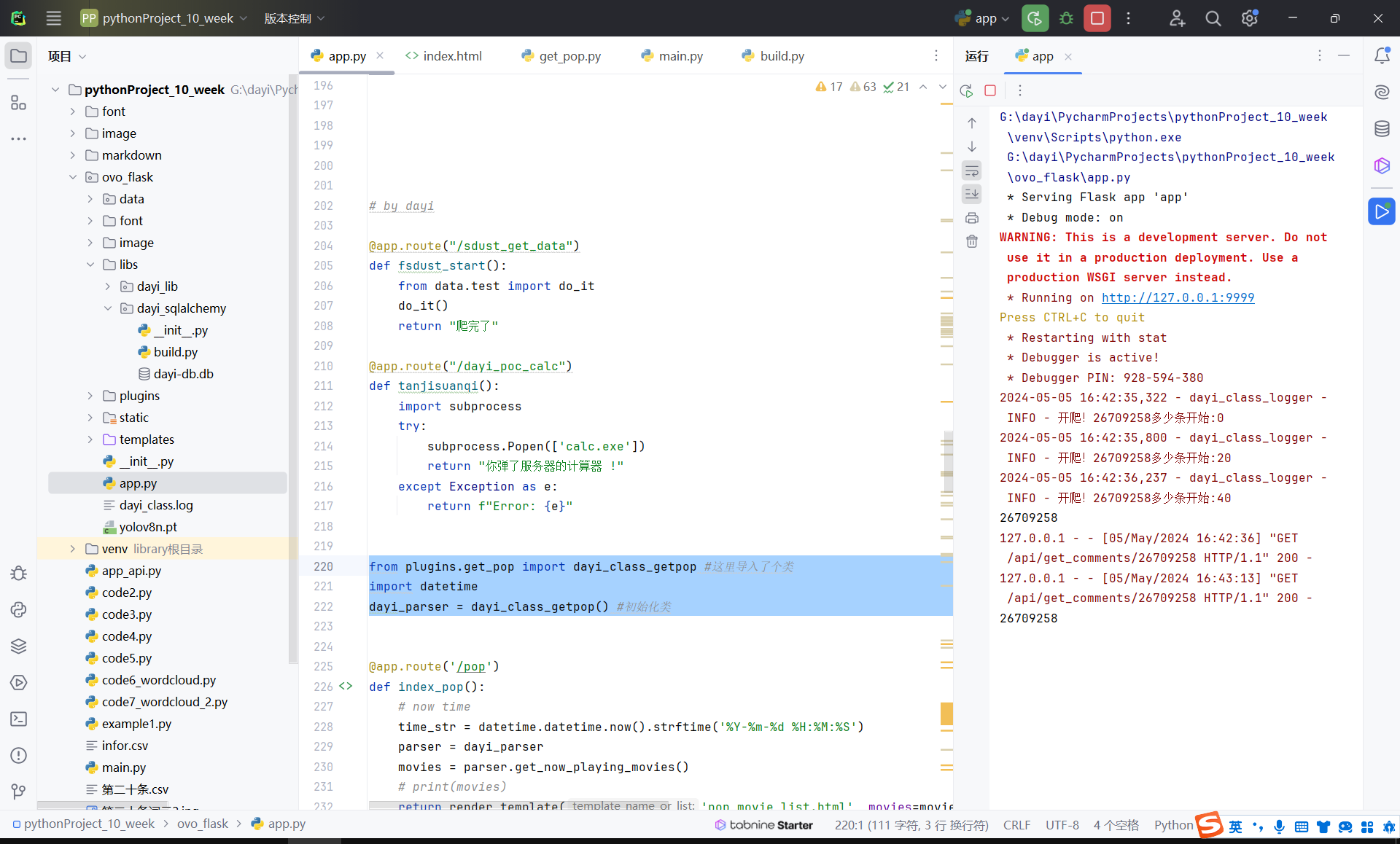
3. 获得词云 /api/get_wordcloud/<int:movie_id>
这个接口就想对较慢了,因为要分析生成图片。
13s
也算是可以接受吧,毕竟生成一个图也挺慢的。
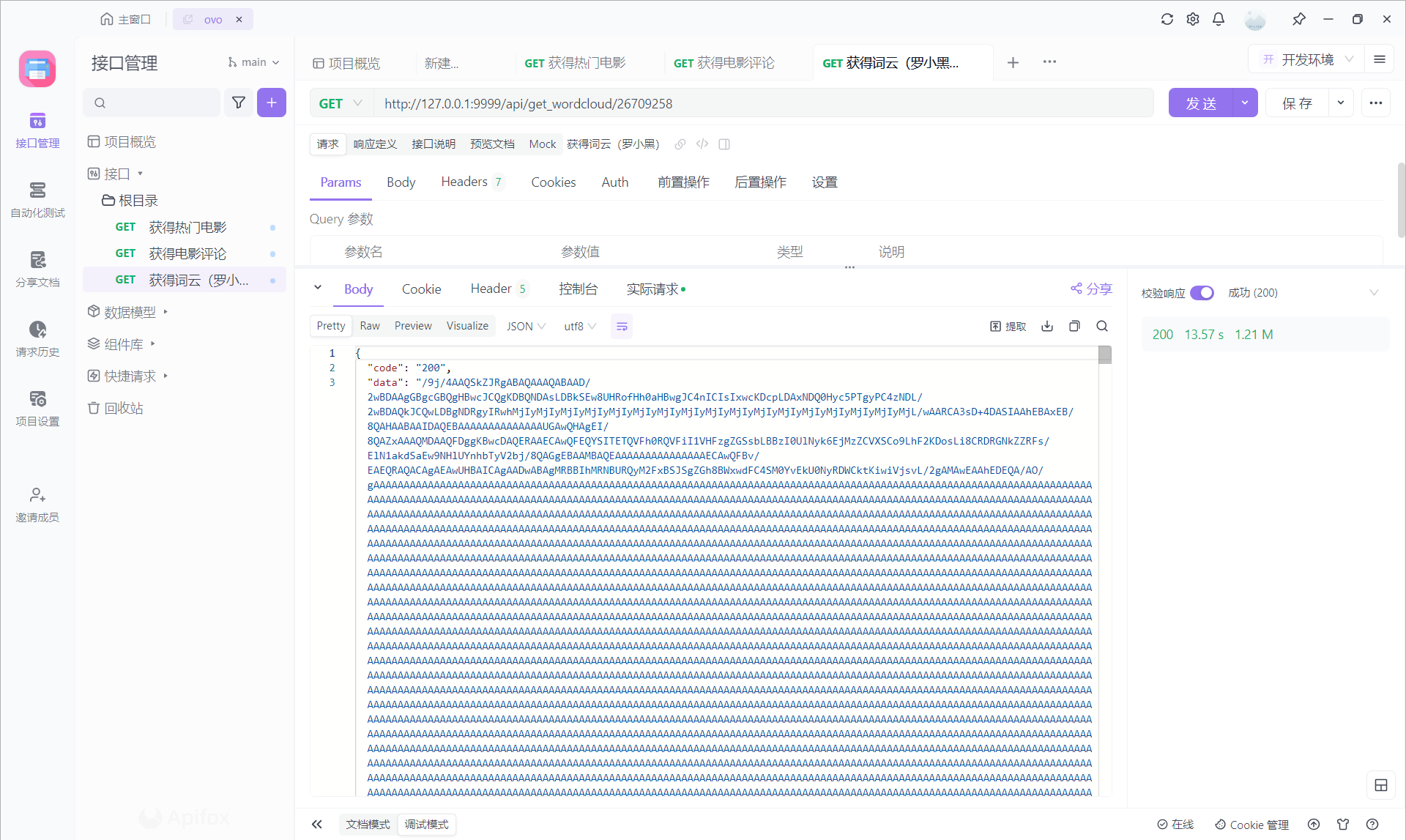
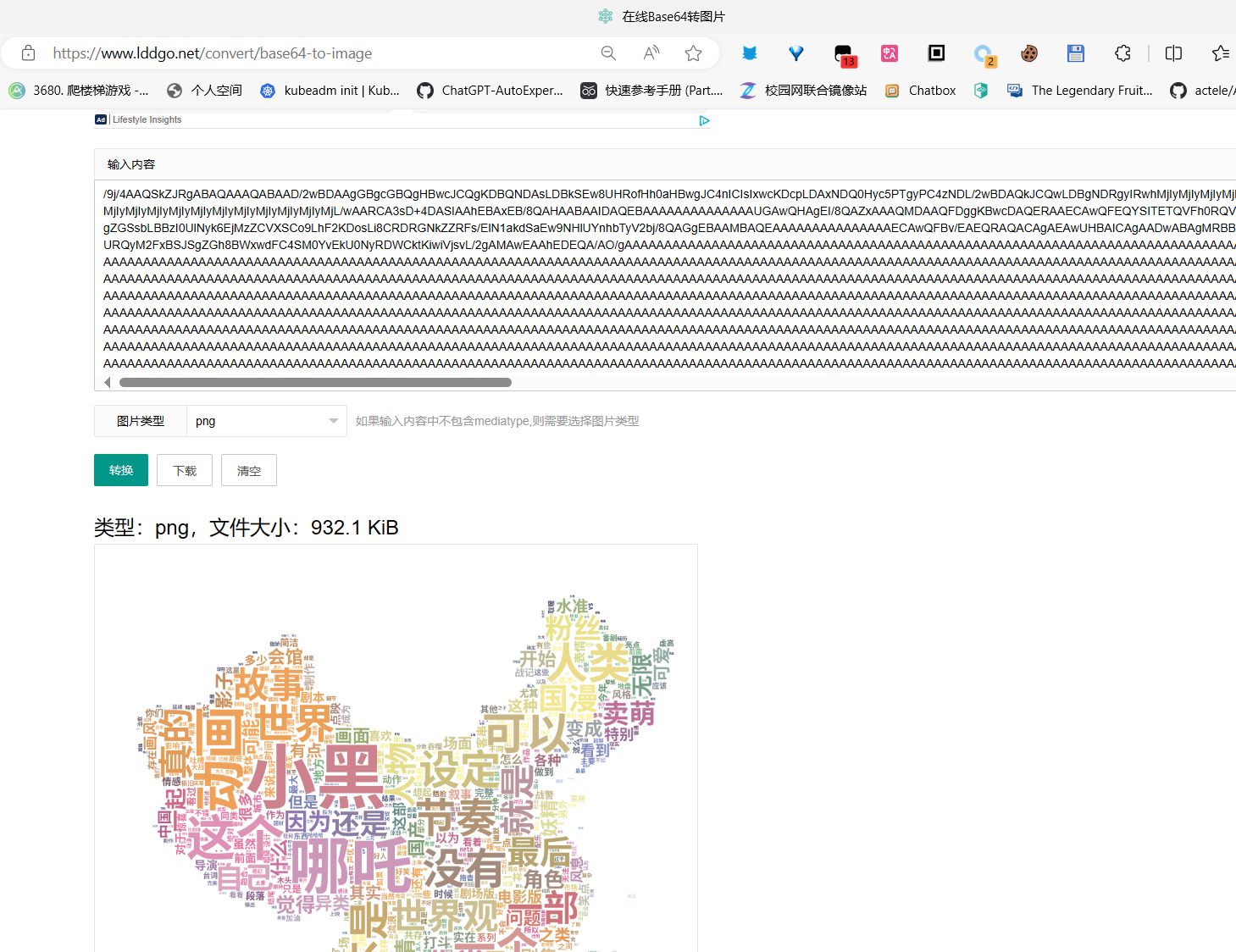
图也是没有问题哒
4. SDXL模型画图/api/ai_draw/<int:movie_id>
写文档的时候,山科的网被校外修树的锯断了。
目前没法调用哈哈哈哈哈哈。
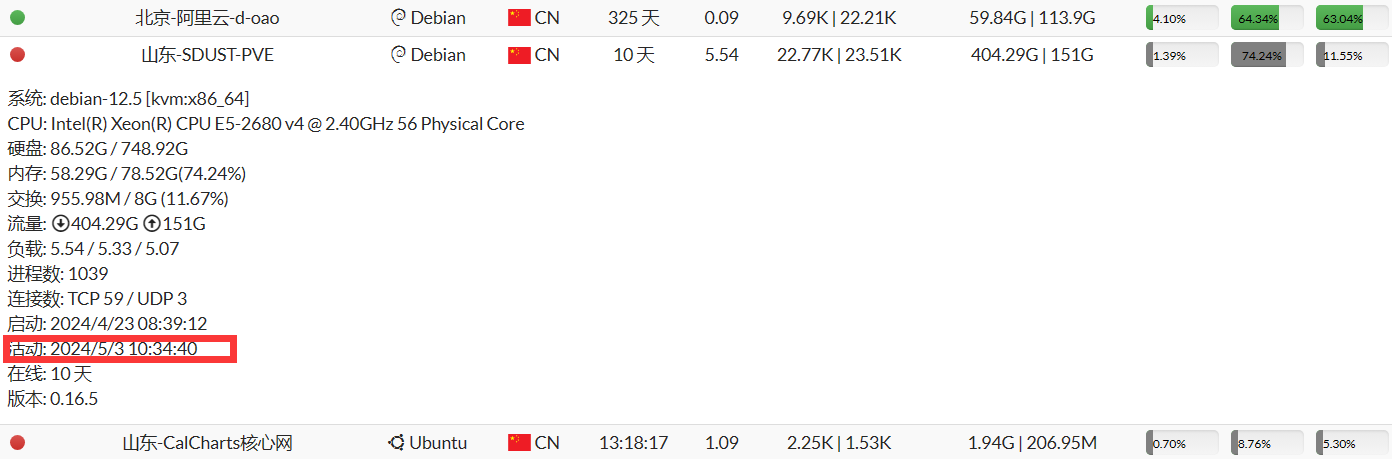
证据确凿hhhh 活动: 2024/5/3 10:34:40锯断的。
先来一个错误请求滴吧。要是交报告的时候还是修不好也没法子了,修改目前的网络架构成本巨大。
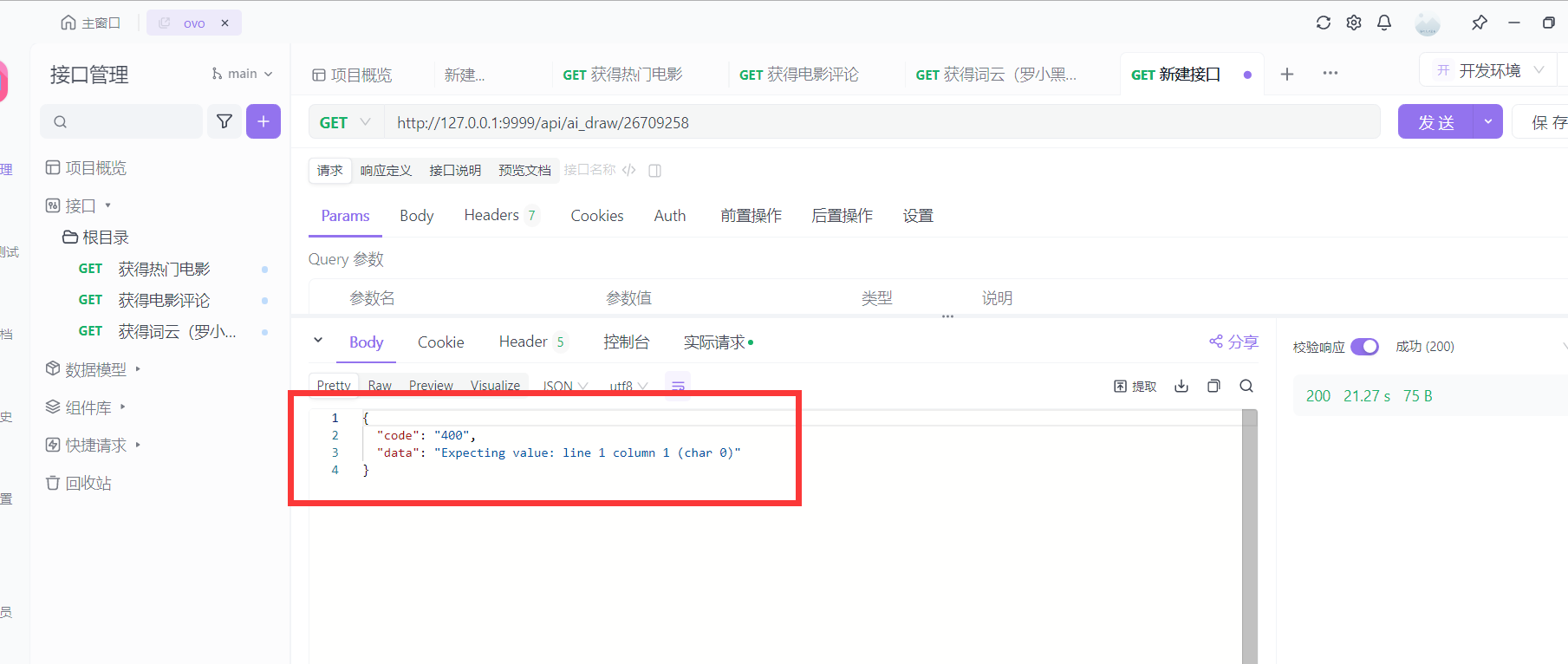
至少错误返回啦~
普通返回就是data里面套stable diffusion webui返回的数据啦。
补:先租个卡来演示吧
好高级诶
API 接口代码
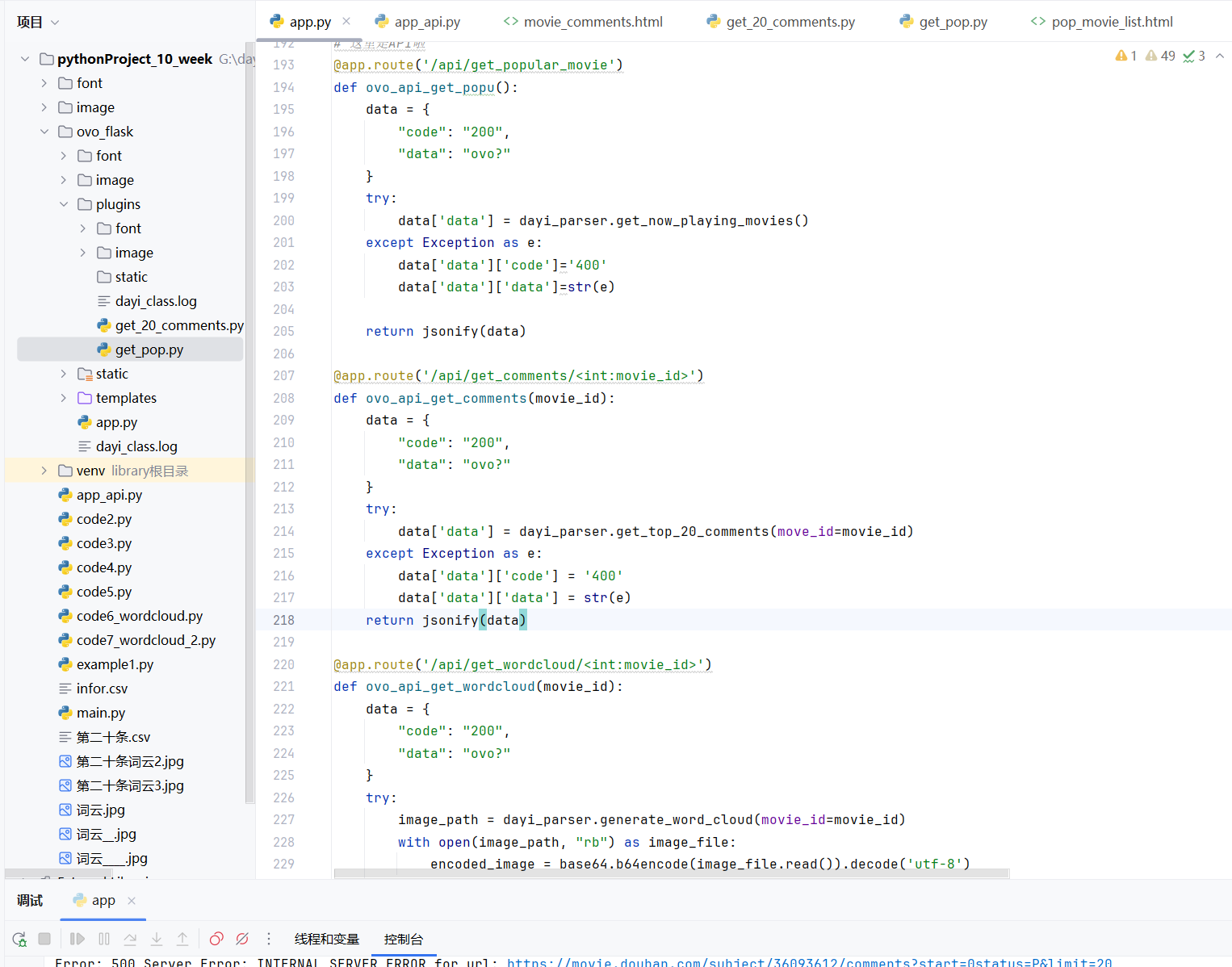
1 | # 这里是API啦 |
SDUST查新闻
爬取的这个地方:
接口设计思路
- 代码 201 表示:正常进行,并且成功
- 代码 401 表示:目标错误,未获得数据
- 代码 501 表示:程序错误,未知错误,但是可以尝试忽略错误
- 代码 202 表示:正常返回,返回值有一个或多个。
小细节
我们使用了fake_ua 来减少被服务器风控的可能性,由于只有单一IP进行访问,仍然存在不少的问题。
线程访问速度过快时,可能导致出现一定的错误,但是由于默认尝试30次,所以并不会有显著的错误,但是仍可以在10分钟内下载完约3700条以上的新闻内容。
我们团队还进行了模块的封装,将有关的函数全部封装成模块,不影响代码直接运行的同时,还可以非常方便导入函数
在封装相关的函数之后,我们可以更轻易的直接使用相关的库。最后的main函数只需要进行多线程的管理和函数的传递即可。
比如泰安校区的新闻页,标题点击量跟其他的表情不一样,我们直接重新进行适配。
对于爬虫来说:建立连接->下载数据->写入文件->保存数据。是非常重复并且占用整个时间段的大多数。我们使用了异步下载,不同的下载内容和获取内容不会相互产生明显的影响,可以进行异步。于是,我们写出了异步下载、获得页面等操作。进而提升整体的速度。
小爬虫功能文件封装
直接封装成一个小包啦!
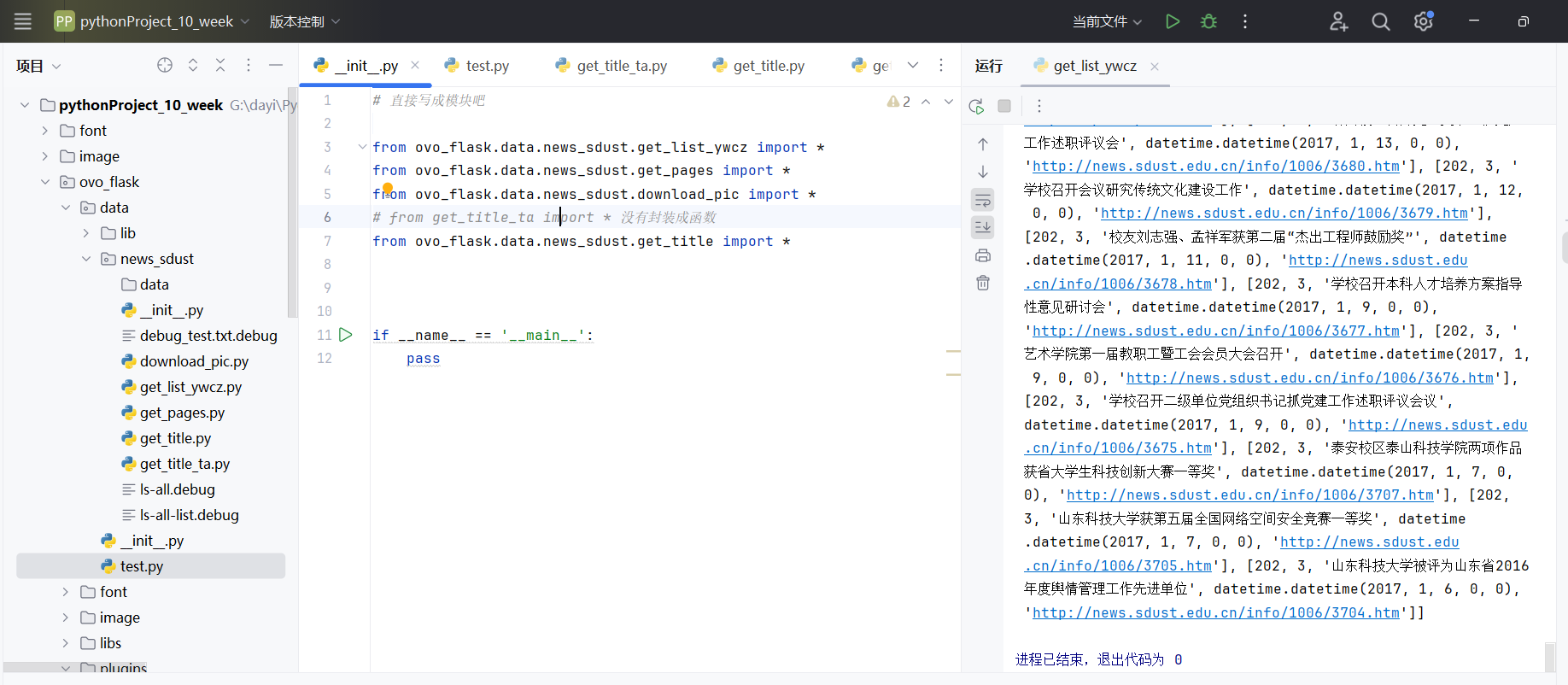
多线程爬取过程
1 | [101, '[dayi-info]不进行删除数据库'] |
32线程进行爬取,快速获得信息。
会自动爬取所有的新闻。
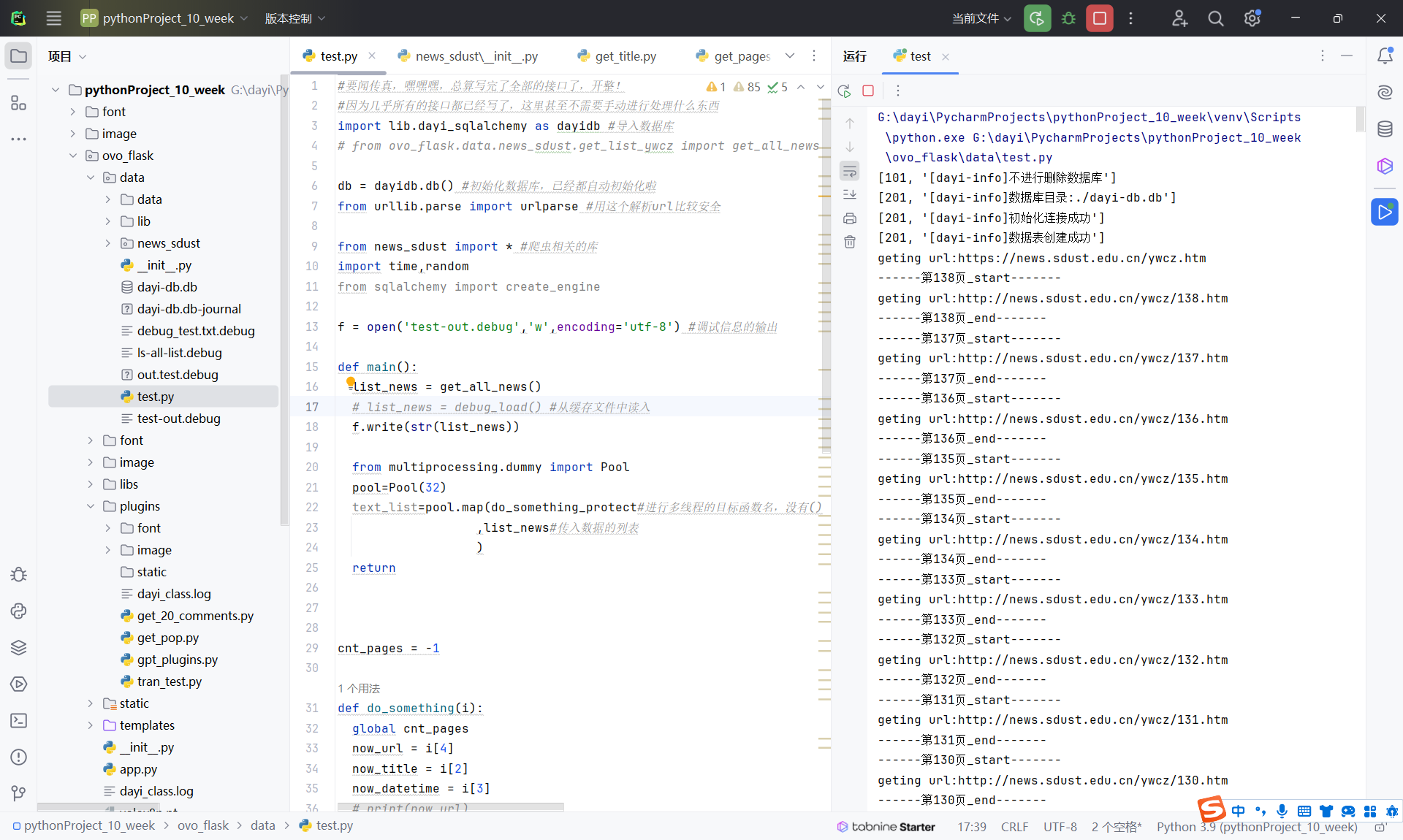
爬取完成后自动存储到数据库中,同时图片也可以看。
异步图片下载
因为下载图片比较慢,所以这里用了异步图片下载,同时结合多线程,这样整体可以以非常快的速度进行下载数据。
下载速度超级快哦
请求量的截图:
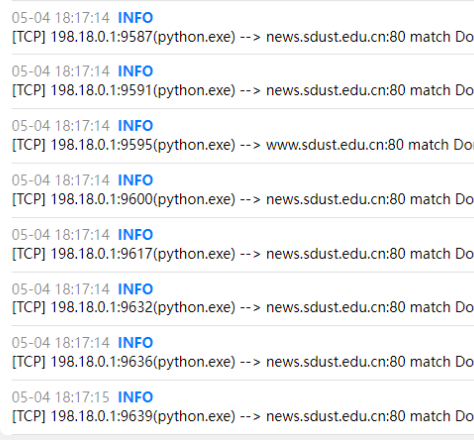
爬取过程之一: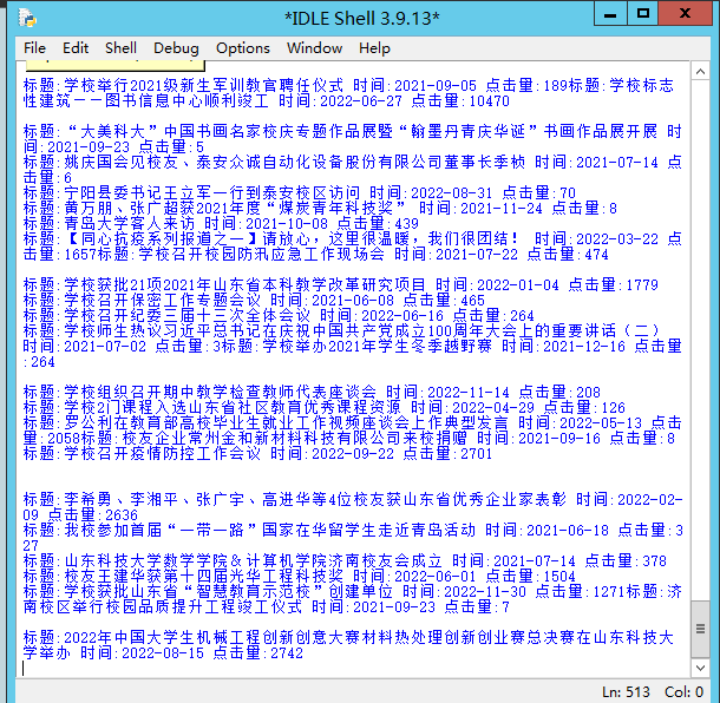
报错示例
[501, "[dayi-error]未知错误,获得页面时失败:'NoneType' object has no attribute 'find' 尝试重试次数:1"]
sdust-news爬虫包详细介绍
init.py
就是纯导入模块啦,因为稍微偷了点懒,具体的模块初始化都在每个文件里。
1 | # 直接写成模块吧 |
download_pic.py
一个异步下载啦,然后失败会自动重试4次。
1 | # 用于异步下载并保存文件 |
为了更好的排版:具体的代码请见附录!
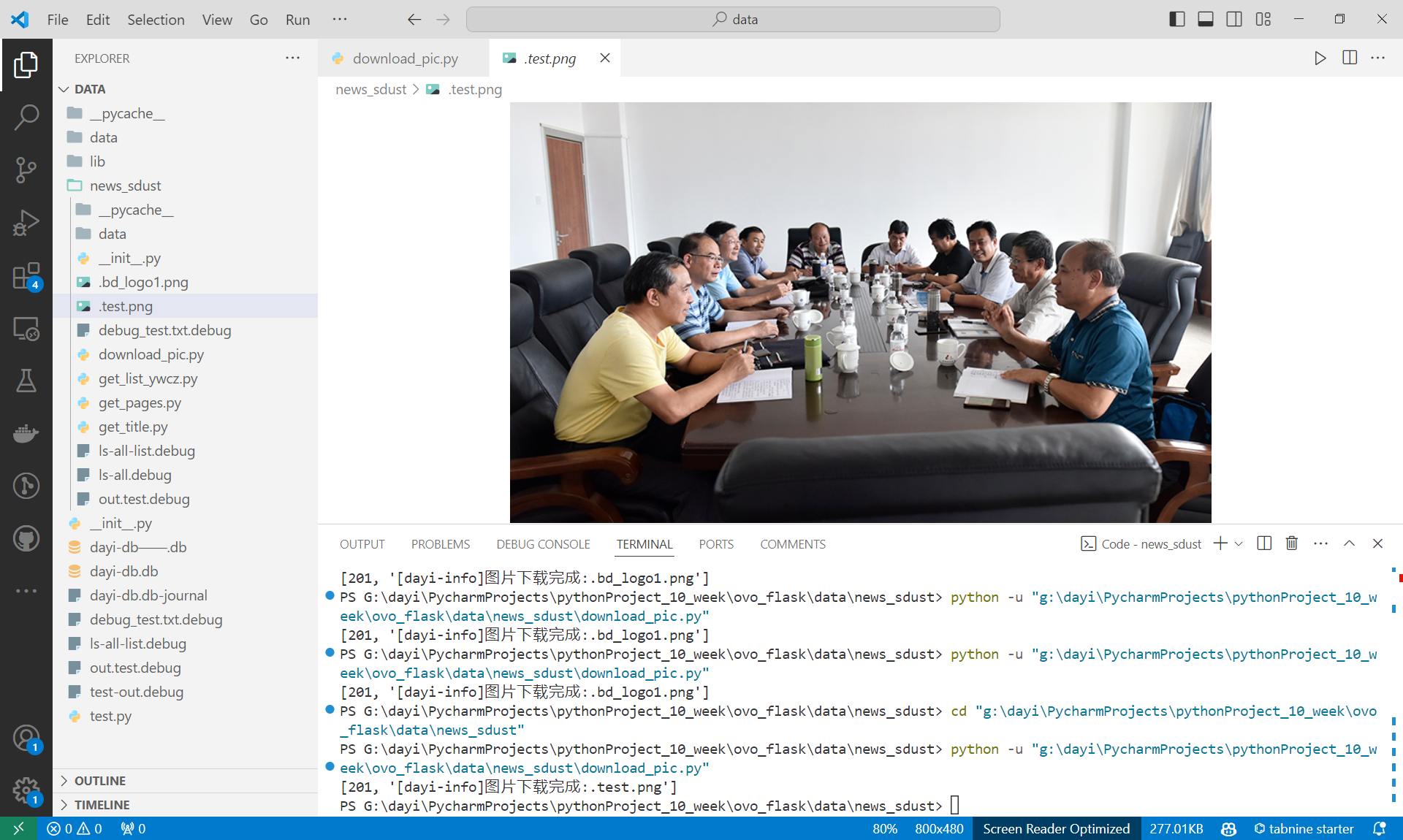
图片下载示例:
获得列表get_list_ywcz.py
也就是获得新闻列表,同时也解析了具体的格式,格式化为list
类似这样:# 数据格式: [[202,3,title_str,date_datetime,url_str]]# 数据返回: [[202, 3, '学校获评全国“ 四星易班工作站”', datetime.datetime(2022, 12, 6, 0, 0), 'http://www.sdust.edu.cn/info/1034/15628.htm'],[202,3,'balabal',...]]
所以是很方便用滴,后面插入数据库都很方便。
获得点击量get_title.py
1 | #获得标题,时间,点击量(主要是点击量) |
获得页面内容 get_pages.py
因为解析出来的URL有些时候是相对引用,于是就有了fix_url 来自动补全,使用了urllib库文件。然后BS4匹配class,然后直接读取数据即可。抓包可以找到获得点击量的网址。稍微麻烦点的是
1 | res_num = re.findall(r"\d+\.?\d*",publish_click) |
同样的方法,可以把 发布于:2024-xx-xx
的数字解析出来。
因为整个过程用了datetime来传递时间,这样就可以方便的返回datetime类型
也会去解析图片!
有两个接口,虽然这些接口都是list,也用了异步写了一次,但是为了多线程稳定这里还是用了同步的方法。
1 | #获得页面的数据 |
这里是效果哦,你看图片都有啦!
大一统
也就是把上面所有文件调用一下!
服务器上跑!
效率:在15分钟内可以下载3700条以上的全部内容,媒体内容大概是2.15G左右
当然支持单线程了
当然,我们的代码也支持单线程稳定而低调的获取

数据库
其实挺简单的,就是建表,然后插入数据,插入数据之前预处理一下,有些时候需要返回一下uuid。
后来引用了sqlalchemy,支持了多线程,封装成了两个接口一模一样的包,这样就可以保证之前写的代码的通用性。
使用的是对于小数据集友好的sqlite数据库。因为用了sqlalchemy,实际上非常方便迁移到mysql等其他的数据库
在简单的编写后,封装的class支持以下操作:
- 支持使用 with 关键字使用class
- 自动初始化连接,仅需要定义一个dayi_db_ovo() 既可以自动建立连接。
- 自动建表
- 执行自定义sql命令
- 函数插入图片。传递url和日期信息,自动生成uuid,图片基本信息插入数据库,生成待下载目录,返回uuid,等待图片下载
- 插入文章内容信息,标题,点击率
数据库内容:
新闻内容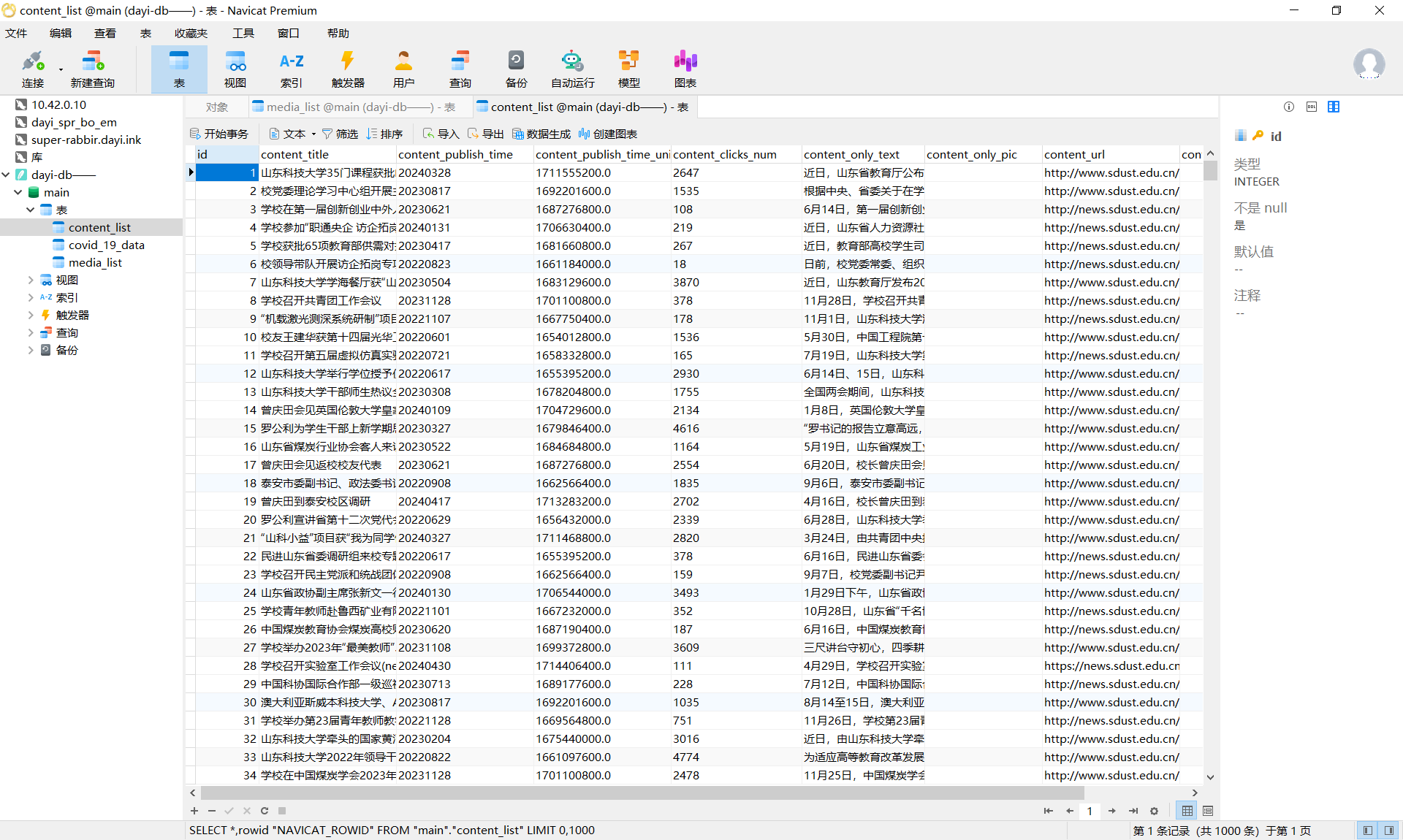
图片对应索引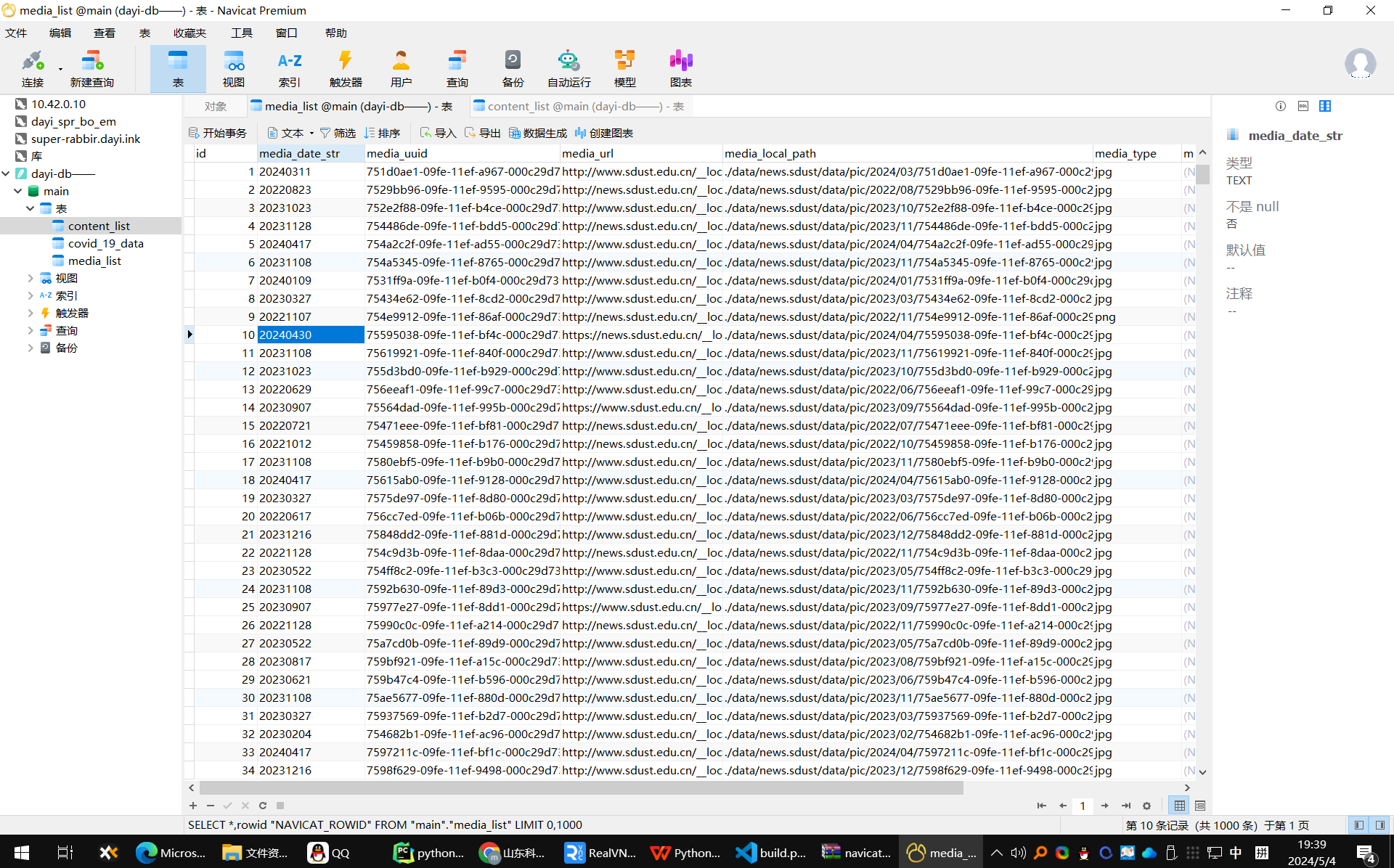
具体的
我们把文件规整起来整理
文章,点击率,标题,都存到我们的数据库中。
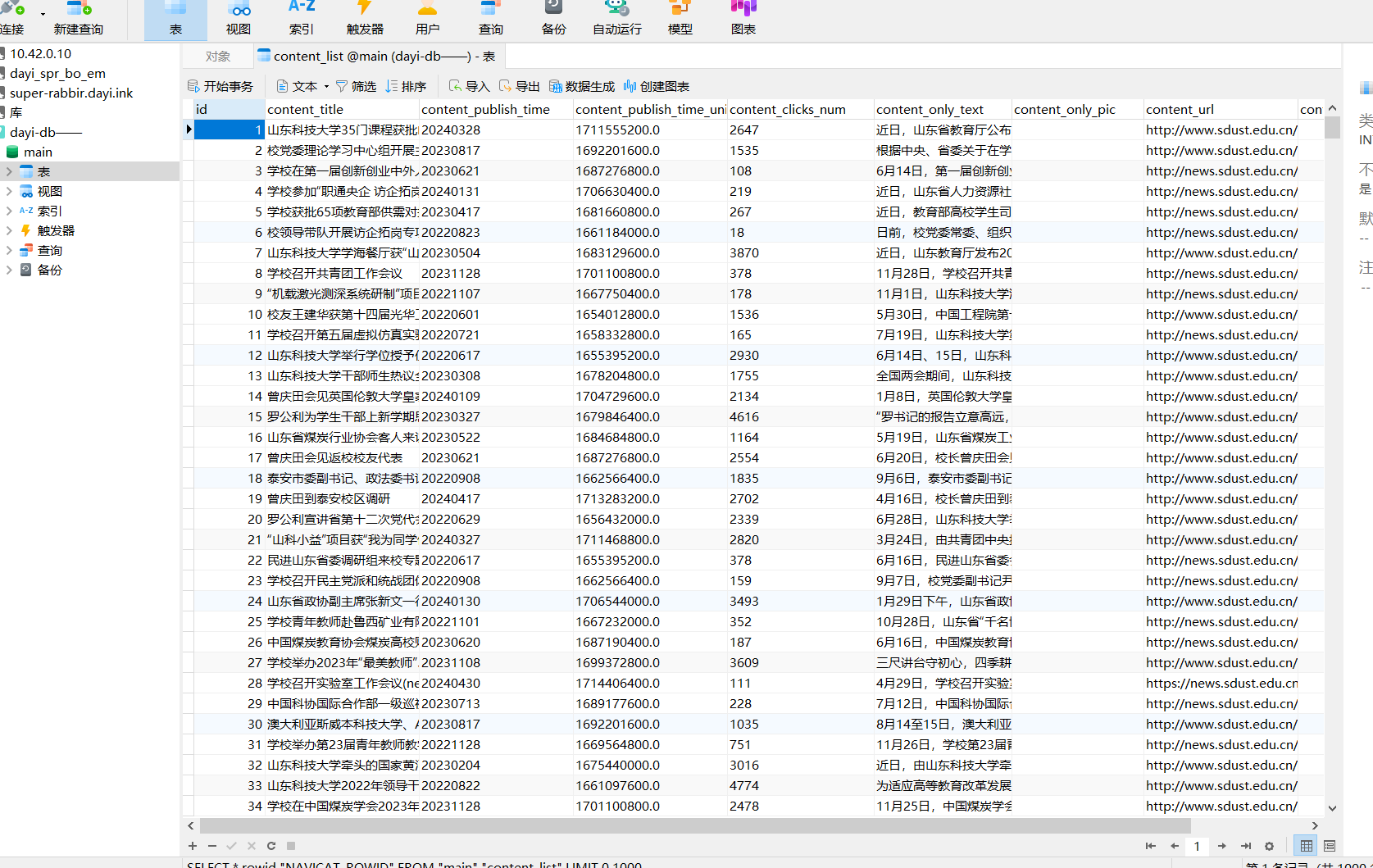
使用起来也非常方便,可以很容易的进行导出,也很好使用其他程序进行读取,并且,这么多内容10多M 心动不心动? 而且,随便点开一个,换行符什么的都保留啦,整理的内容好看又好用
图片们
已经按年月分类了捏
里面的图片也非常全!
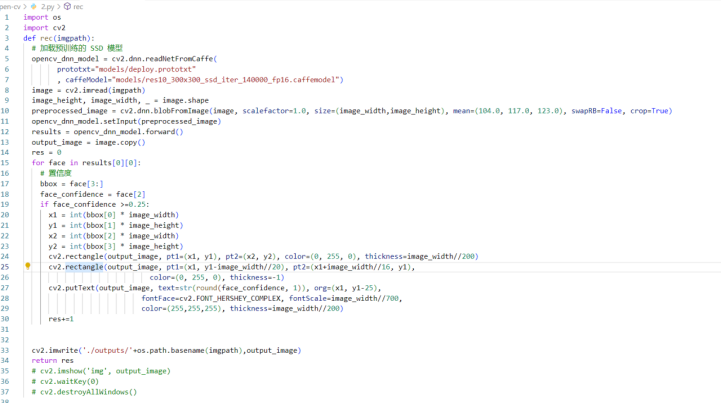
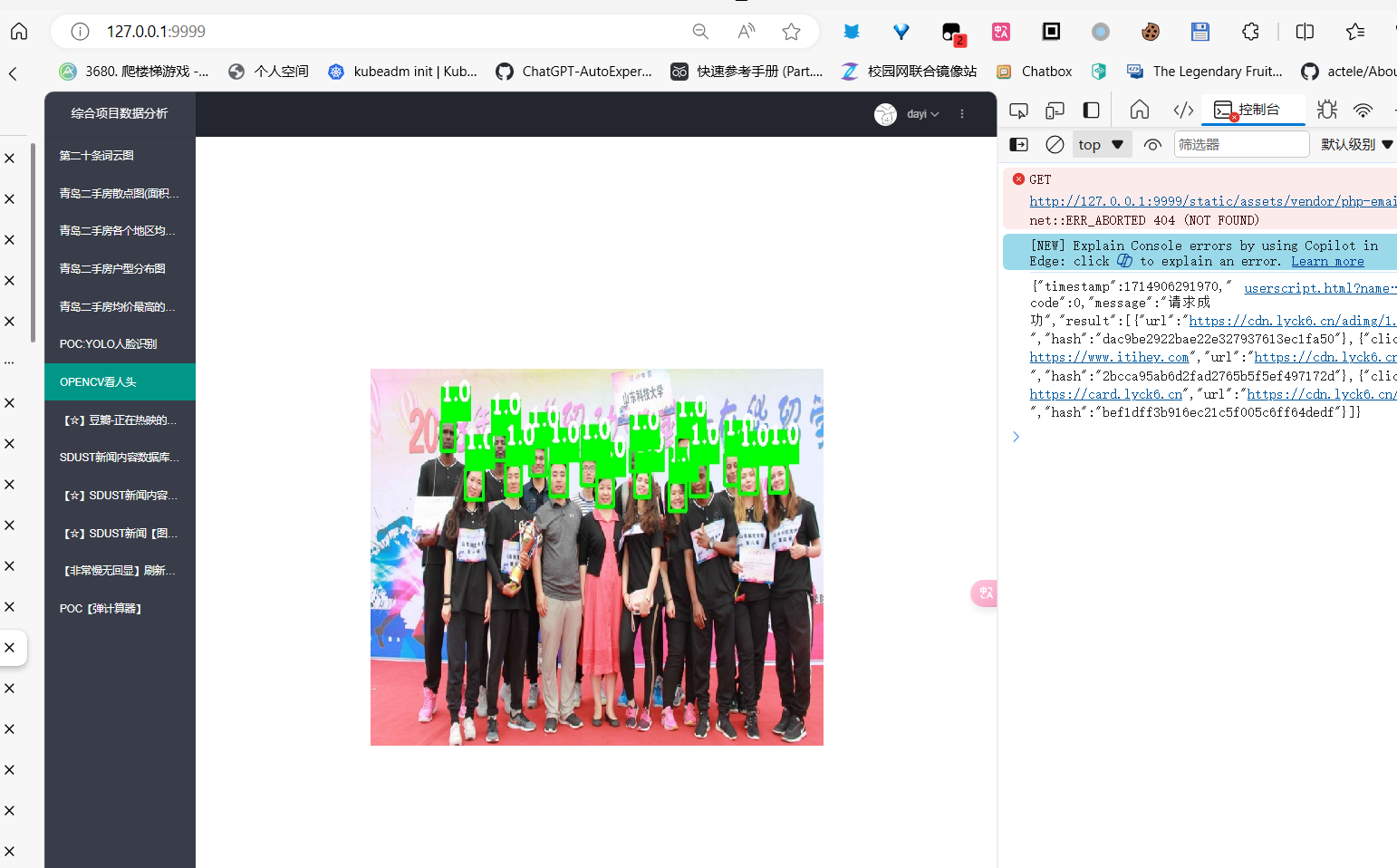
OPENCV数人头
人这么多,能干什么捏?
要不来数一数有多少人吧?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16个人
嗯..自己数也太麻烦了,要不让AI来干活吧?
于是,便有了AI数数!

于是,我们利用OPENCV 对人头数进行了统计




识别信息,然后返回,最后保存成文件
得出了人头的结论
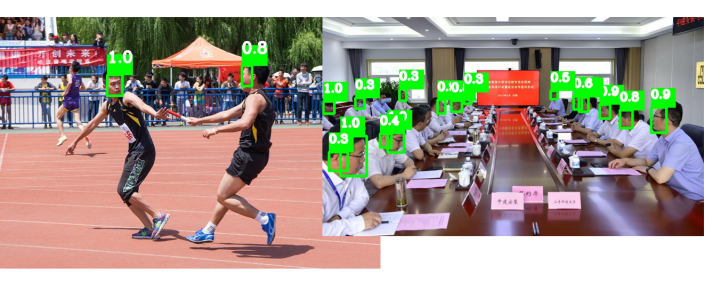

人头的结论!

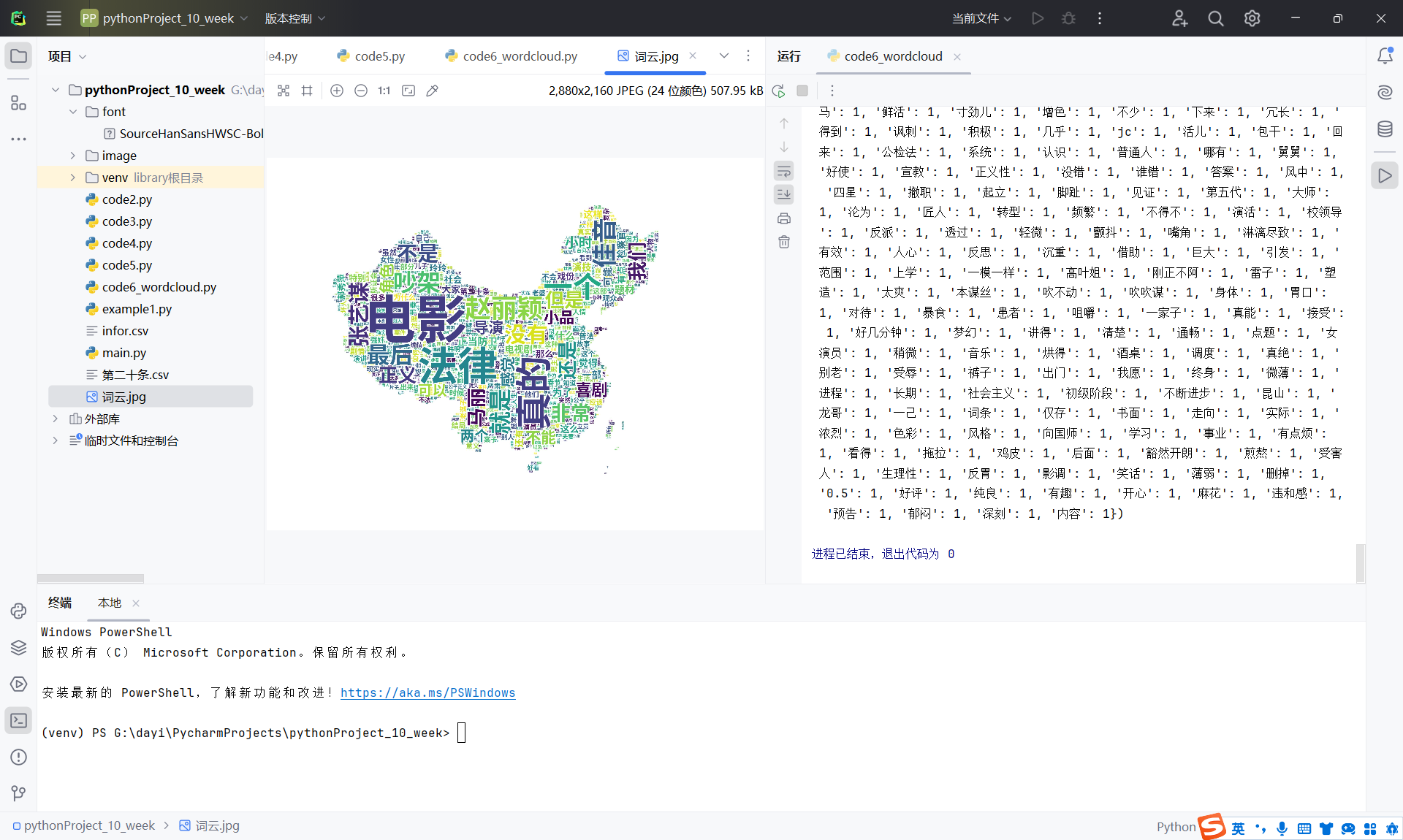
好看的词云
引用了一个效果不错的词云,因为是真的好看!!
然后手动加了点stopwords,把数据库导出txt,csv之类的,数据集喂进去效果还是不错的。


他们的原图是这样滴!
SDUST漏洞扫描
我们还想进行简单的漏洞(信息)扫描

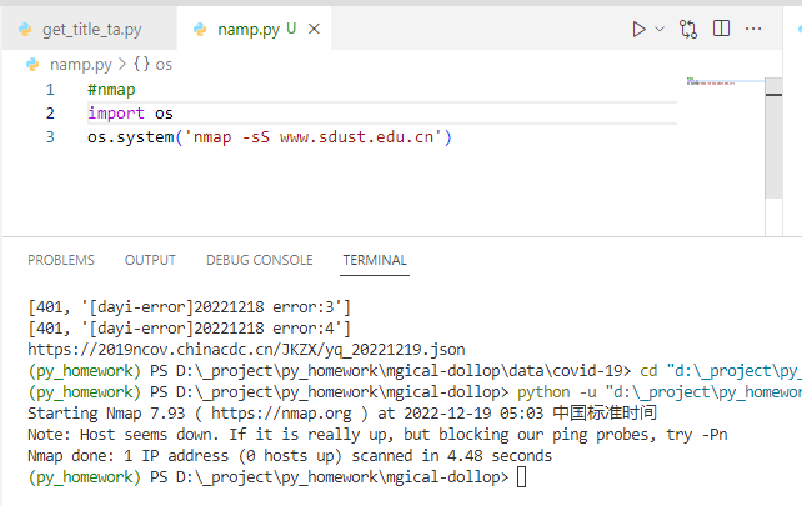
但是发现服务器禁止了nmap扫描就放弃了
SDUST查新闻的内容【接到了flask】
新闻内容
可以实时显示数据库
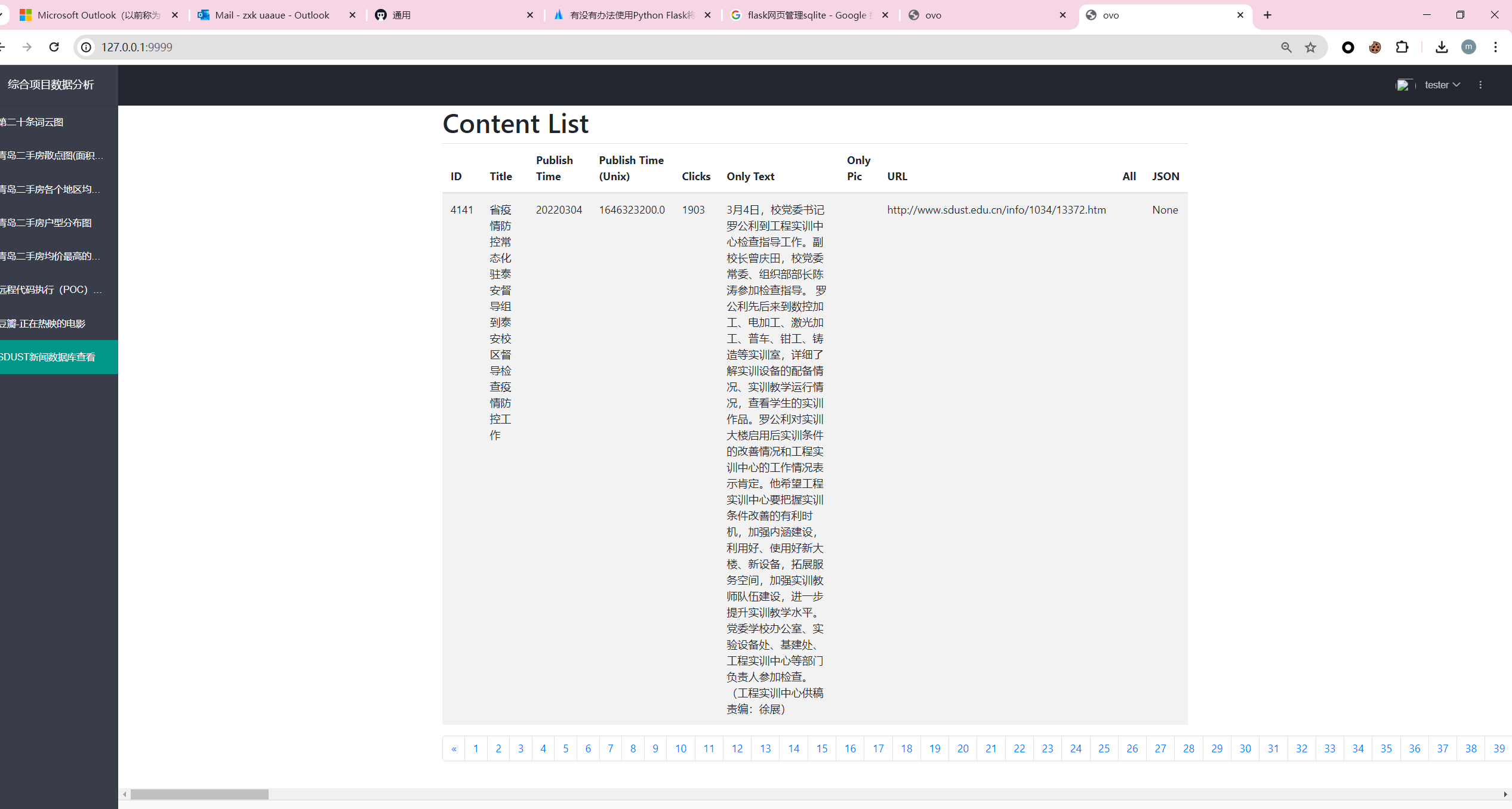
可以翻页ovo,因为内容太多啦。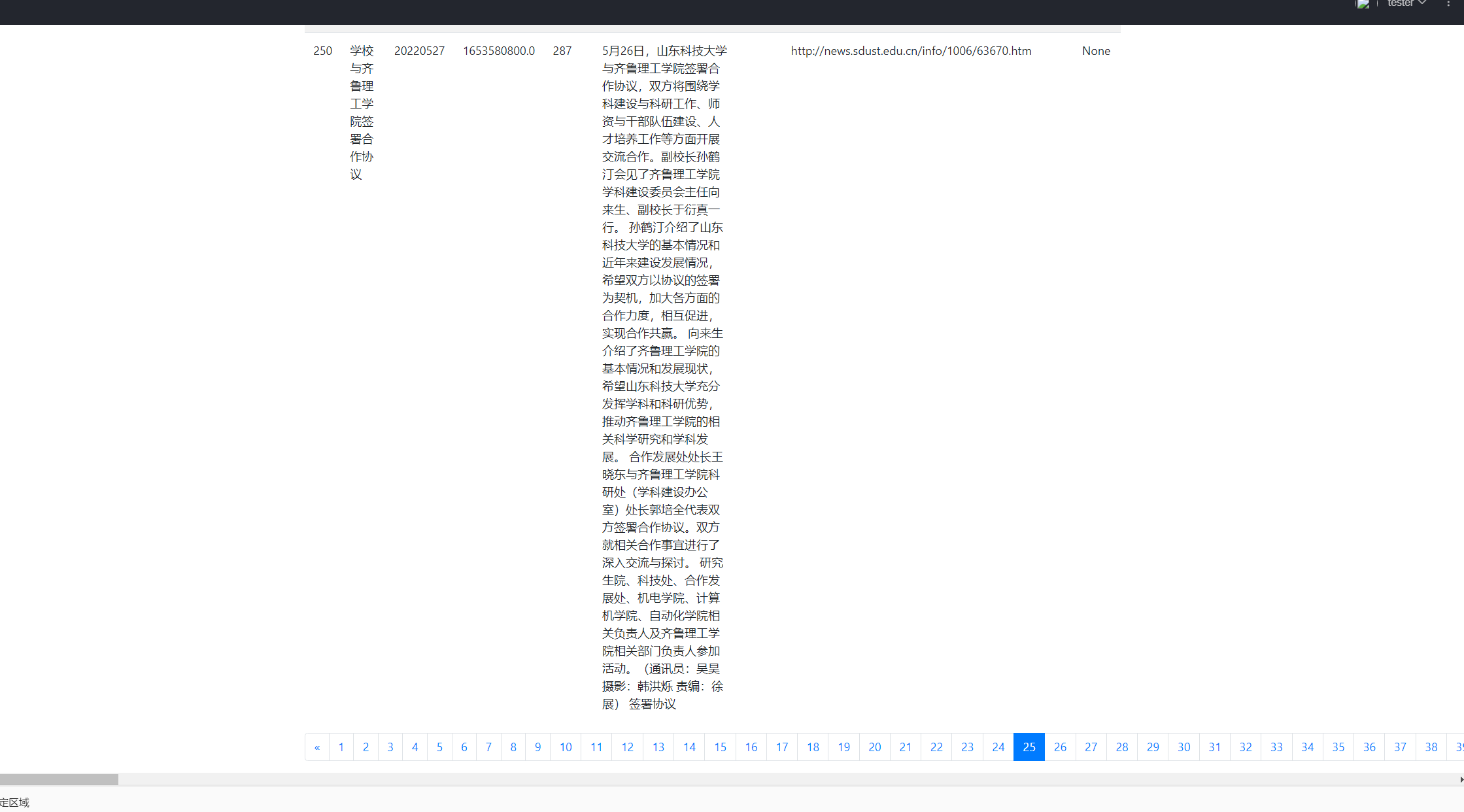
新闻内容精简版
内容那么长干嘛,简单一点!
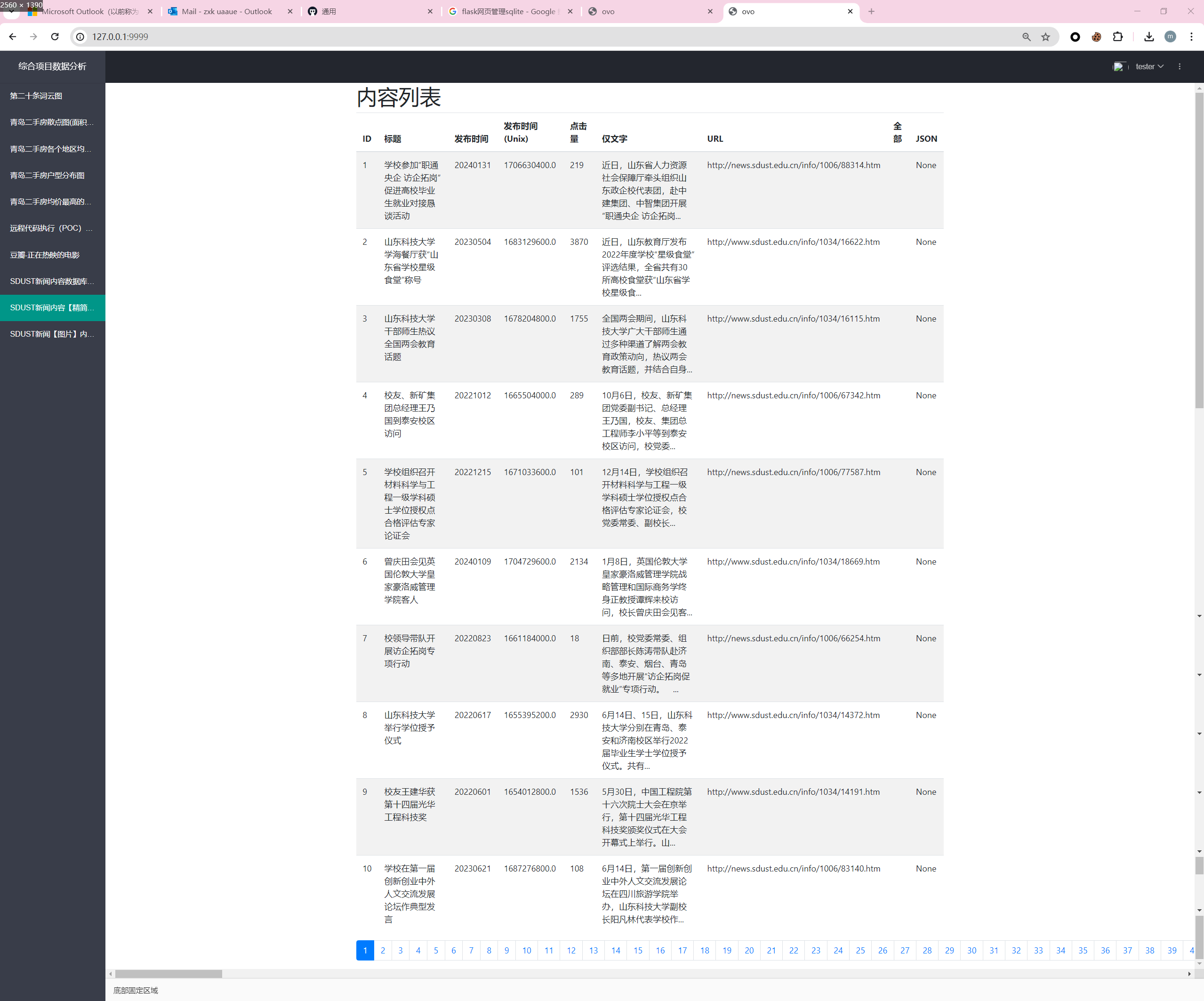
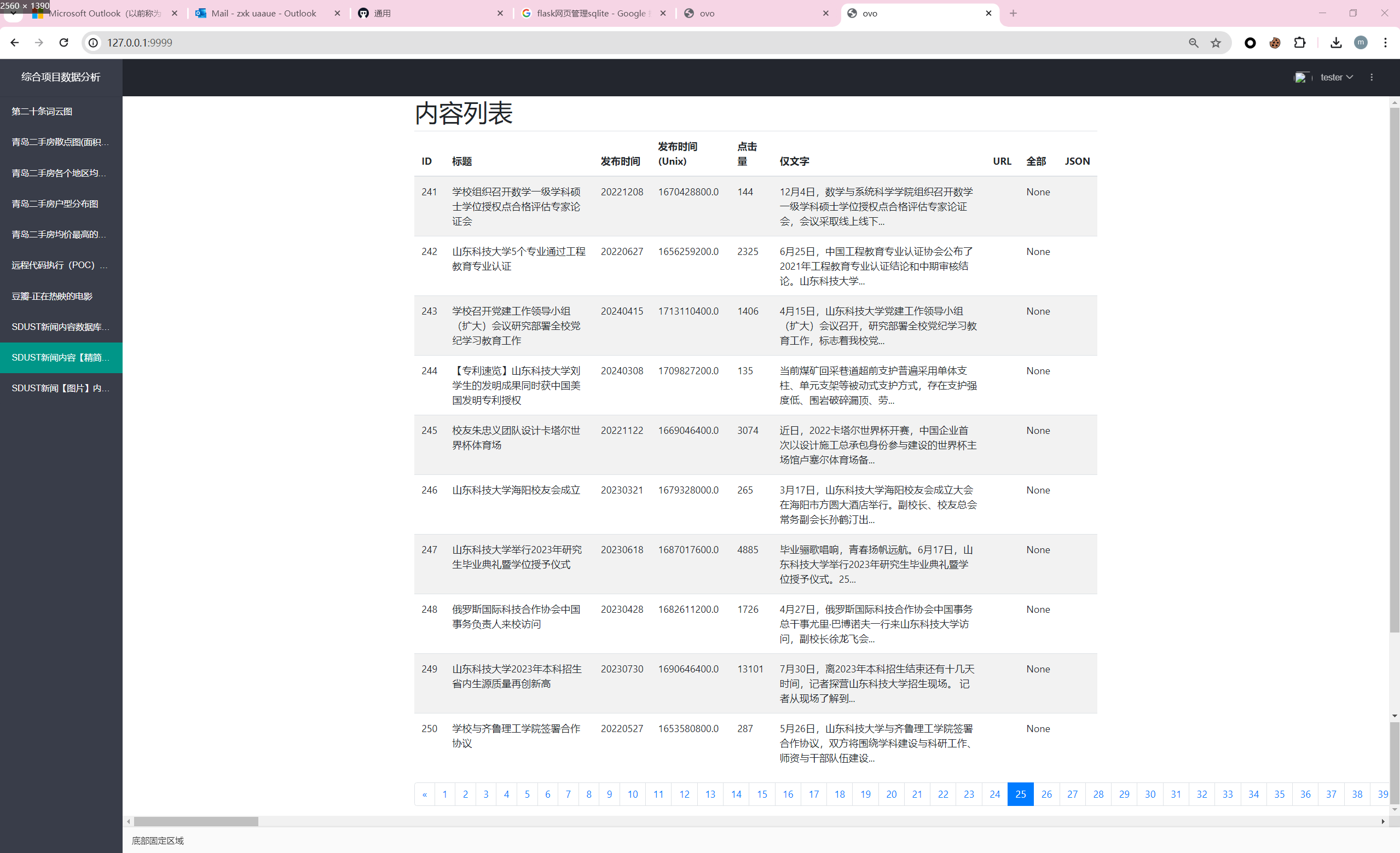
当当
我想看图!
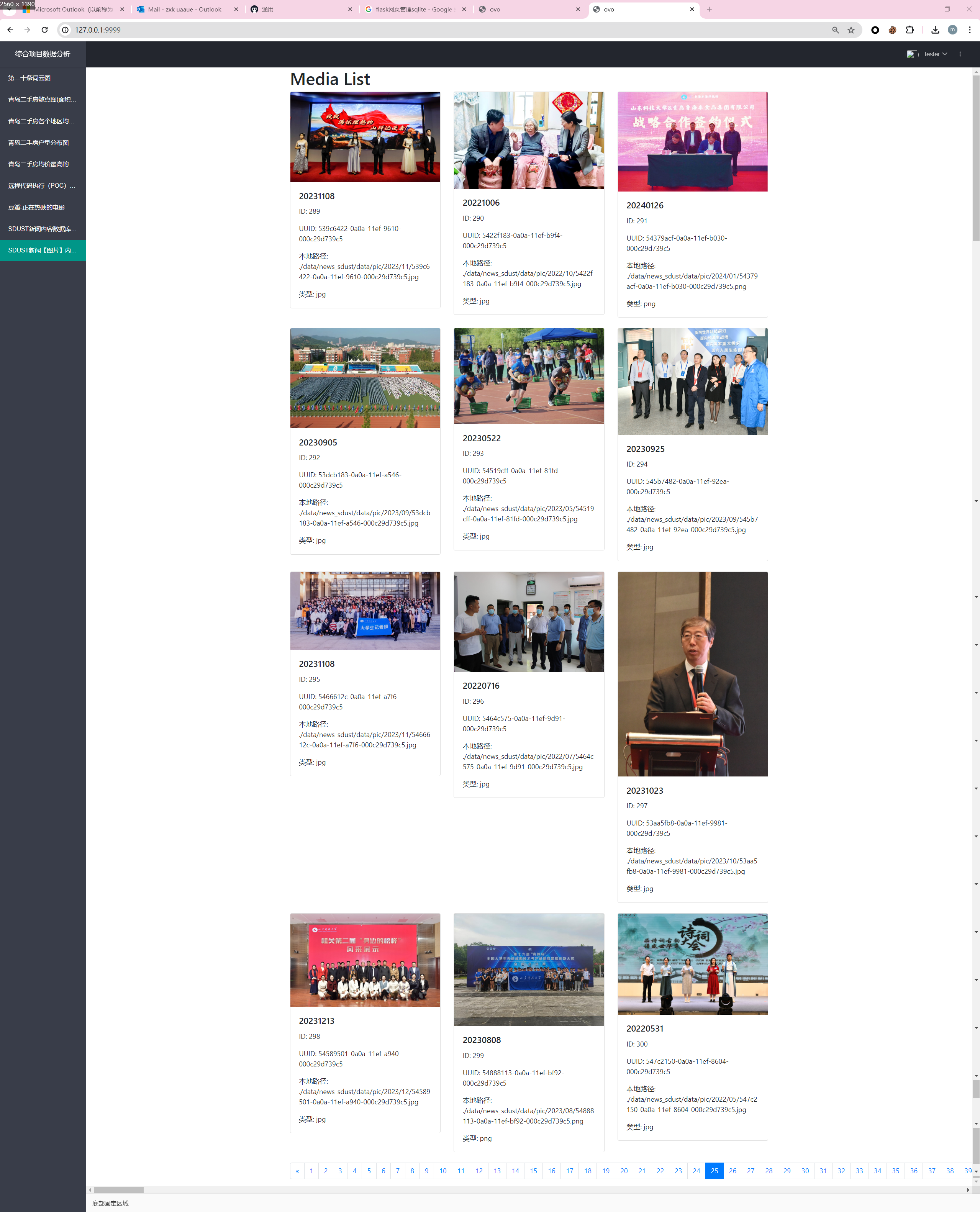
这里可以看数据库中的图片ovo
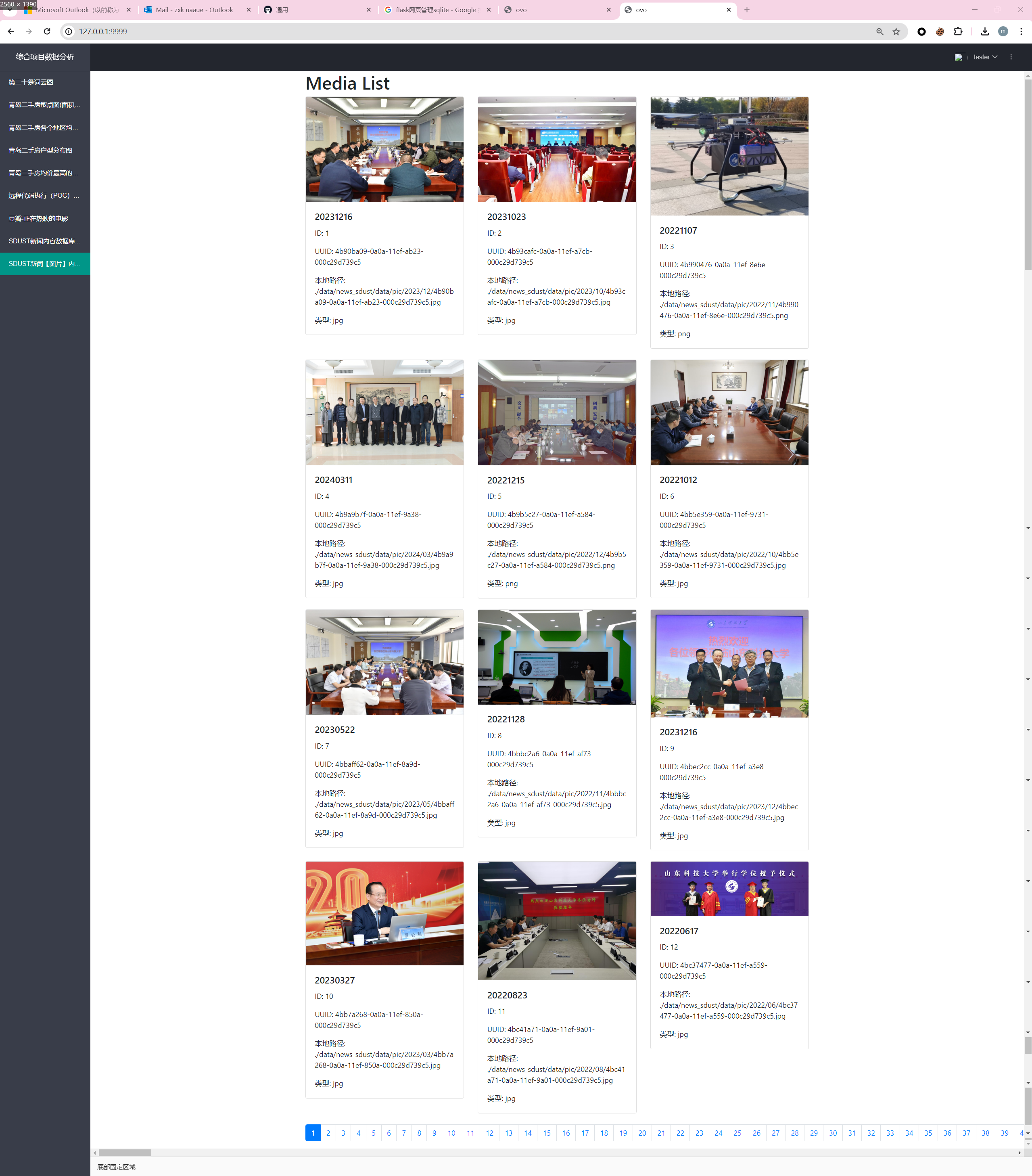
每一页都是可以看哒!
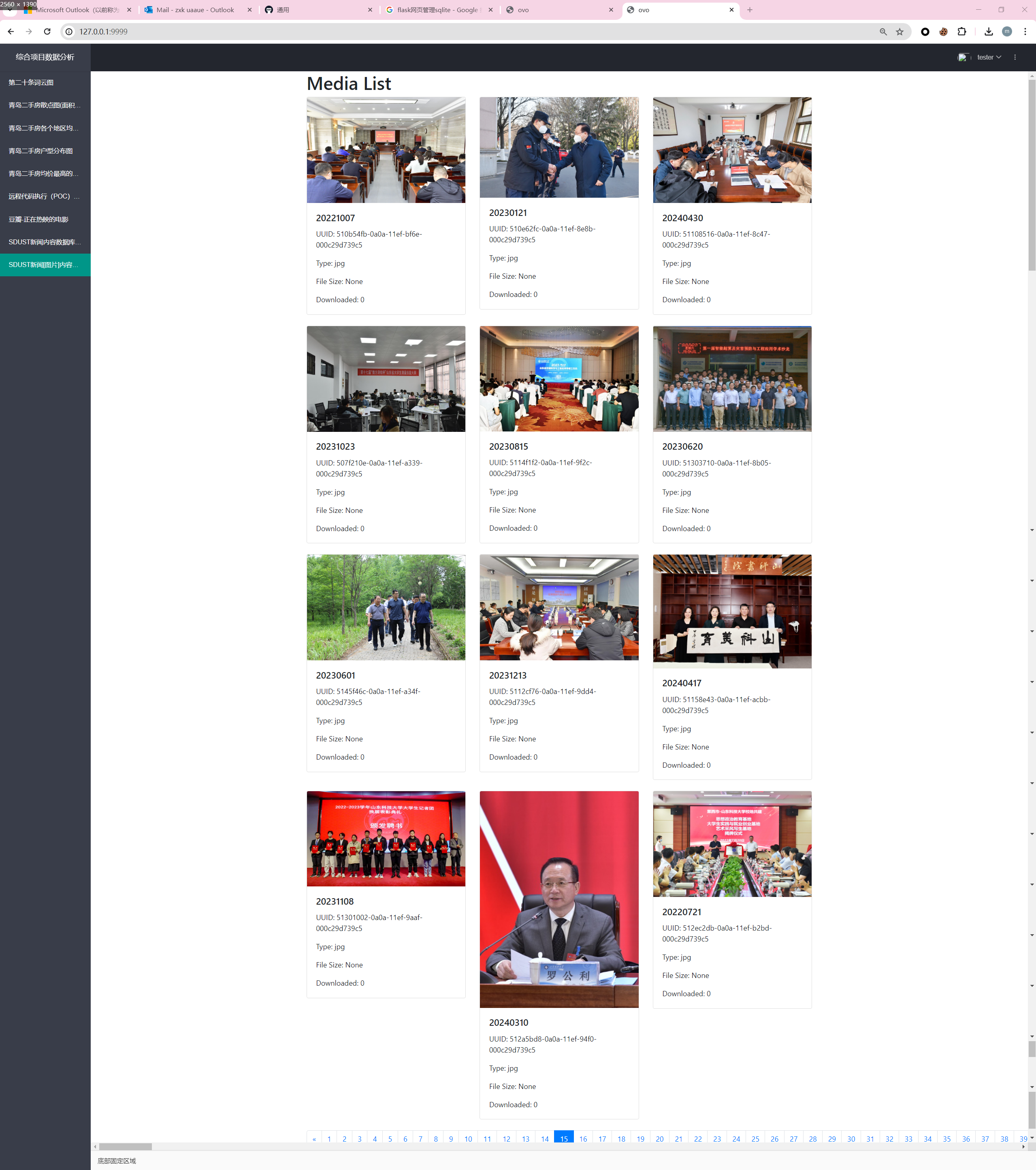
是这样啦
SDUST图云生成
每个新闻都可以生成图云啦
真的蛮辛苦的
我恨JS,但是JS也挺好使救命。
调出来啦~
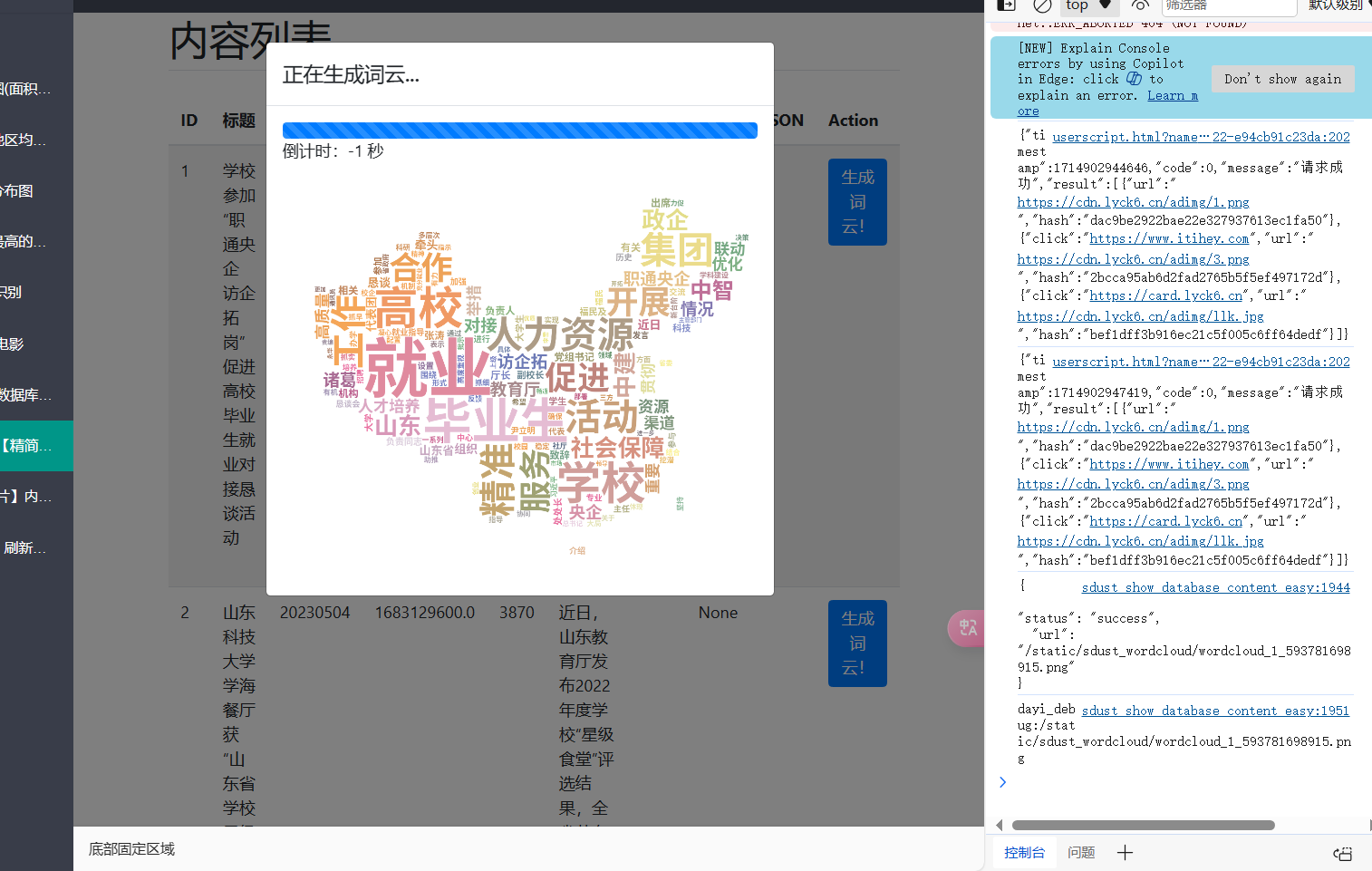
正在生成中~
我还加了一个正在生成中ovo
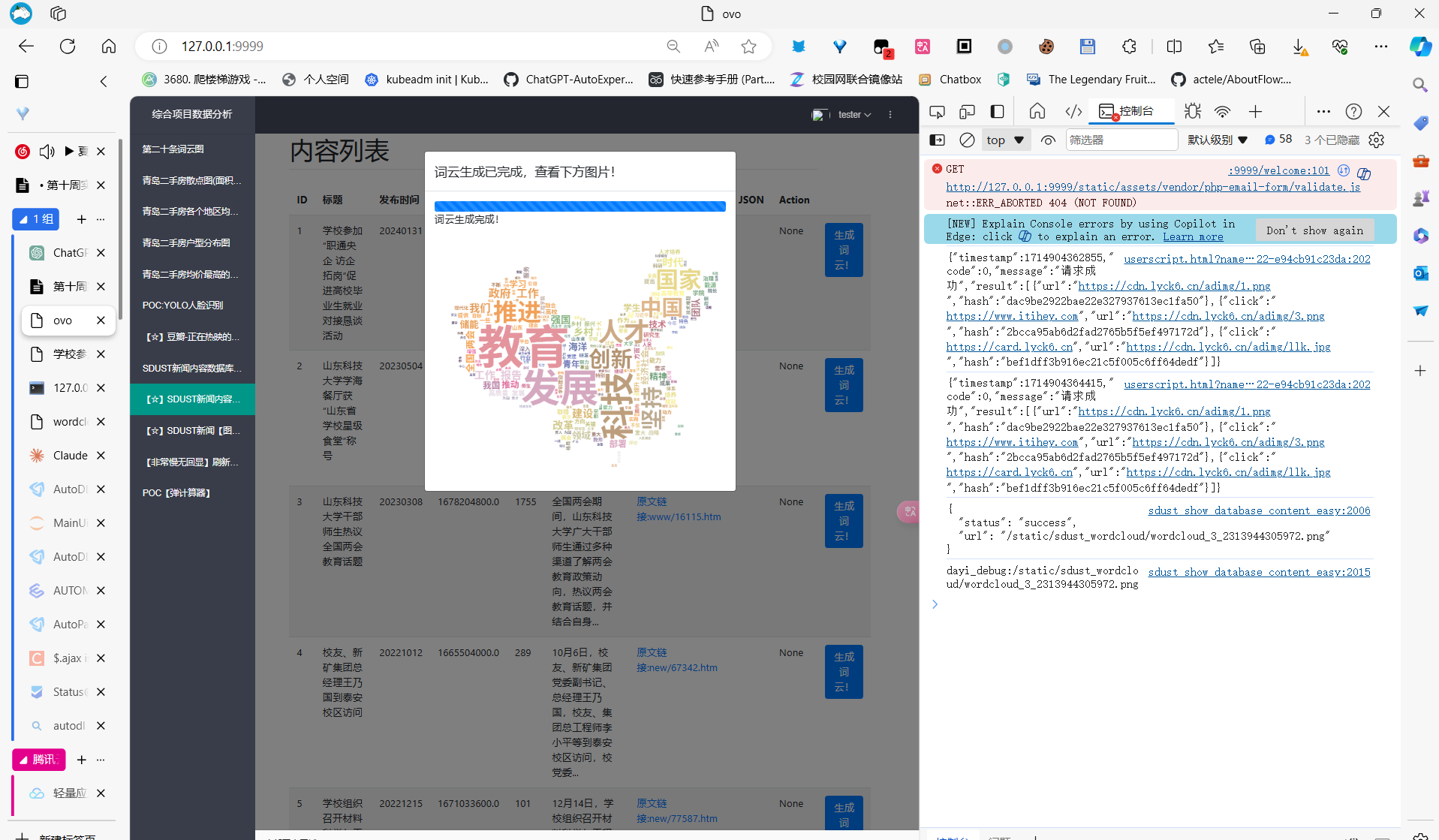
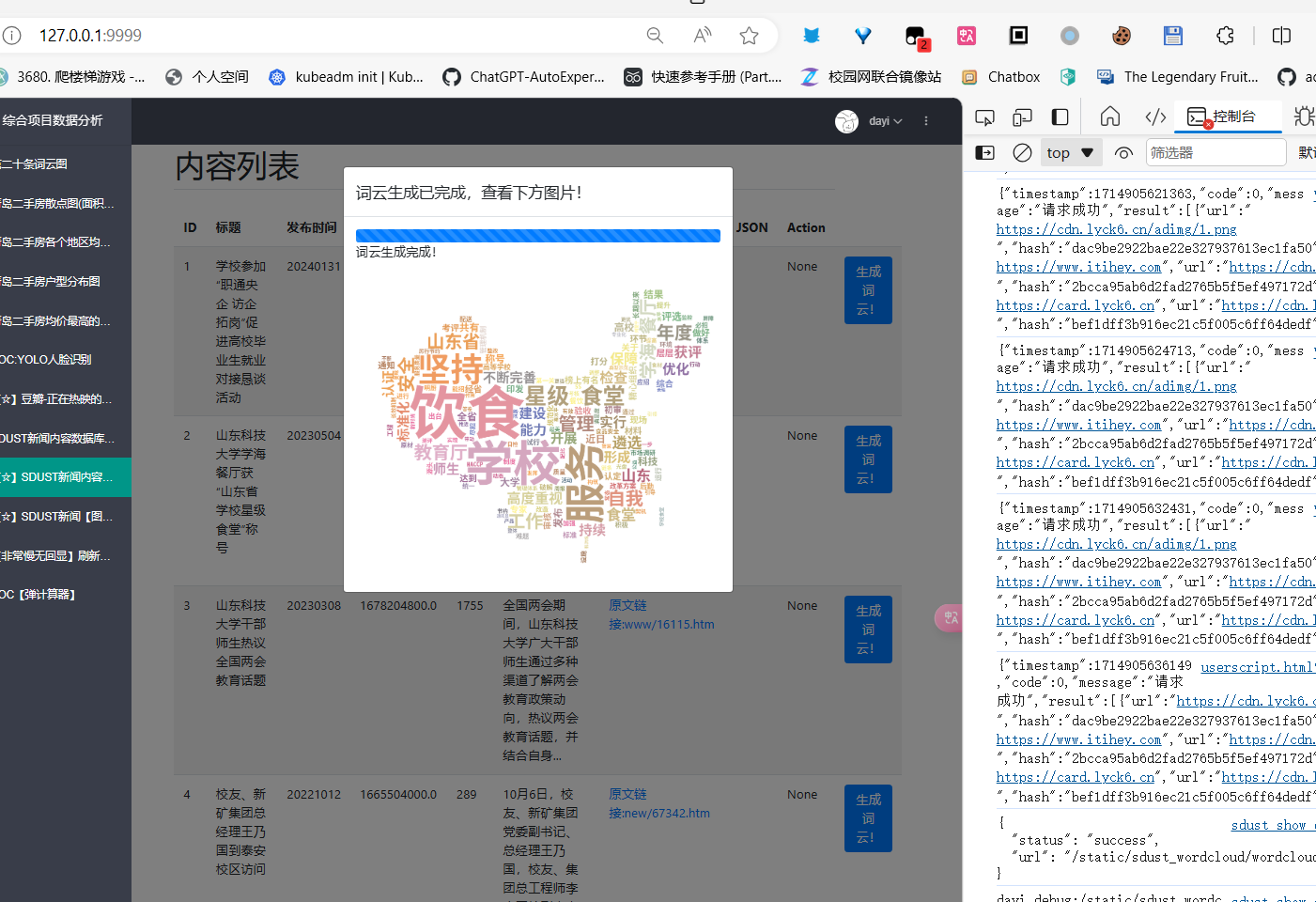
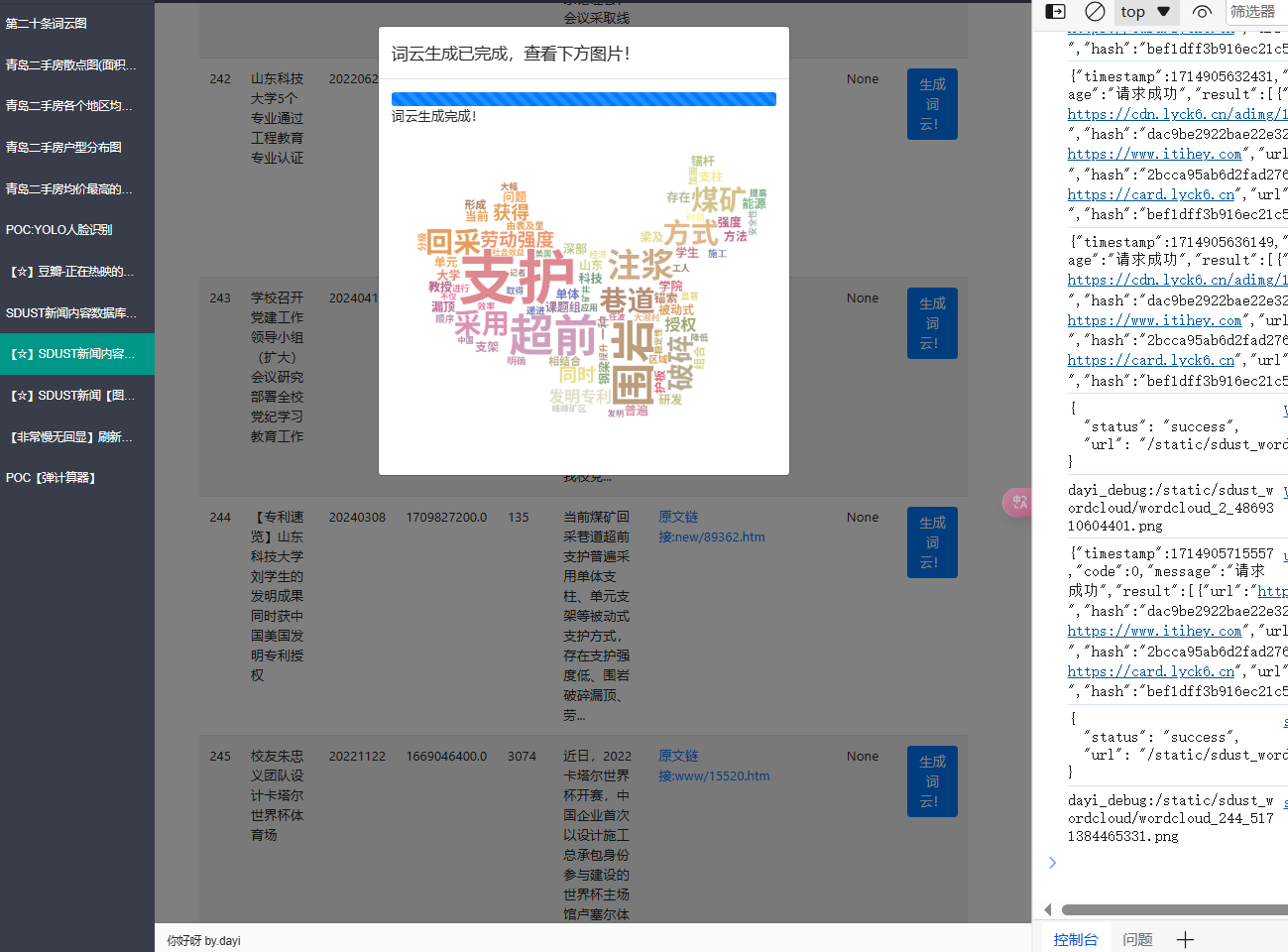
当当,看结果吧
生成图
生成完成!
哪个都是可以点滴
真滴
代码细节:简单说
H5实现
就是来个界面,然后生成一个进度条,然后后端传过来数据之后就解析下json,然后显示在前端即可。
后端的实现
查数据库,然后生成图
然后调用那个库文件,也就是那个类(什么活都交给它了哈哈哈哈)
然后简单生成一下就好啦
代码细节:具体来说
本分析主要针对提供的 Flask 模板,该模板包括 HTML 结构、CSS 链接、JavaScript 脚本以及 Flask 模板引擎的语法。该模板主要用于展示内容列表,并提供一个功能用于生成与显示词云。
HTML 结构
- 头部 (
head): 引入了 Bootstrap CSS 和 jQuery,用于页面样式和动态功能。 - 主体 (
body):- 容器 (
div.container): 包含了页面的主要内容,如标题、表格、分页导航等。 - 模态框 (
div.modal): 用于显示词云生成的进度和结果。 - 表格 (
table): 显示内容列表,包括各种属性如标题、发布时间、点击量等。 - 分页导航 (
nav.pagination): 用于在不同页之间导航。
- 容器 (
CSS
- 使用了 Bootstrap 的样式表来美化页面元素,如表格、按钮和模态框。
JavaScript 详情
概览
JavaScript 代码主要使用 jQuery 库来操纵 DOM 元素,处理用户交互,如点击按钮生成词云。
细节分析
词云生成按钮的事件绑定:
- 使用
.generate-wordcloud类选择器绑定点击事件到所有生成词云的按钮。 - 当按钮被点击时,从按钮的
data-id属性获取内容 ID,并触发一系列动作。
- 使用
模态框显示与进度条:
- 显示模态框 (
#wordcloudModal). - 初始化并动态更新进度条和倒计时,假设生成词云的总时间为 20 秒。
- 显示模态框 (
AJAX 请求:
- 发送异步请求到
/generate_wordcloud/加上内容 ID 的 URL,以请求生成词云。 - 请求成功后,解析响应并更新模态框中的图像源 (
img#wordCloudImage)。 - 处理请求失败的情况,显示错误信息。
- 发送异步请求到
计时与反馈:
- 设定倒计时结束后的反馈消息。
- 在 AJAX 请求完成后,更新模态框中的标题和消息,以反映操作的最终状态。
异步操作和错误处理
- 对 AJAX 请求的错误进行处理,包括请求失败和服务器错误的情况。
- 使用回调函数来处理请求成功和失败后的 DOM 更新。
Flask 模板引擎
- 使用 Jinja2 模板语法来动态生成 HTML 内容。
{% for content in content_list %}: 循环遍历content_list,在表格中为每项内容生成一行。{% if %}和{% else %}: 条件语句用于处理内容是否存在链接的情况。- 分页逻辑的实现,通过
{% for page in range(1, total_pages + 1) %}迭代生成分页链接。
Flask 模板提供了一个用户界面,用于展示内容列表和通过词云可视化这些内容。它整合了 Bootstrap、jQuery 和 Flask 模板语法来实现一个响应式且交互性强的网页应用。JavaScript 脚本中包含了对用户操作的动态响应,包括通过 AJAX 请求生成词云,并在页面上实时显示进度和结果。
OPENCV看人头
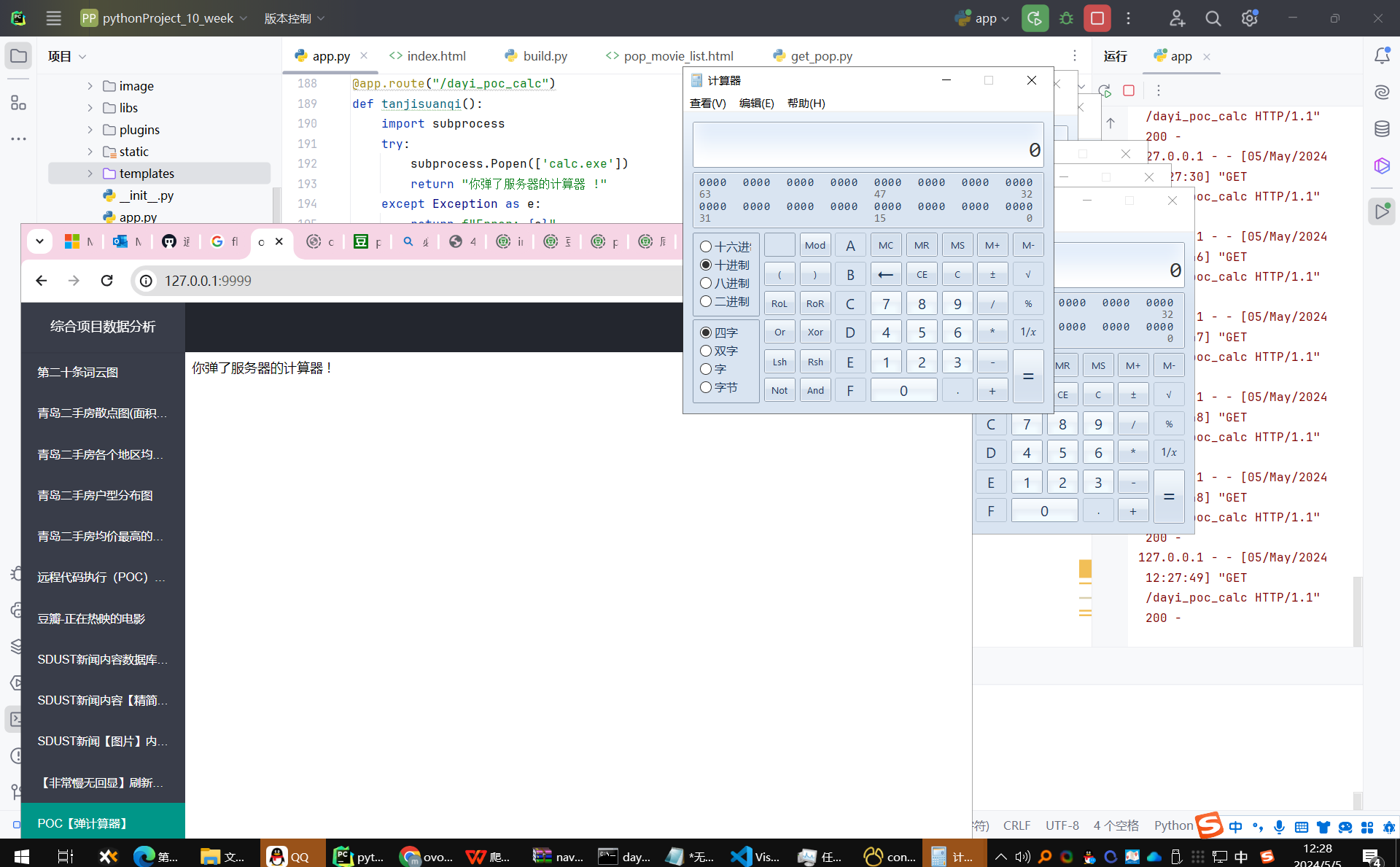
【POC】弹计算器
Oppos.
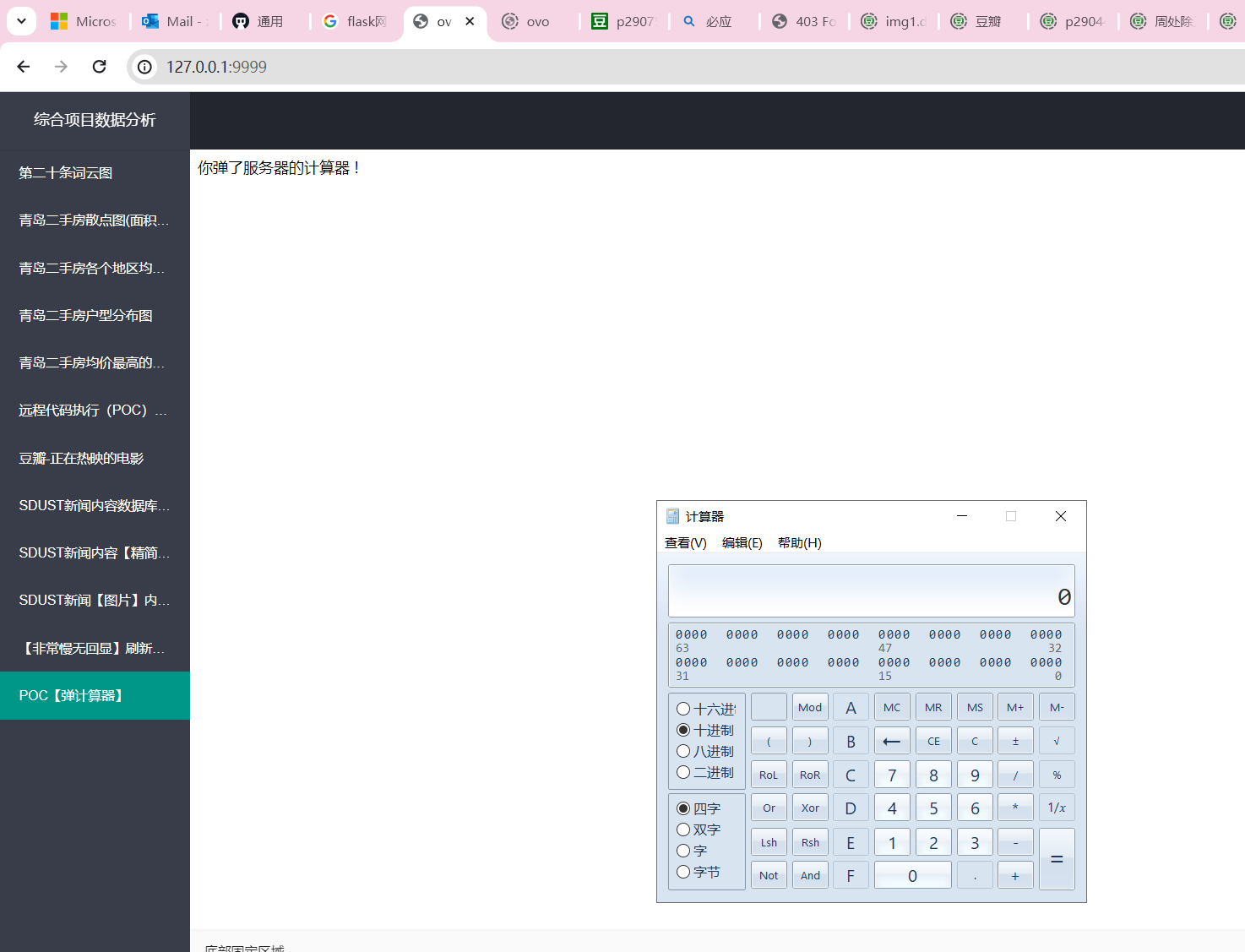
因为用的subprocess,所以能弹好几个不带冲突的。
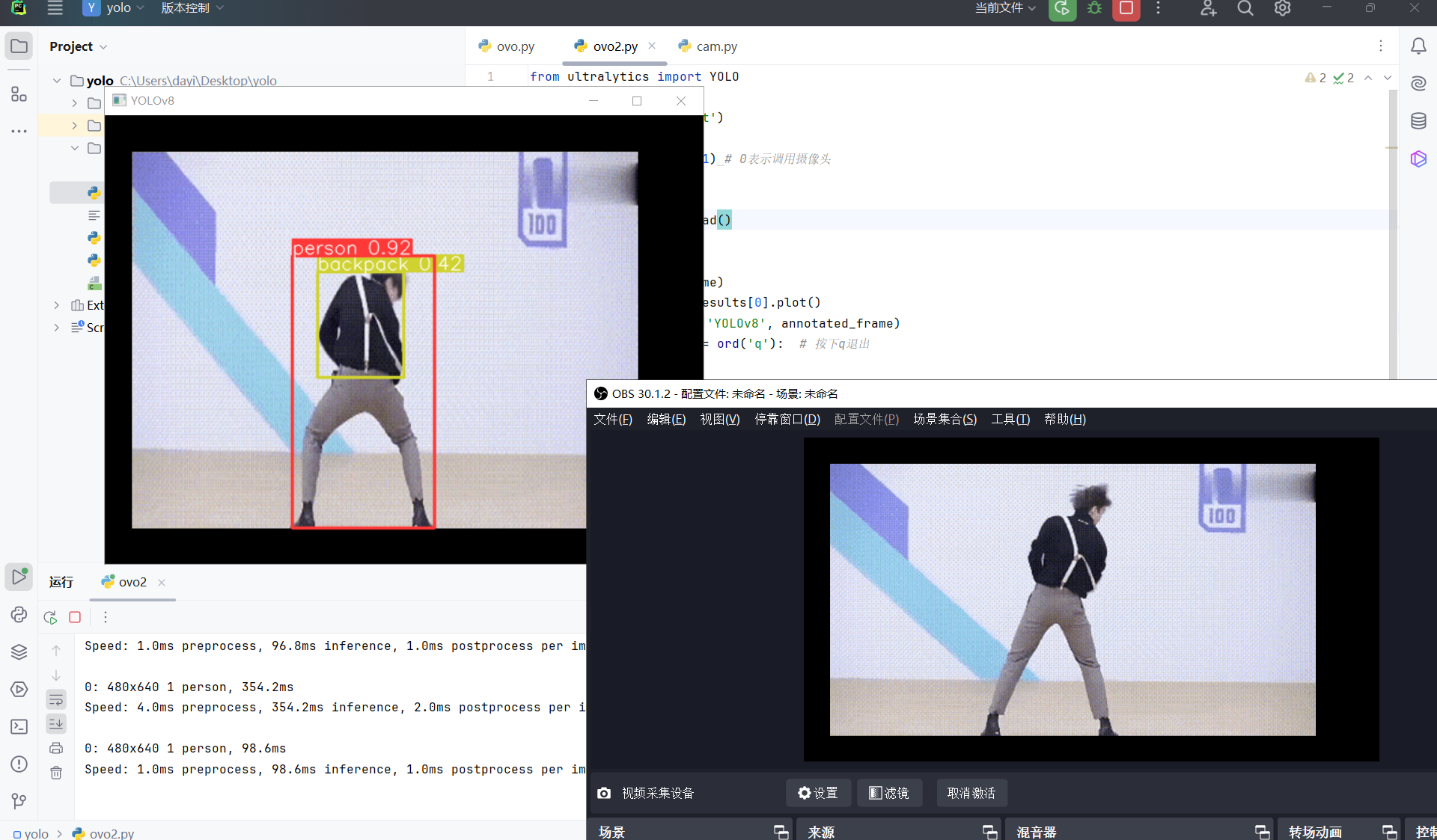
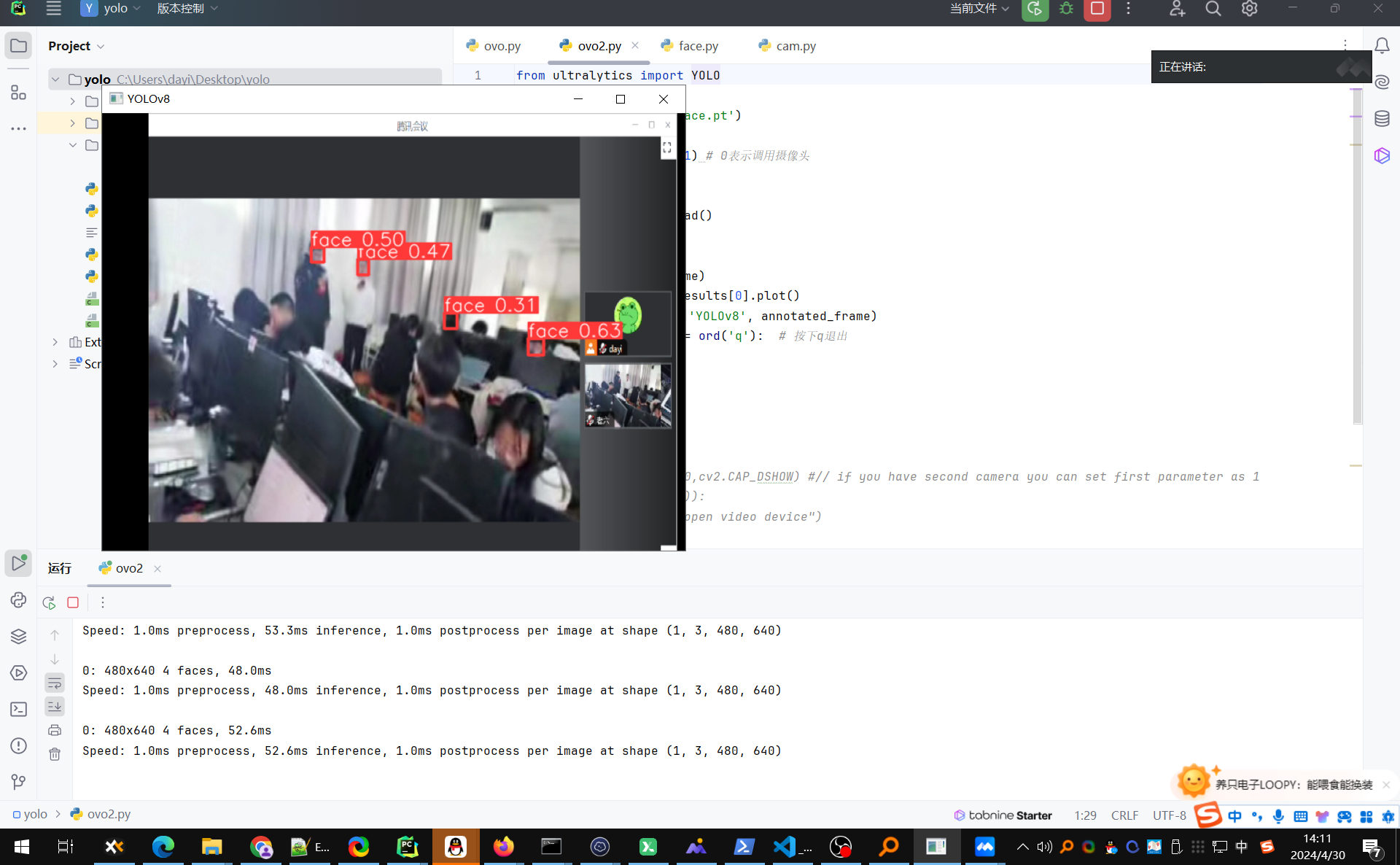
YOLO 识别
先看效果啦~
物品:
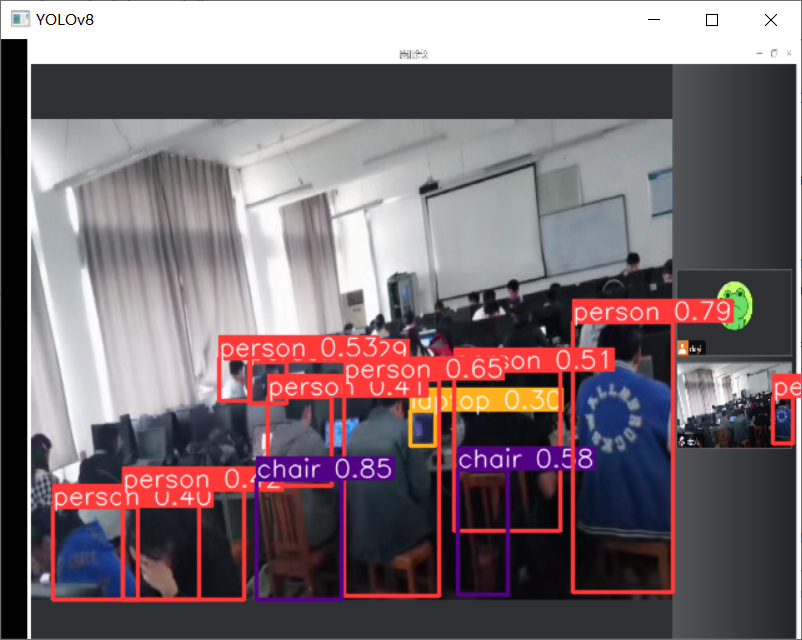
人物:
人脸: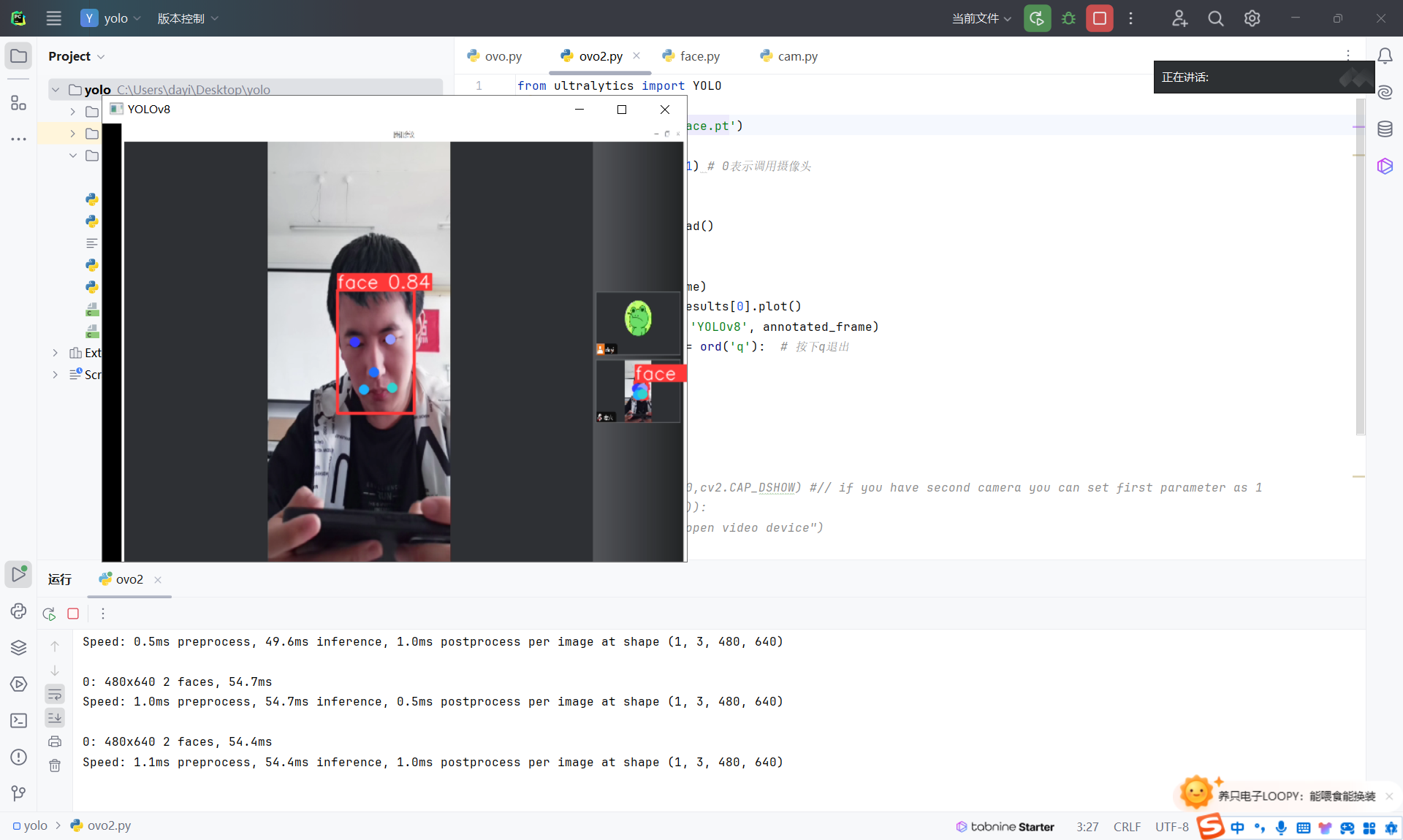
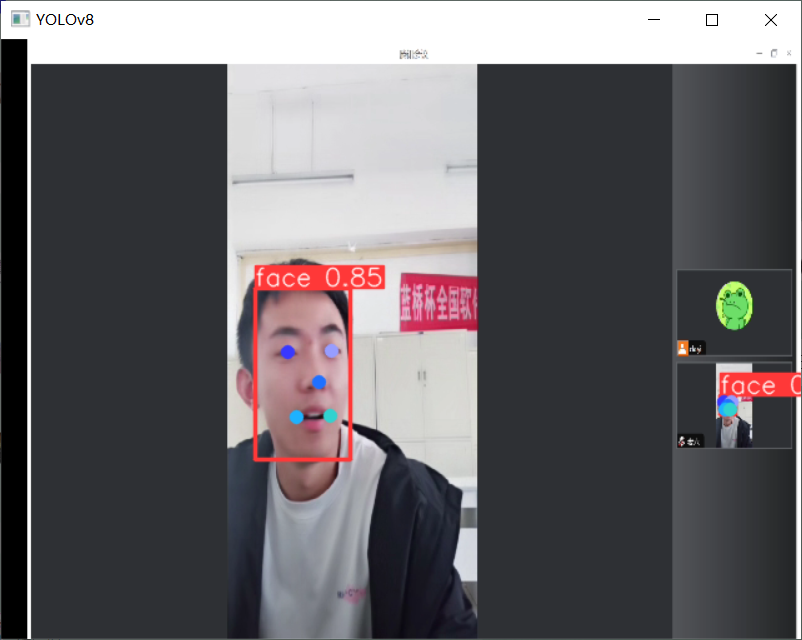
pytorch纯CPU跑的。
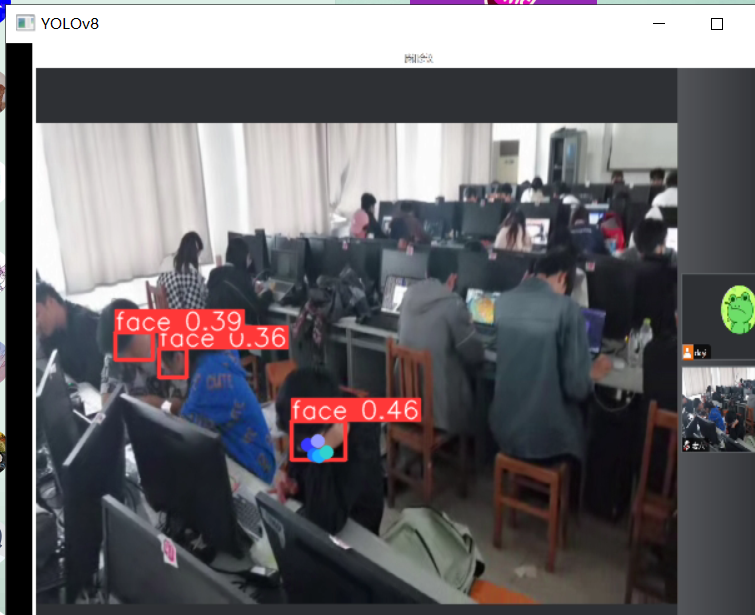
再来点图:
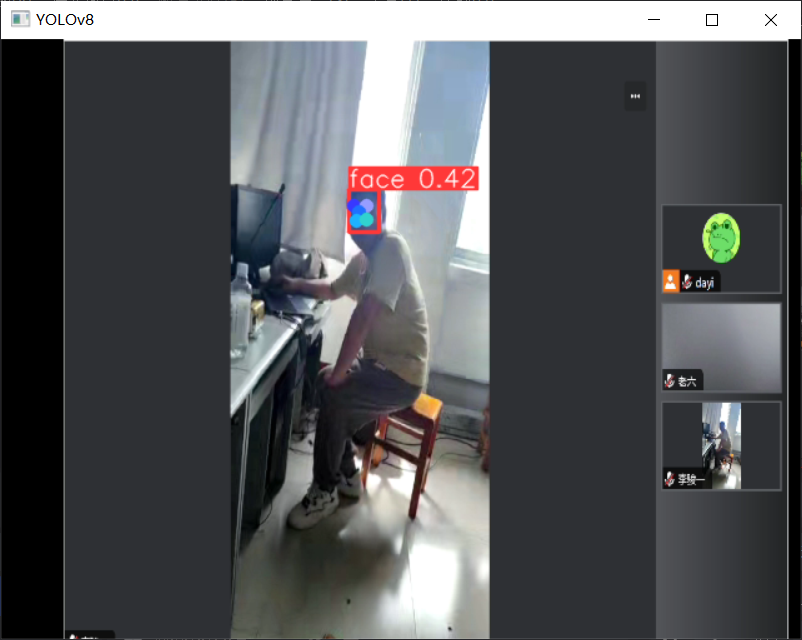
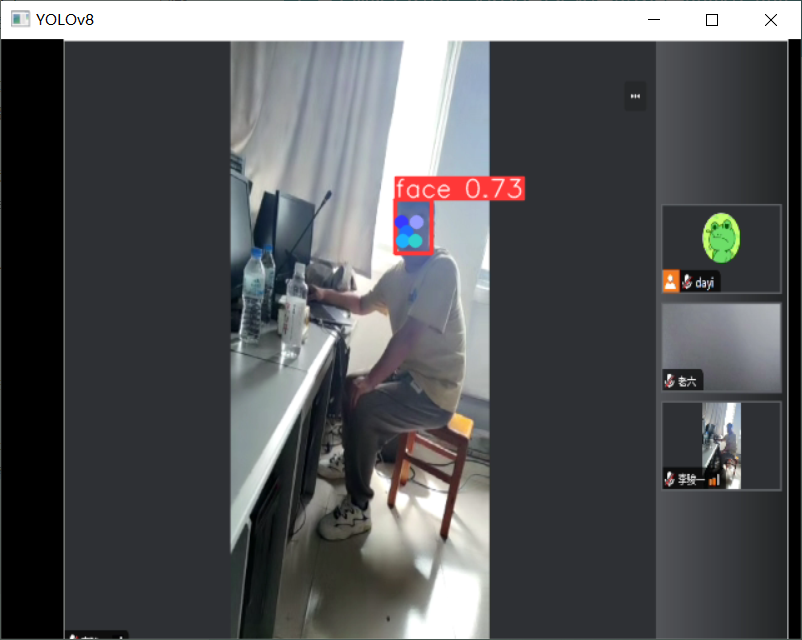
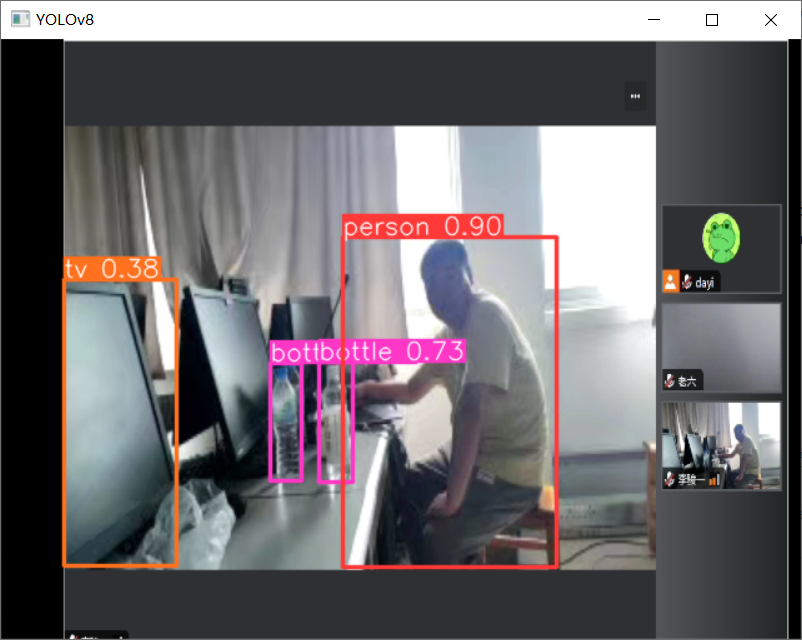
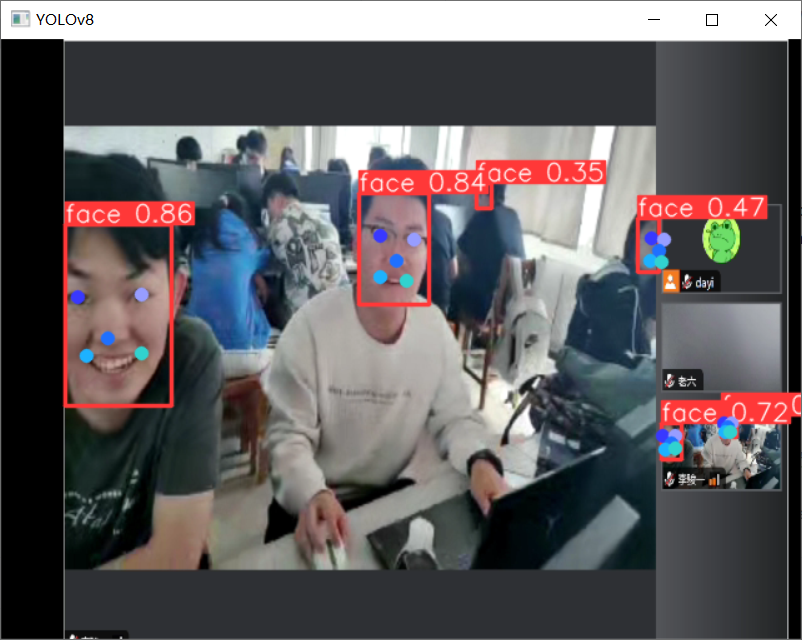
唱歌的图: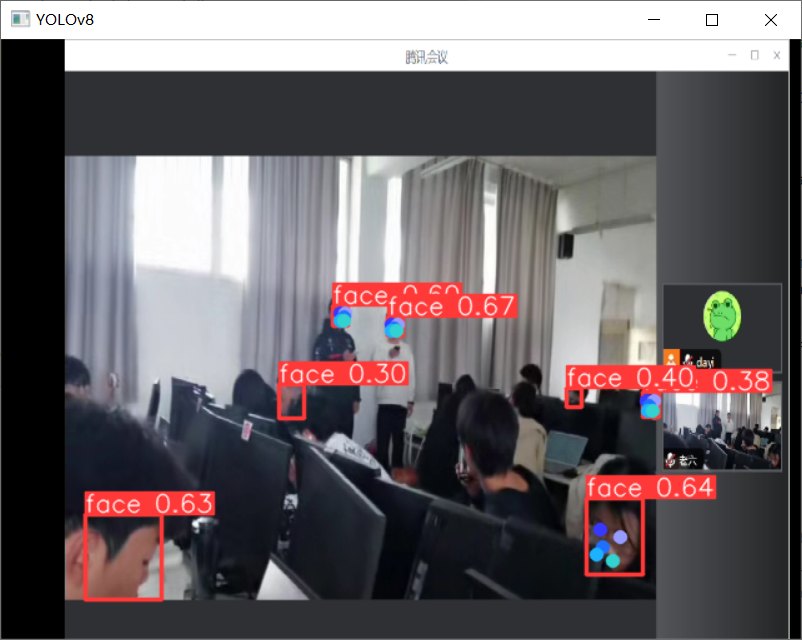
YOLO安装
其实超级简单,复制上就可以啦
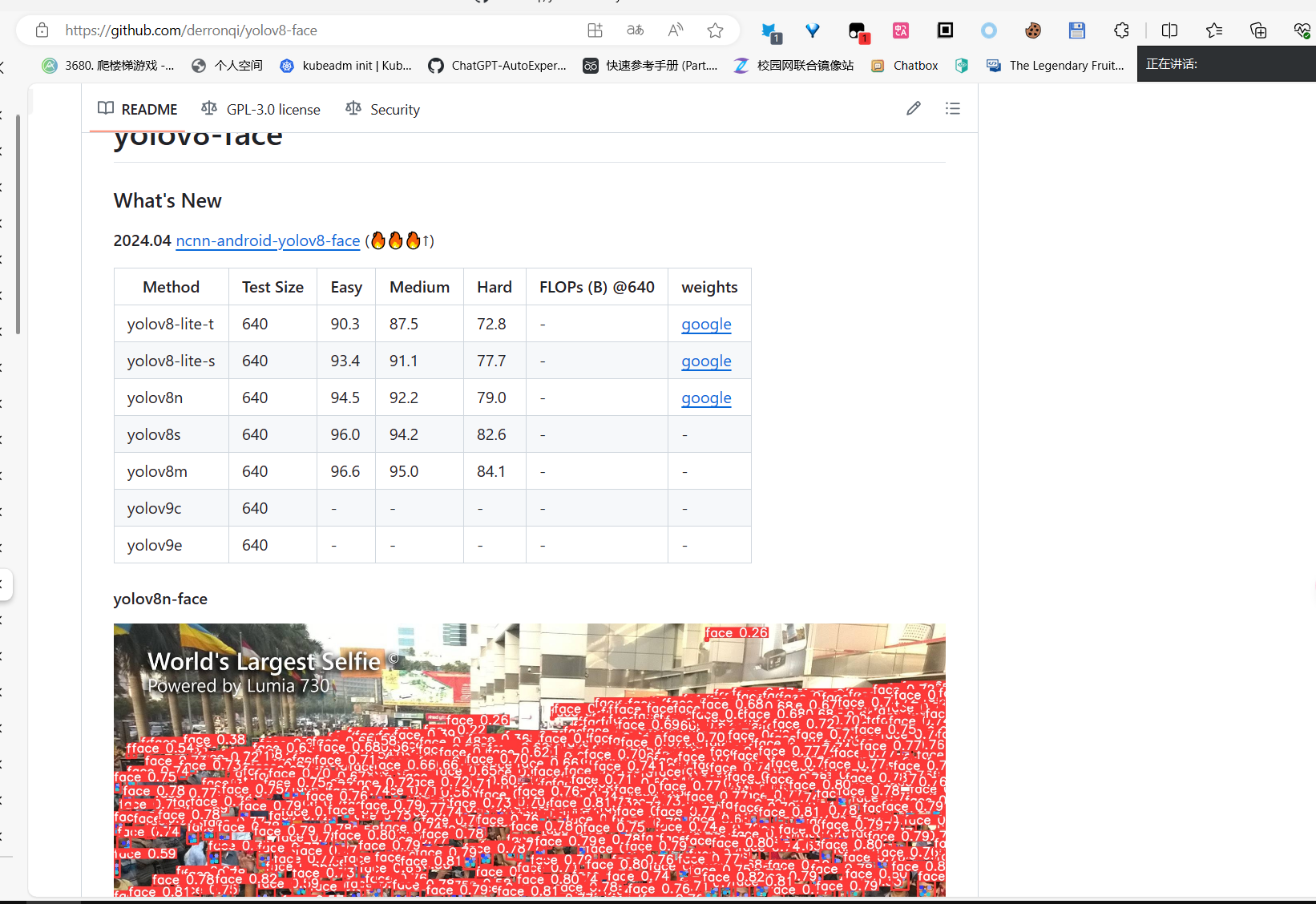
模型
用的这个模型,来识别的人脸。
https://github.com/derronqi/yolov8-face
下载链接:https://drive.google.com/file/d/1qcr9DbgsX3ryrz2uU8w4Xm3cOrRywXqb/view?pli=1
flask强制缝合怪代码
flask路由代码如下
1 |
|
HTML代码
1 | <li class="layui-nav-item layui-nav-itemed"> |
执行效果:点击链接后可以正常弹计算器:
执行效果:下载模型后弹出计算器
执行效果:退出后返回人脸识别。
豆瓣热看
其实就是把相关文件整合了一下下,然后稍微通用了一点,这样就不是静态的而是动态的啦。动态生成一些内容,但是由于时间限制还是有待改进,但是我觉得已经可以用啦。
豆瓣有网页可以看最热门的几个视频。
缓存机制
我也不知道为什么我想先说下这个缓存。改成了动态获取评论,因此,评论内容其实就是实时爬下来的。但是后面写代码的时候,发现,好多好多都会重复调用(比如词云,ai绘图..但是爬取过程实际上是不快的,于是便有了直接缓存函数返回值)
接着聊聊这个缓存机制叭~
你看,如果每次有人访问页面,程序都得重新爬一遍评论,这效率可就有点捉急了。所以我就想着,要不给它整个缓存?
于是乎,我就祭出了 Python 的三大缓存装饰器:lru_cache, cached_property 和 cache。它们可以帮我把一些常用的数据缓存下来,下回再调用的时候就可以直接从内存里拿,省了不少事儿~
比如说,像获取电影标题、获取评论这种函数,我就给它们都加上了 @lru_cache 的装饰。这样一来,同样的请求就不会重复爬取了,速度提升了一大截!
当然啦,缓存虽好,也不能滥用。像词云图片的生成,我就只缓存了10个。要不然占用的内存就太大了,得不偿失啊。
总之呢,这个缓存机制就是我对程序的一个小优化啦。虽然不起眼,但是细节决定成败嘛,网页的响应速度快了不少。
其实我还想把这个lru的cache改写为定时自动清理自己的缓存,但是稍微有点复杂,实现了一次发现有点不太稳定,时间也比较赶,就匆匆略过了。
因此这个更新时间其实也是为了检测cache有没有生效。
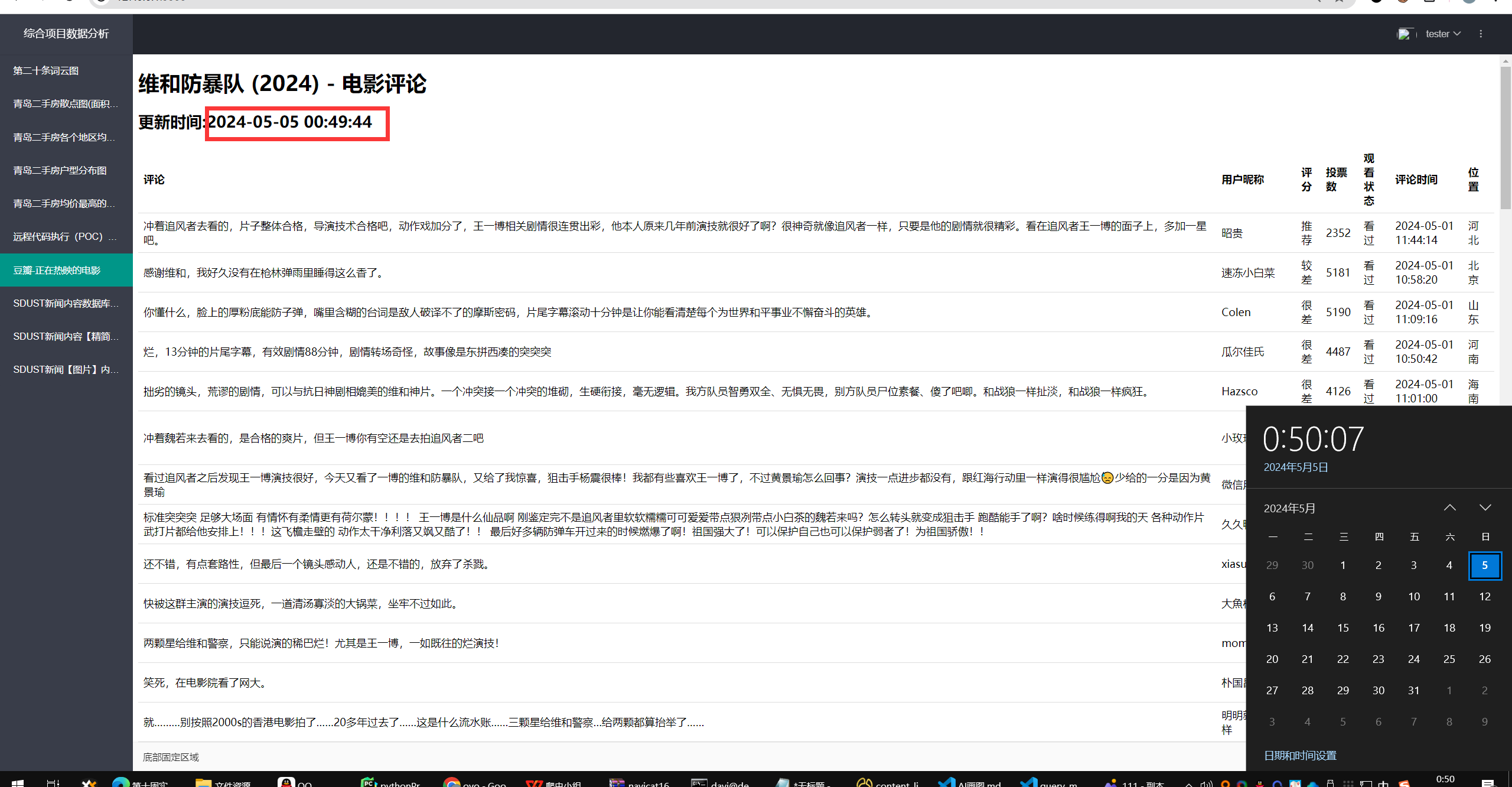
更新时间的实现逻辑也很简单,一个dict就行。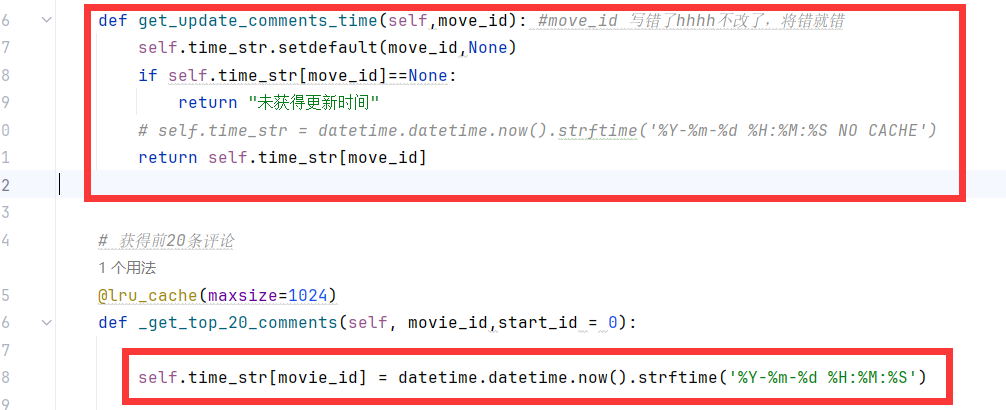
什么,你问我dict要不要缓存?你猜。
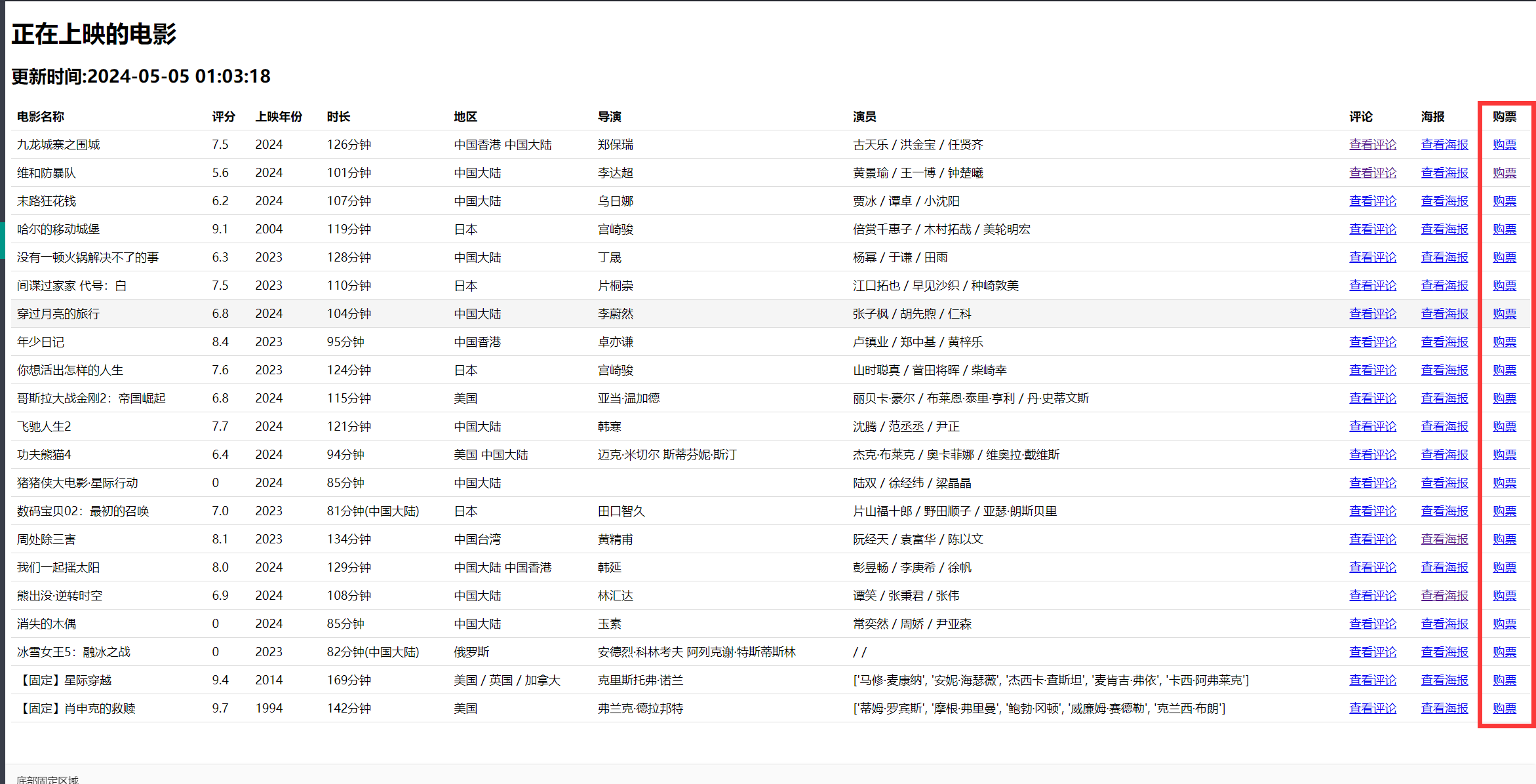
热映电影
最后的效果大概是这样的一个界面:
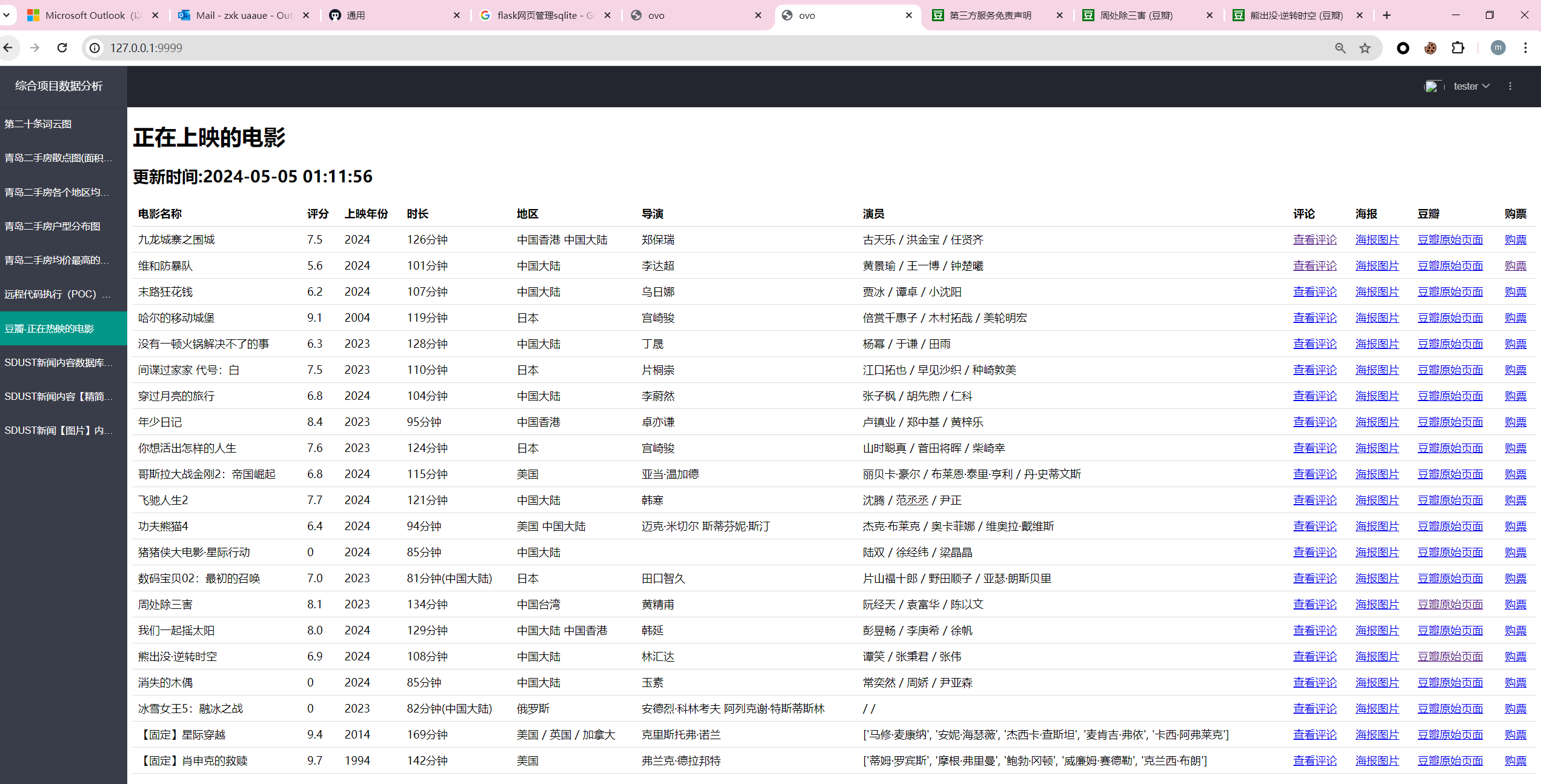
你还可以固定信息哦~
但是内容要手动自己写哦~这里还可以根据subjectid来获得电影的东东。(但是再写就成了豆瓣客户端了hhh)
返回的dict这个样子哦
海报
对于海报的获得是拿的这个: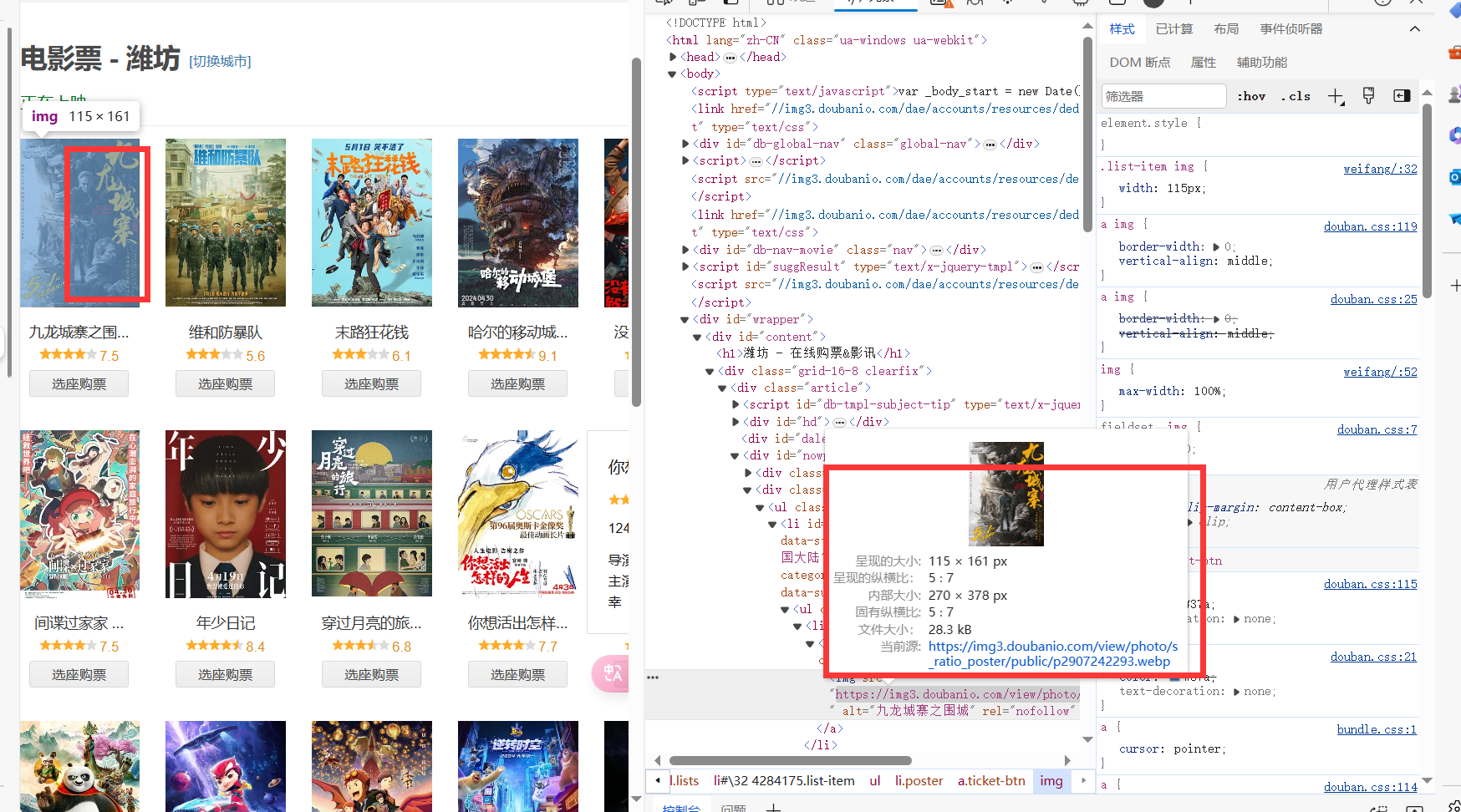
但是拿到链接后,要么要本地缓存,要么修一下防盗链即可。
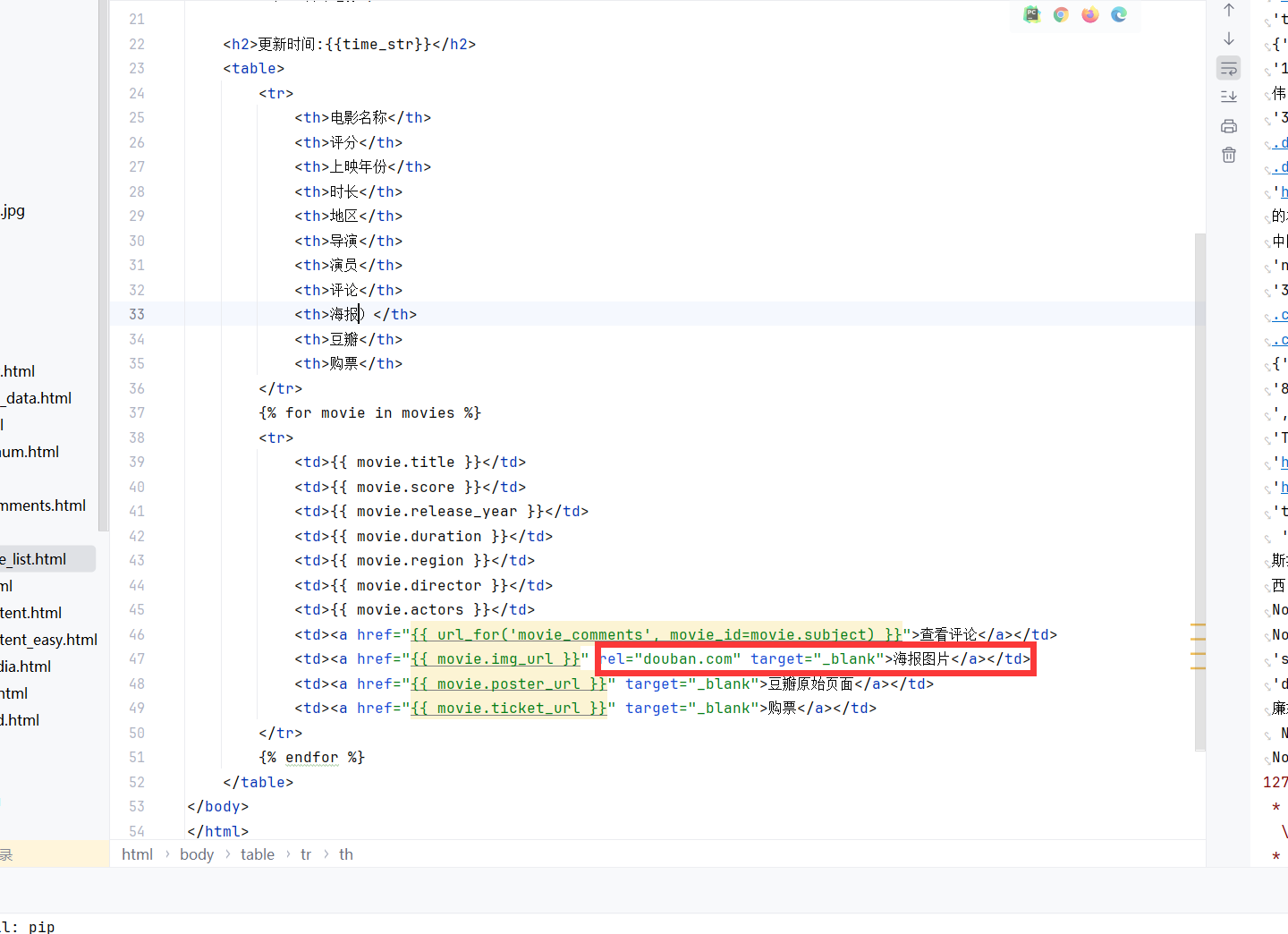
发现这样改会被拒绝。
考虑到本地缓存不一定有版权,所以干脆修防盗链,跳转过去,实际上这个图片是可以直接访问的,所以,直接改成noref也可以滴。
购票功能
其实就是爬的购买的信息的猫眼电影的跳转。但后来发现这个接口不一定是稳定的,有时候豆瓣自己会撤掉,所以不一定真的完美可以用。今天测试还算稳定。
但大部分还是是可以进行购票滴
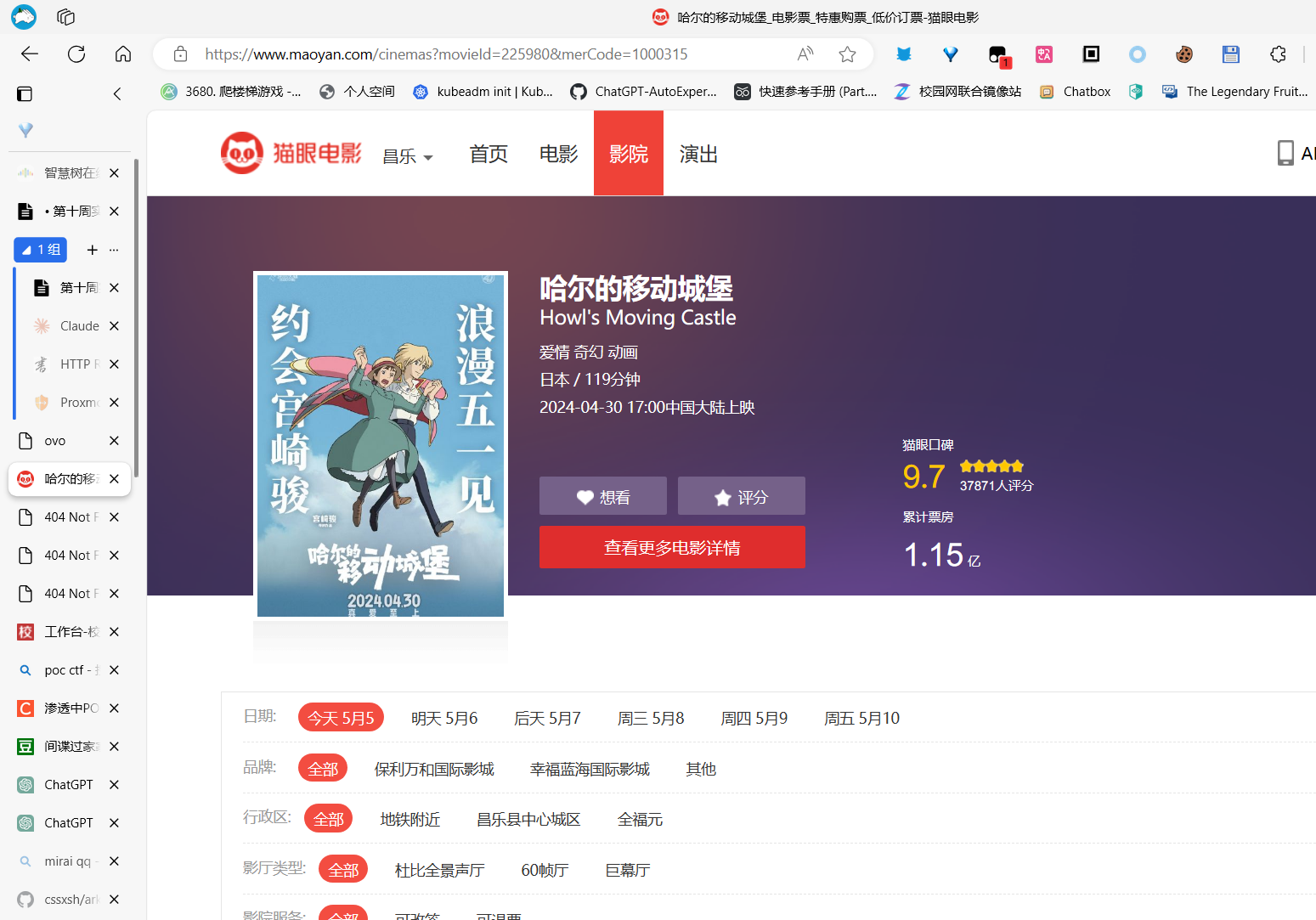
查看评论
说到获取评论那可是这个豆瓣热看小玩意儿的核心功能之一啊!没有了评论,这电影榜单还有啥看头?所以我在这块儿下了不少功夫。
首先呢,我在 dayi_class_getpop 类里整了一个 get_more_comments() 方法,专门用来获取更多评论。你别看这方法就几行代码,但可厉害了!它通过循环调用 _get_top_20_comments() 方法,每次获取20条评论,最后把所有评论一股脑儿合并到一个列表里,想要多少有多少!
然后呢,在 /comments/<int:movie_id> 路由里,我先调用 get_top_20_comments() 方法获取该电影的前60条评论。为啥是60条?因为在这个方法里面,我偷偷摸摸地又调用了 get_more_comments() 方法,传了个3进去,也就是要获取前3*20=60条评论,嘿嘿~
接着,我又调用 get_update_comments_time() 获取评论的更新时间,再用 get_movie_title() 拿到电影标题。这些数据都整合好了,再丢给评论页的模板,一个漂亮的评论列表就呼之欲出了!
哦对了,光有评论列表多没意思啊,所以我还加了个词云图,贼拉酷炫!调用 generate_wordcloud() 方法,传入电影ID,就能自动生成一张由评论关键词组成的炫酷词云图。不过说到这儿,我发现个小问题:这个方法里我只用了前20条评论,是不是有点浪费?都获取60条评论了,不如全都用上,让词云图更全面、更闪亮!回头我得改改。
还有啊,60条评论一股脑儿都堆页面上,是不是有点儿太多了?万一把用户看晕了咋整?我寻思着,不如整个分页功能,每页20条评论,用户爱看哪页点哪页,这样体验更棒。不过目前还没加,看看小仙女们的评论也不错hhh。
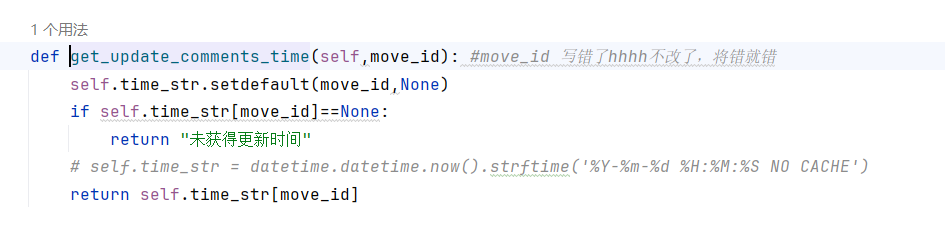
说起这个 get_update_comments_time() 方法,我在里面用了个字典来保存每部电影的评论更新时间,还挺机智的吧?不过话说回来,如果电影多了,这字典会不会占地儿太多?我得想个法子,定期清理一下,把那些老掉牙的电影时间记录给删删,省得占地儿。
这段获取评论的代码已经算是比较完善了,该有的功能都有了,还有词云图这样的亮点。但刚才提到的那些小问题,我回头再好好琢磨琢磨,看看还能不能再优化一下。嗯,就先说到这儿吧!
具体的图片大概这样:
从任何一个电影点进来。
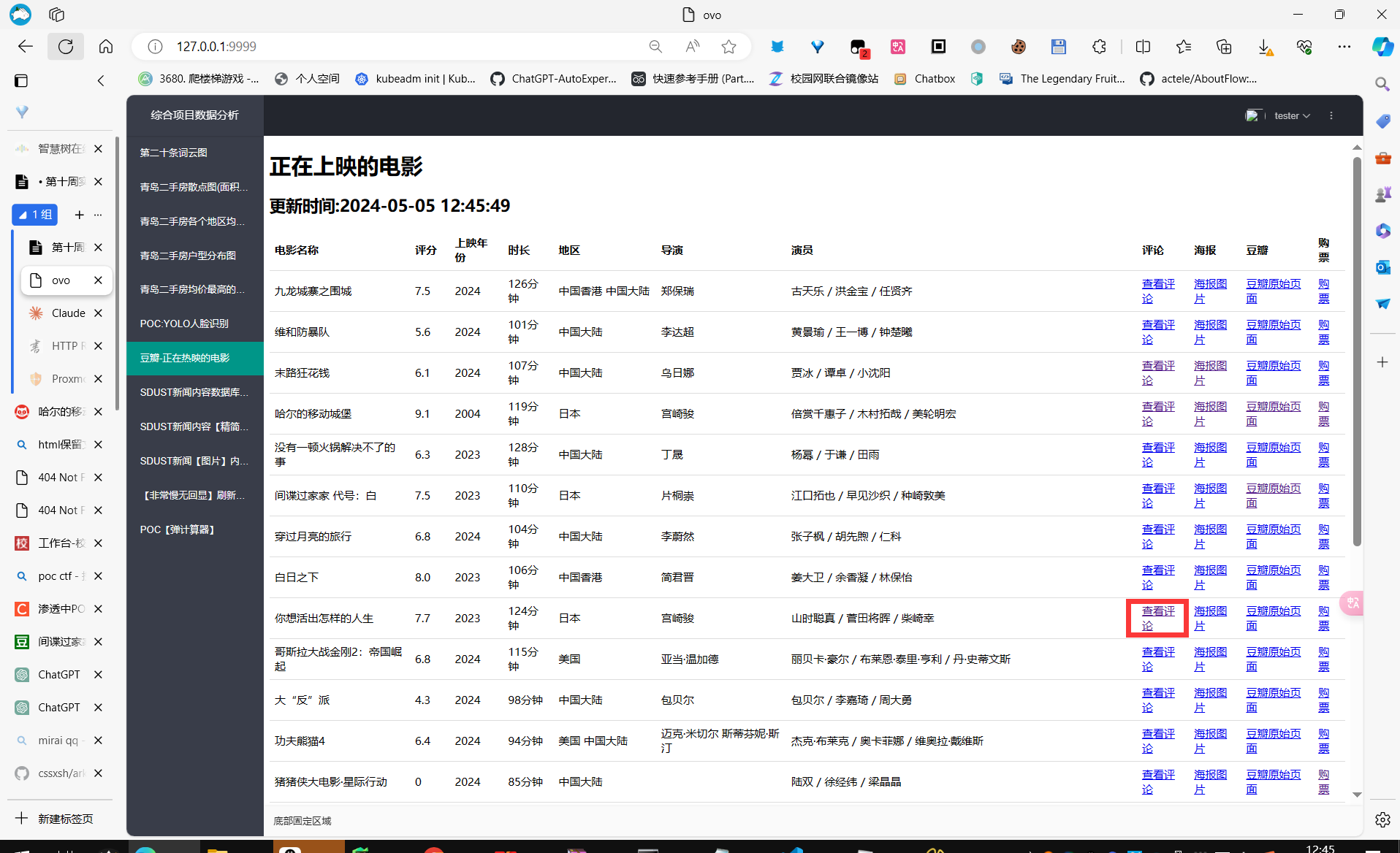
点进去后有评论内容:
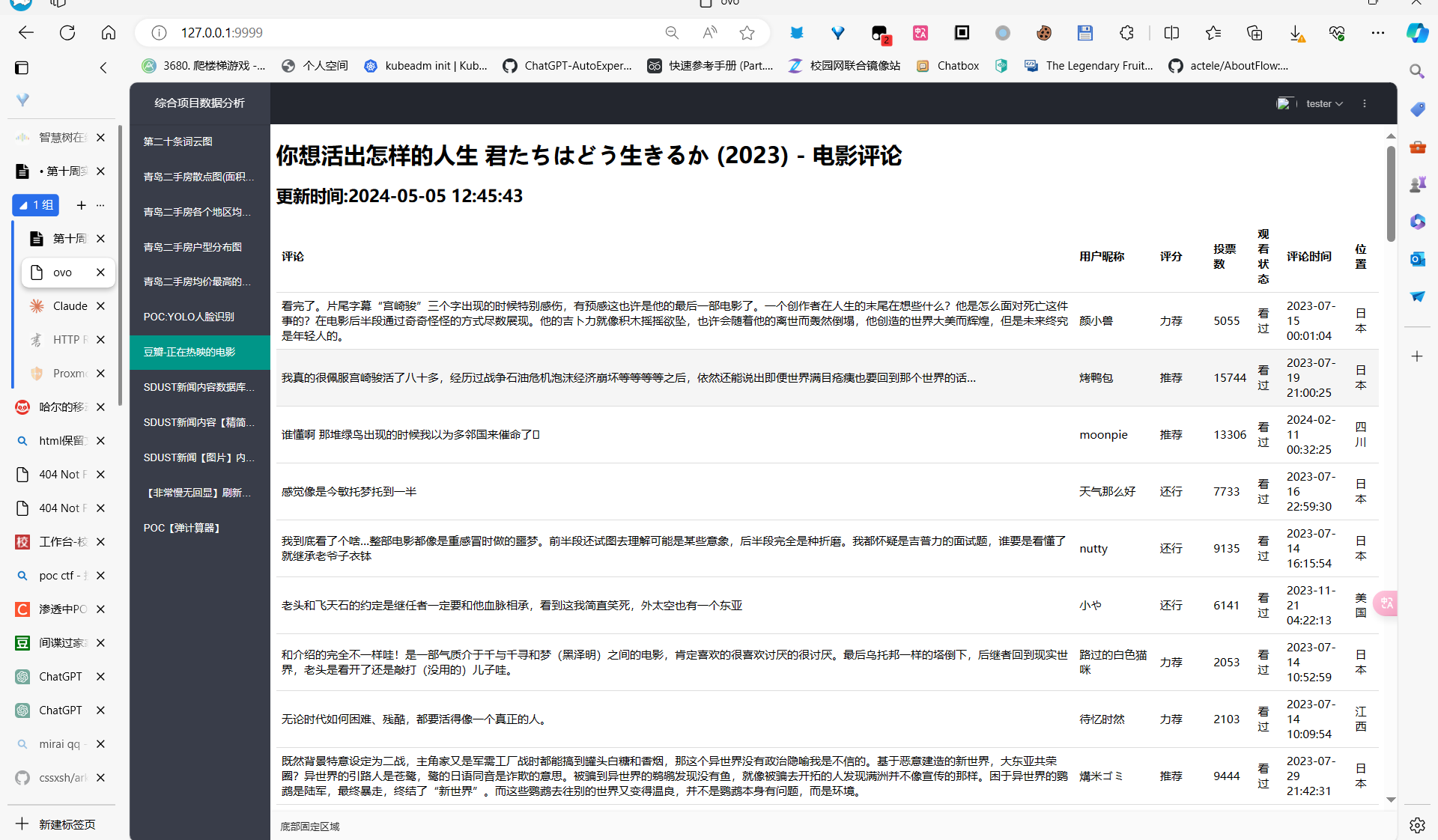
看到最后词云也差不多可以生成完毕,就可以看啦
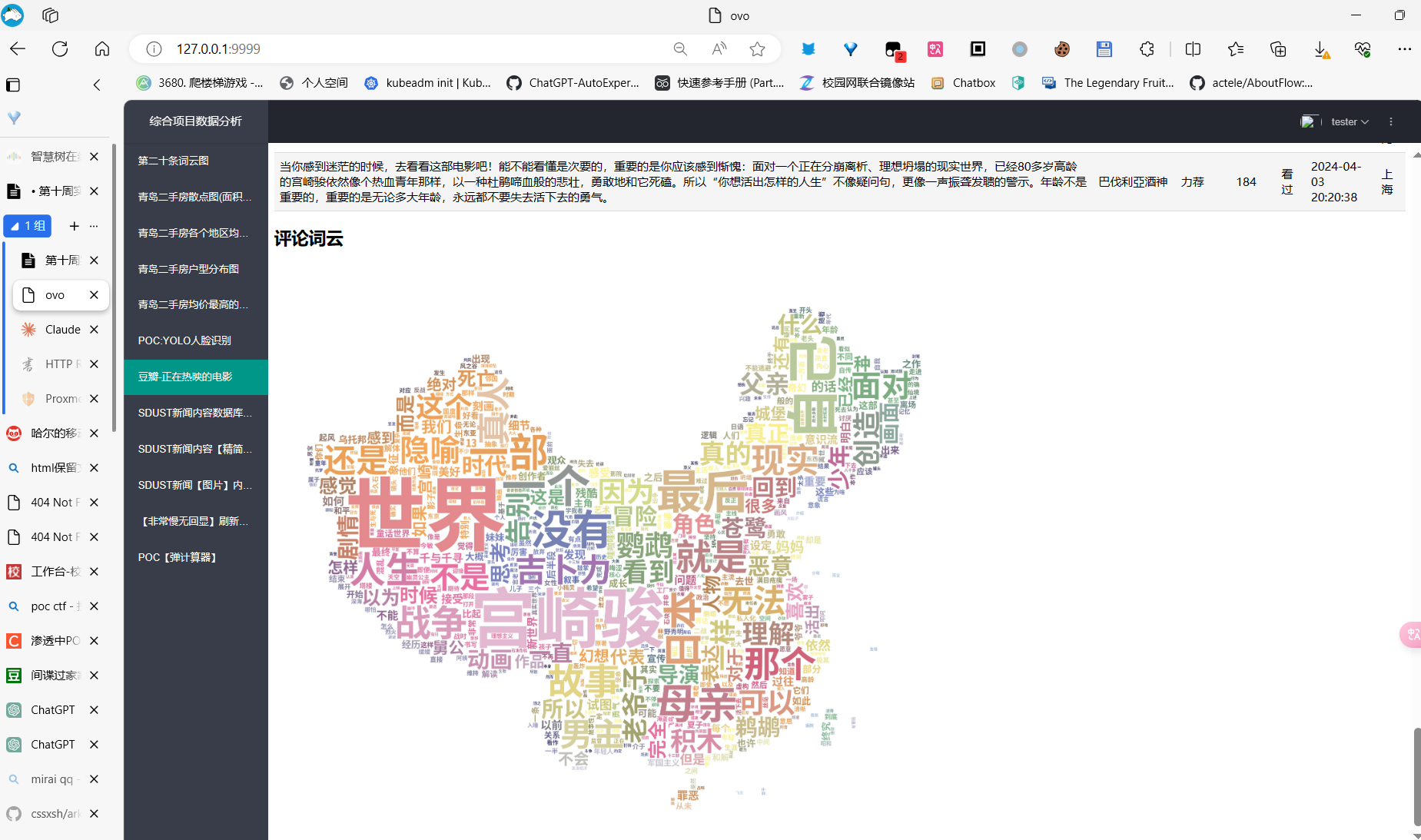
代码细节
这里是app的逻辑,也就是根据具体的电影id(也就是豆瓣的subject_id)来进行调用。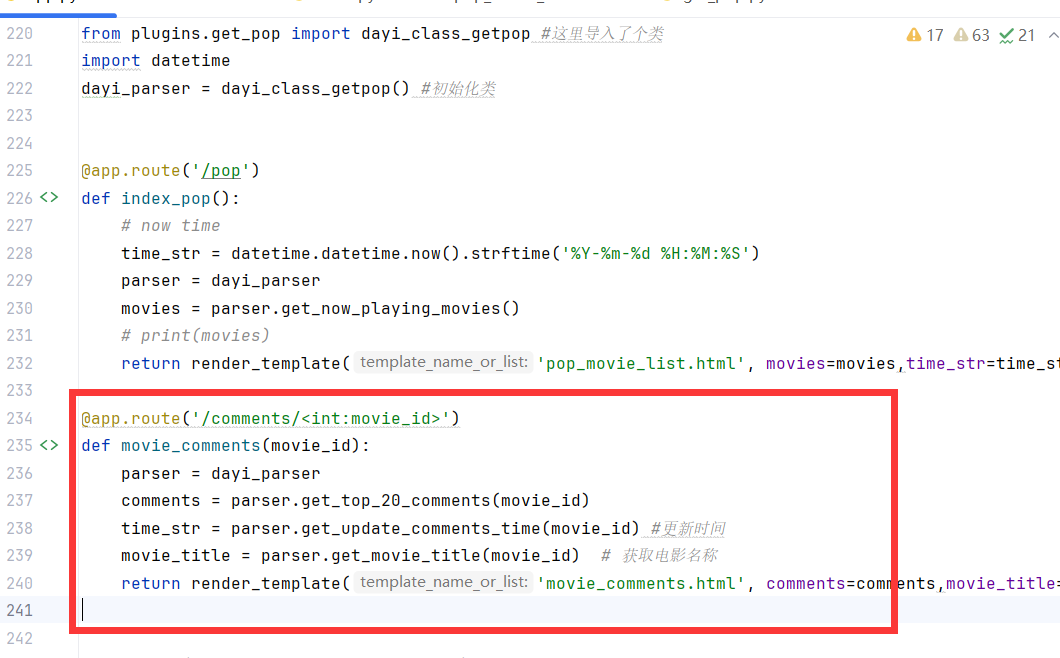
更新时间的逻辑前文已经讲过,存一个dict即可。
获得评论的逻辑(有逻辑嵌套,一次获得20条评论):

然后套到这里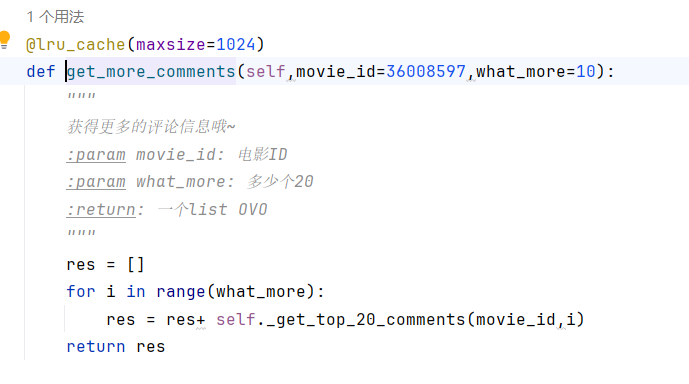
评论就是一个普通爬虫,连UA都不伪装的那种(考虑到评论不是实时更新的,这里的有缓存)
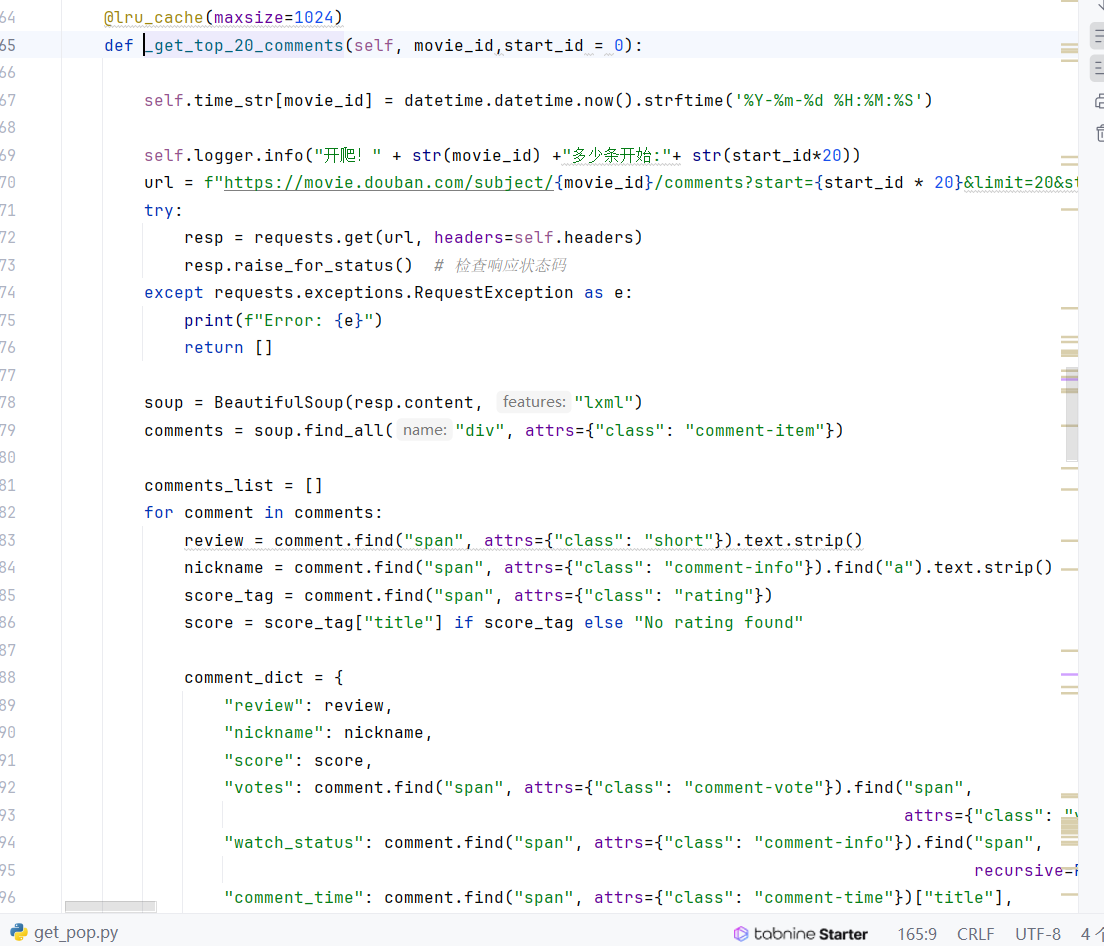
另外由于原爬虫不能获得到标题,这里又写了一小部分
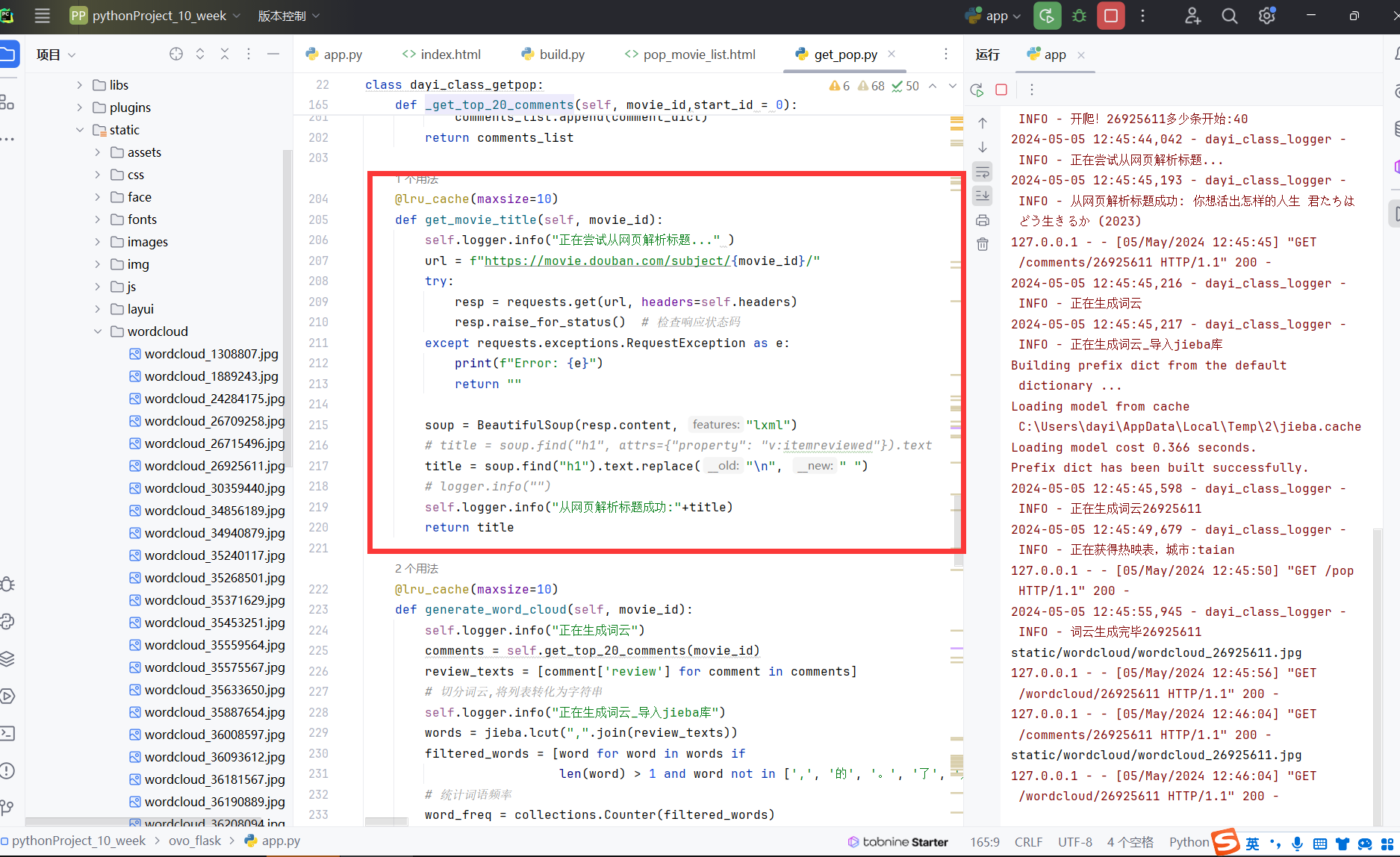
词云功能
美观调整:
把底图稍微调整了一下,调了下对比度,然后把图片的旁边截断:
然后根据背景颜色染了下色。
效果真的我觉得超级好看ovo
大概有这个效果:

这是罗小黑,小黑~(不是哪吒)
小黑~
代码实现细节
跟课上一样啦:获得词->jieba分词->统计词频->塞进去->染色
不过稍微调整了一下,让图片生成出来好看一点。本来打算这里异步处理,后来发现请求不太影响效率。
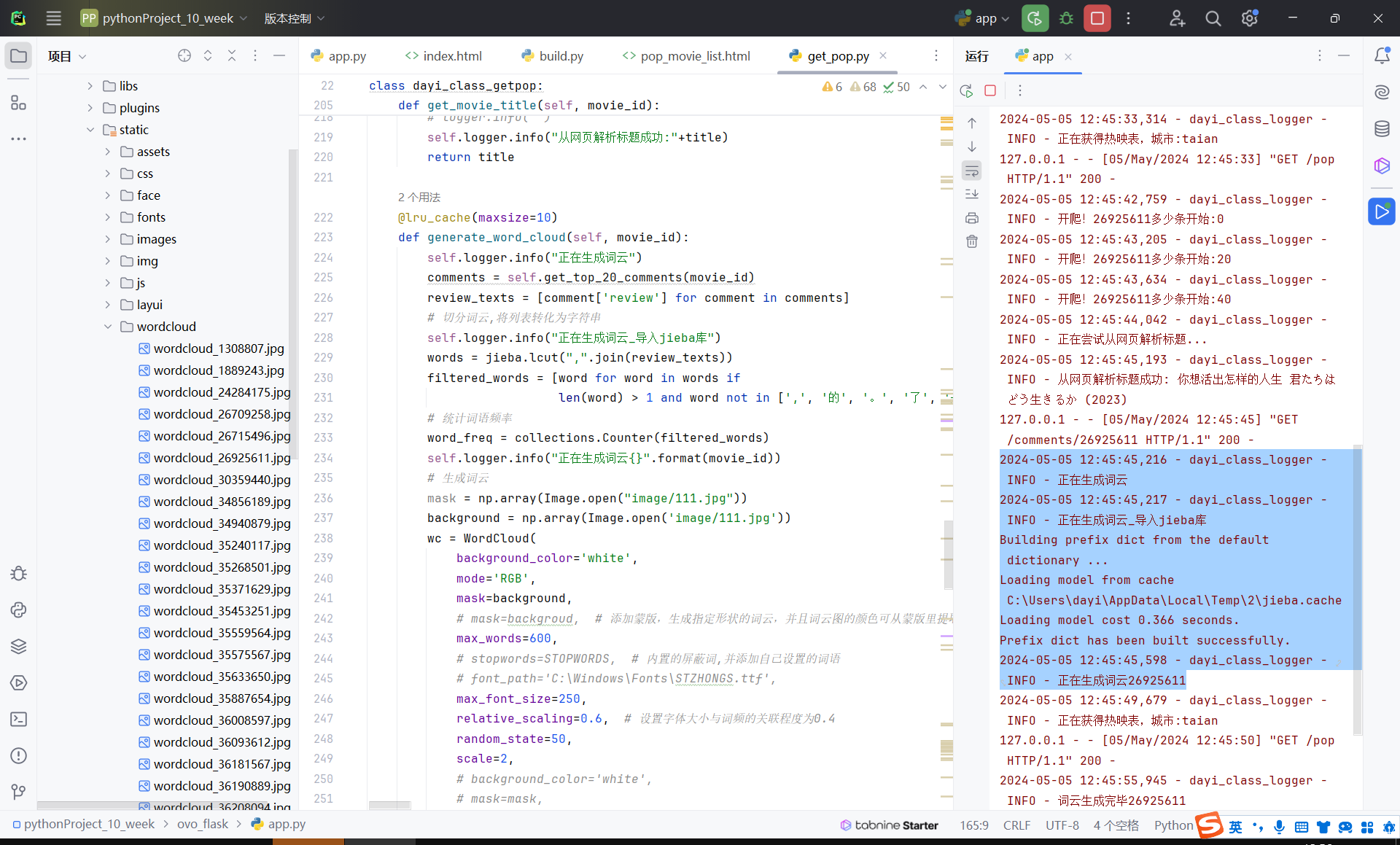
生成完毕之后保存到静态文件库里
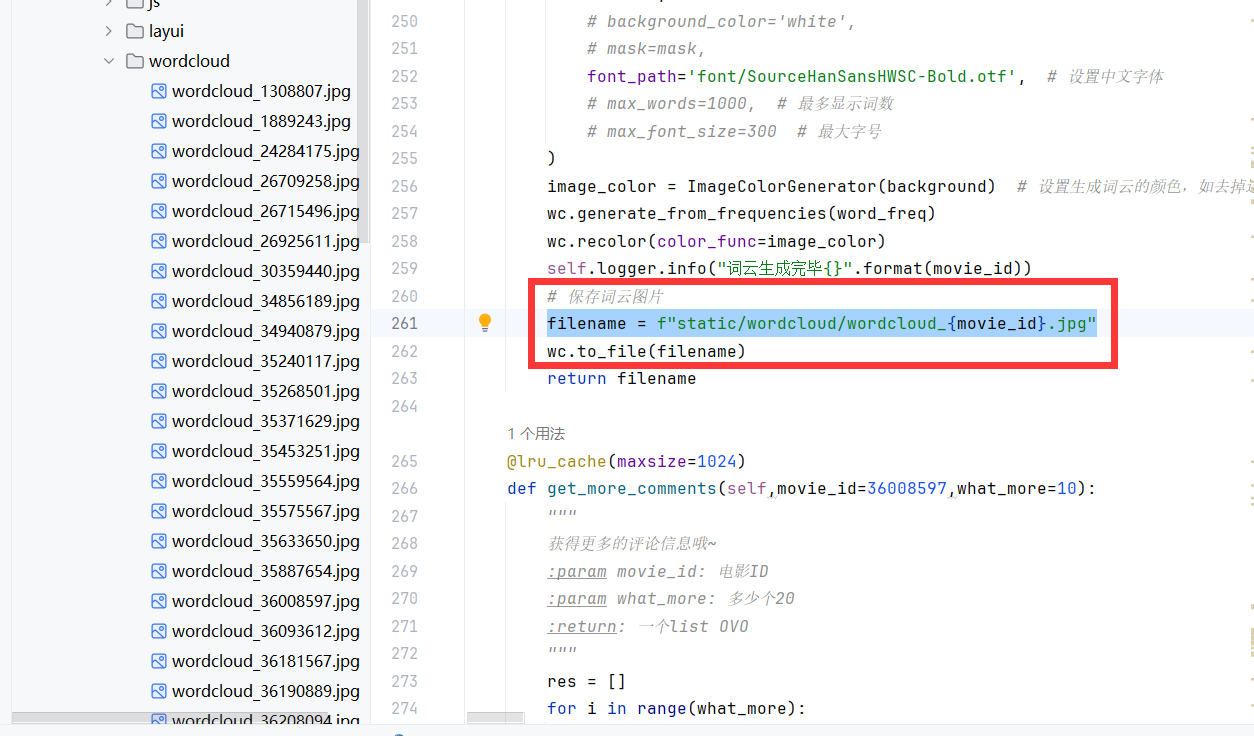
然后返回文件名,flask处理一下静态文件返回就可以了。
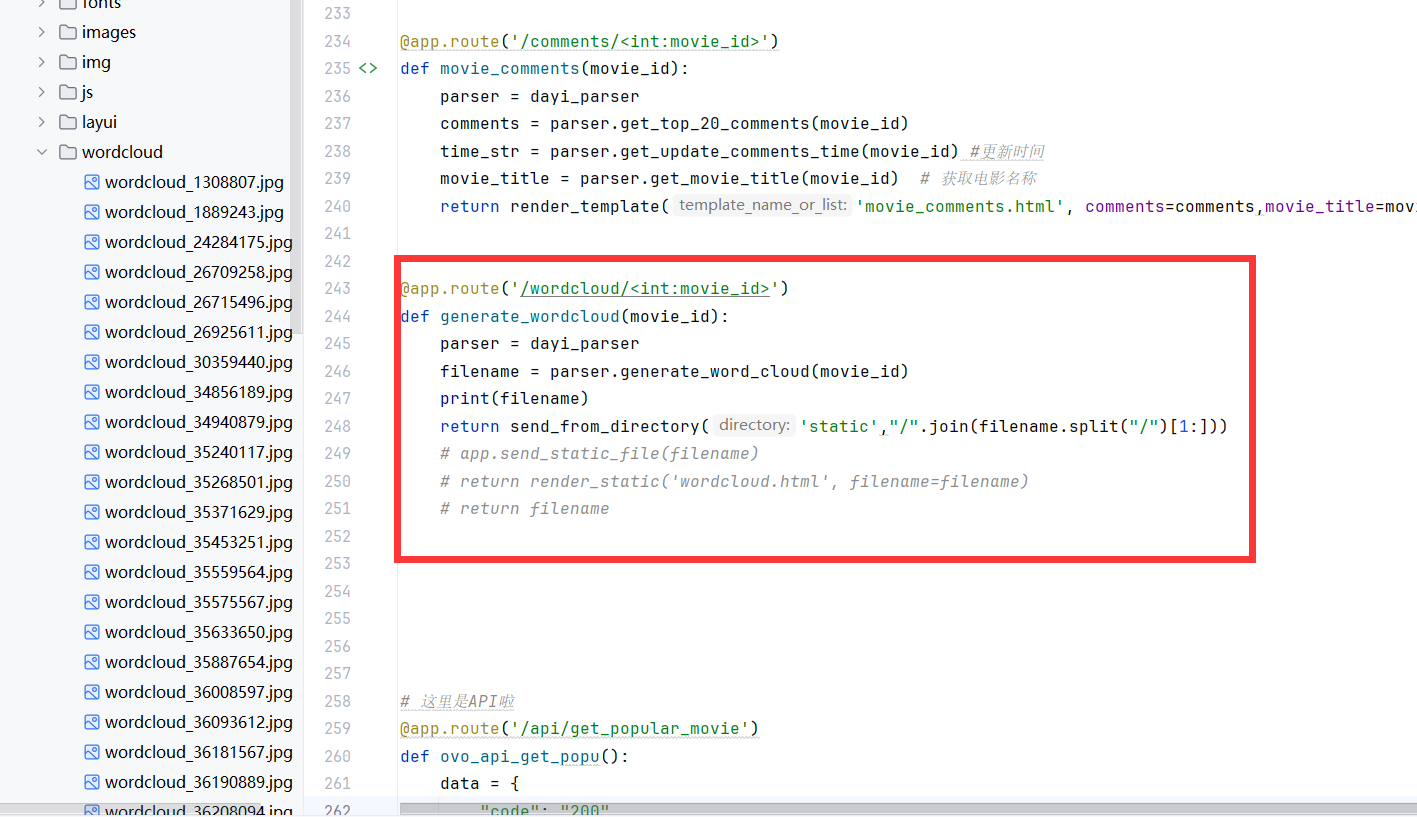
再来一张图:
小模块类和日志输出
小模块的实现
这是一个类啦,本来是打算写类的相互继承,来进行写一个大的东东,但是后来发现调试爬虫的时间有点占精力,于是就先写一起。先实现功能再规范,我觉得是一个很好的事情。特别是这种小项目
这里初始化可以把header传过来,可以结合fake_useragent来生成实例。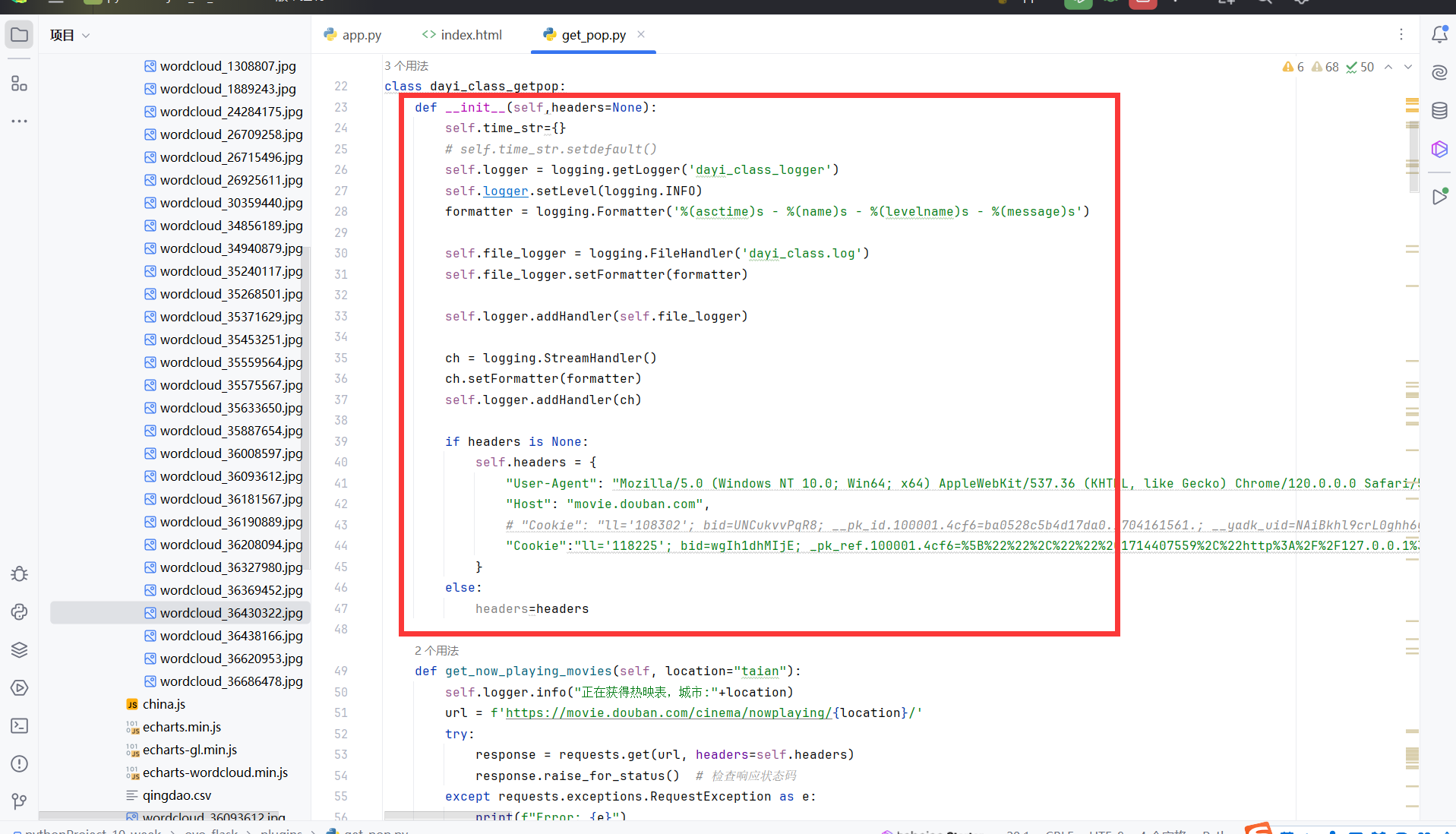
唯一的缺点是没有写释放函数,不过感觉无关紧要,这里跟数据库的驱动不同。我看着跟数据库的驱动比起来的话,好像也没有什么特别需要添加的内容。也没有什么东西需要手动释放。
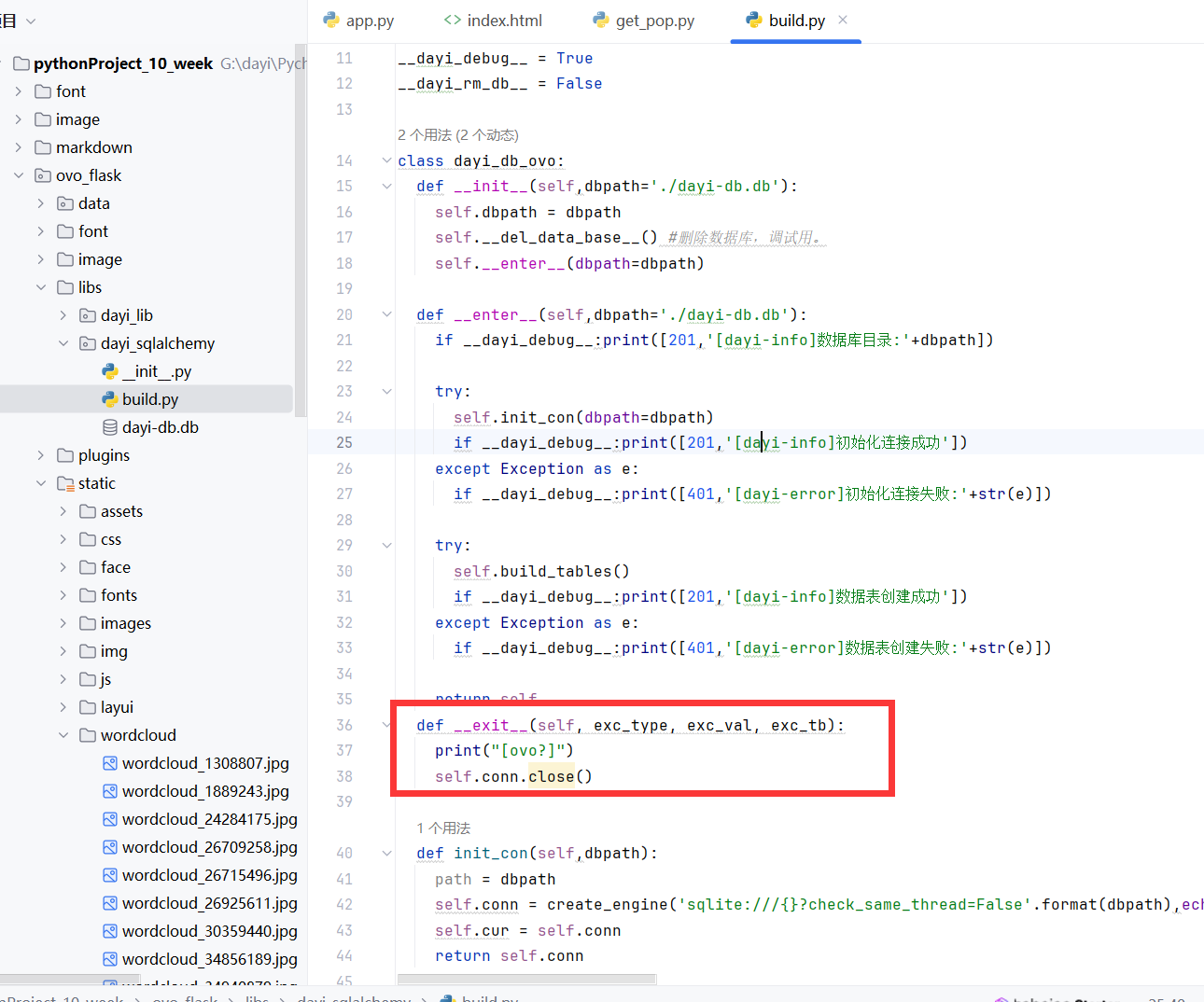
然后就是几个函数。
日志们
其实flask基本上就只做了路由,剩下的都是这个小插件的类来实现的,有谁不喜欢日志呢ovo
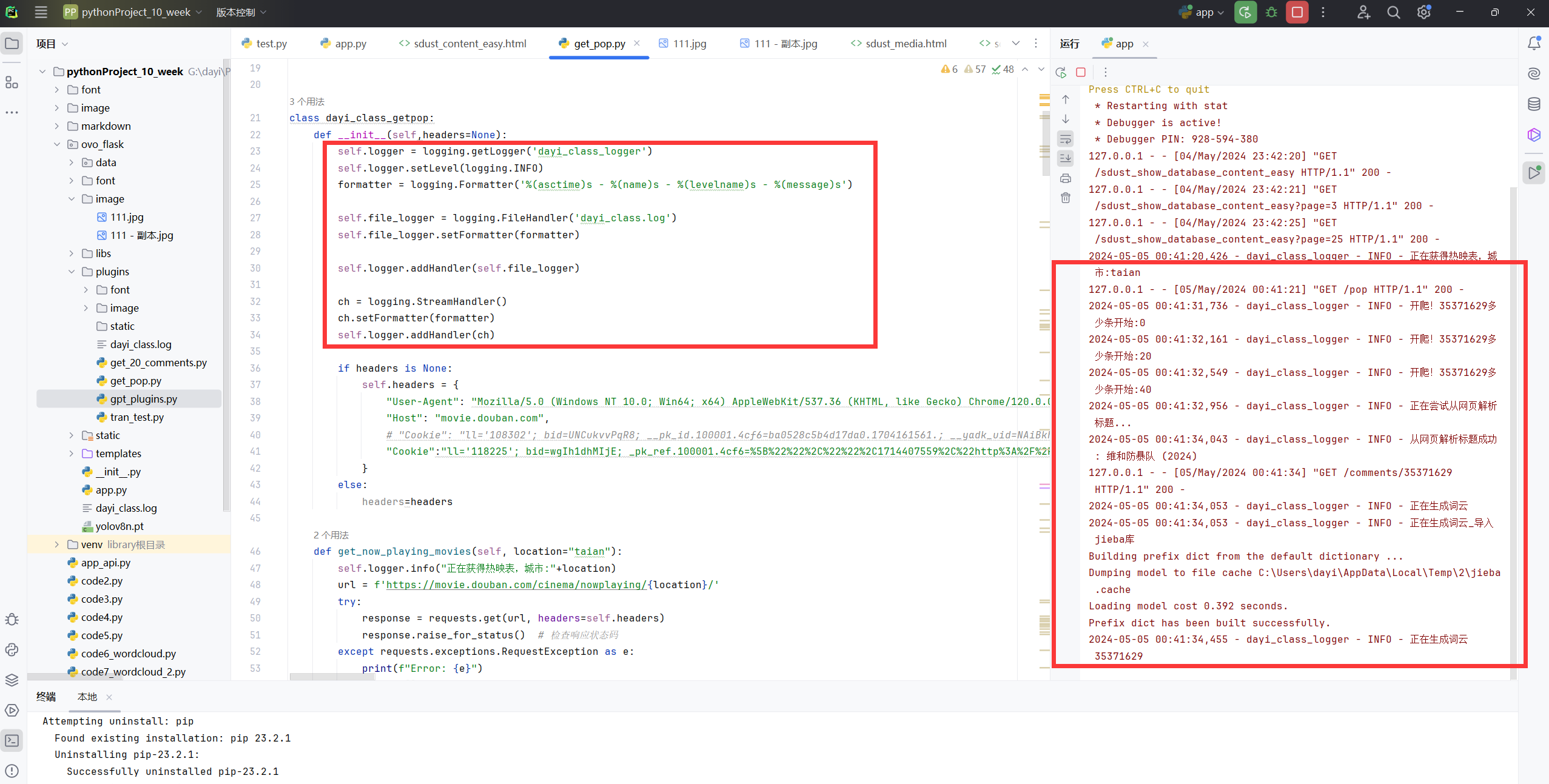
看看这个日志还是很喜欢滴吧?
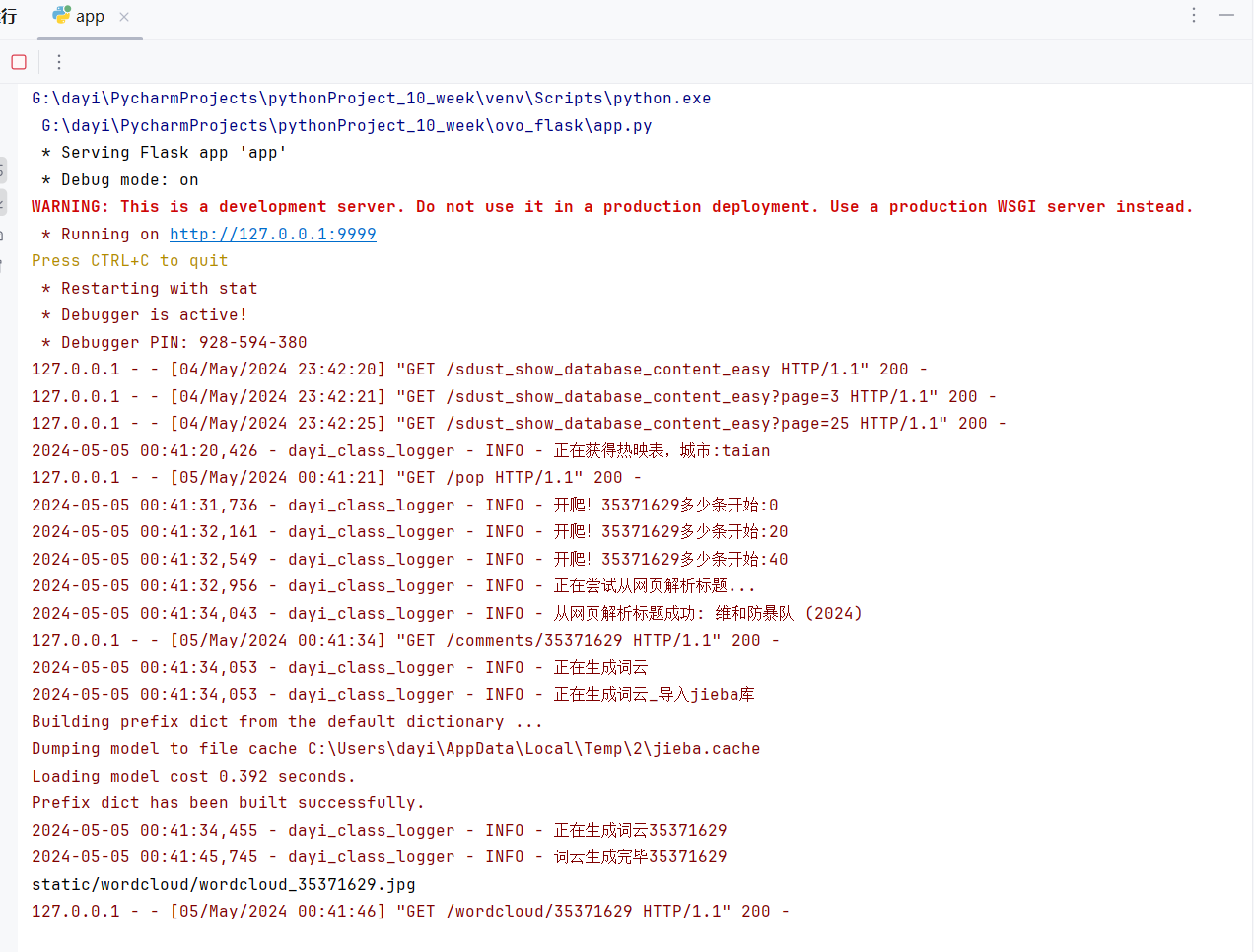
对于这个类有专门的模块日志输出哦
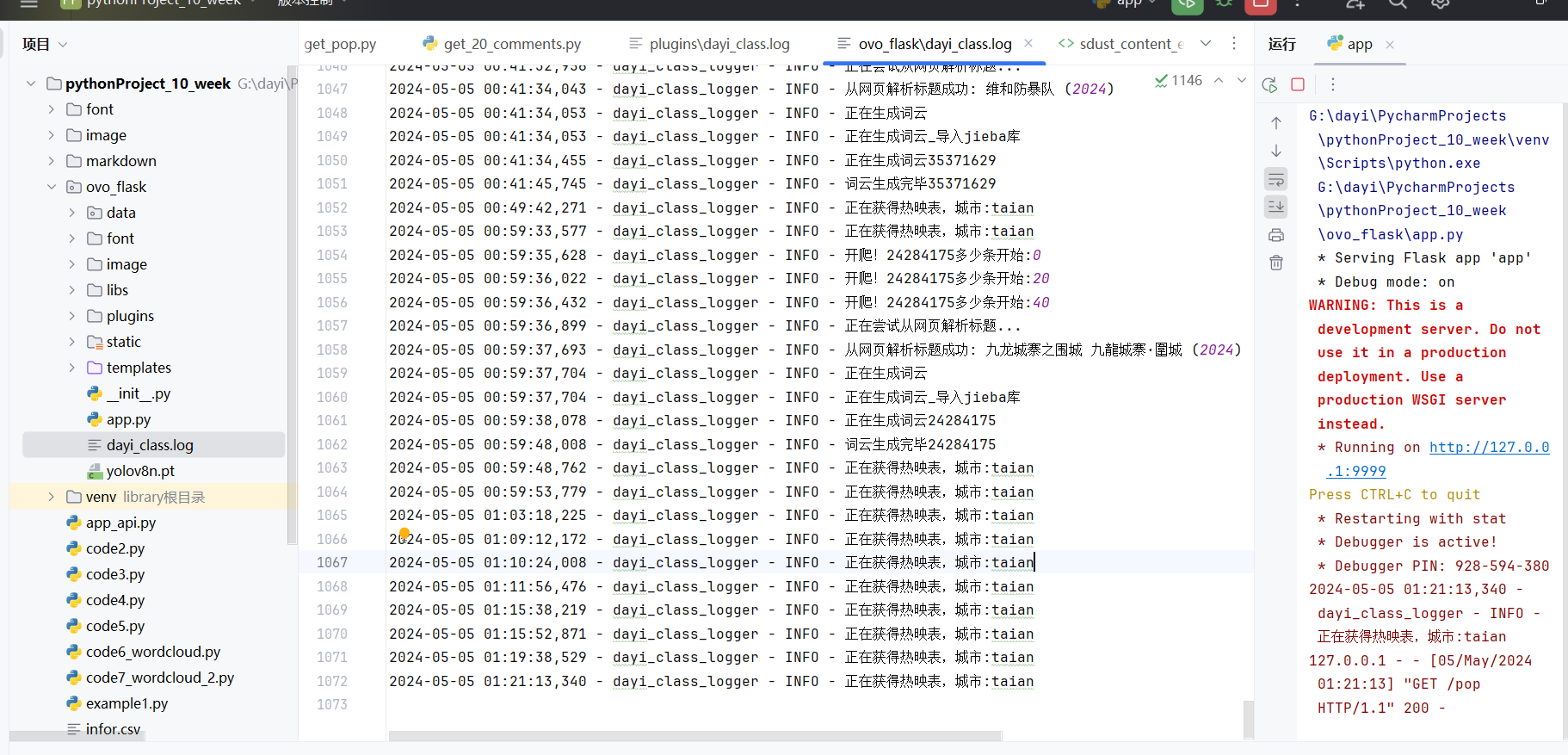
还有小模块的日志,独立输出出来
这样实际上flask的app一个类就可以完成所有滴事情~
小模块的导入
很方便很简单哦~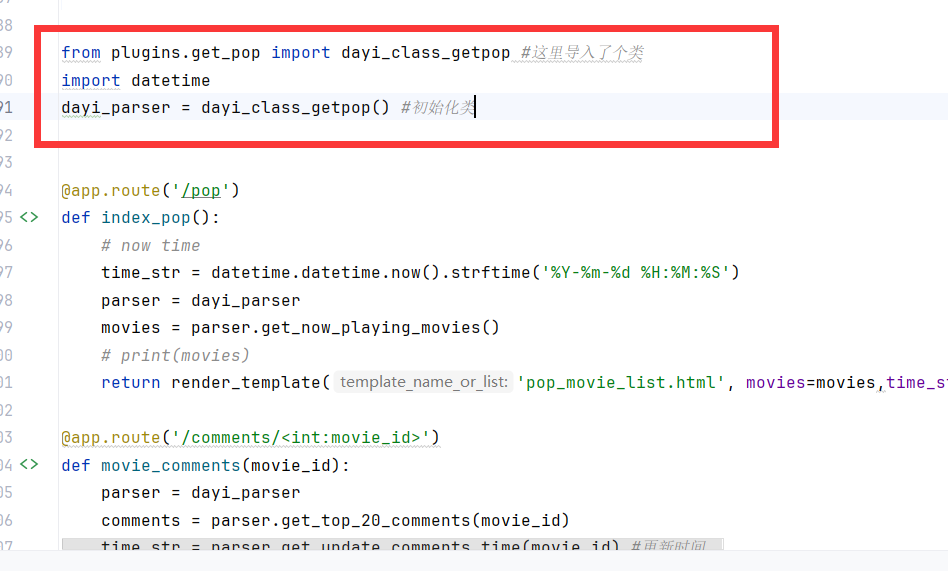
具体的模块作用:
代码定义了一个名为 dayi_class_getpop 的类,提供了多个方法来处理与电影相关的数据和生成相关内容。
详细分析如下:
初始化方法 (init)
- 功能: 初始化类实例,配置HTTP请求头,设置日志记录。
- 实现: 使用
requests库来发送HTTP请求,使用logging库进行日志记录。
获取当前热映电影 (get_now_playing_movies)
- 功能: 获取指定地点的当前热映电影列表。
- 实现: 发送GET请求到豆瓣电影的热映页面,解析HTML内容以提取电影信息。
获取电影评论 (get_top_20_comments, _get_top_20_comments, get_more_comments)
- 功能: 获取指定电影的前20条评论或更多。
- 实现: 使用
requests发送请求到豆瓣电影的评论页,通过解析HTML内容提取评论数据。利用lru_cache提供缓存功能,减少重复请求。
生成词云 (generate_word_cloud)
- 功能: 根据电影评论生成词云。
- 实现: 利用
jieba进行中文分词,使用wordcloud库生成词云图像。
翻译和生成AI图片 (dayi_get_ai_pic)
- 功能: 利用评论生成与电影相关的AI图片。
- 实现: 使用
googletrans进行评论关键词翻译,构造图片生成请求发送到图像生成API。
日志记录
- 功能: 记录操作日志,帮助跟踪错误和程序执行情况。
- 实现: 使用
logging库配置了文件和控制台日志记录器。
异常处理
- 功能: 处理网络请求或其他操作中的异常。
- 实现: 使用
try-except块捕获异常,保证程序的健壮性。
课上代码
code1 第一个代码
1 | # 单行注释 |

1 | # 单行注释 |

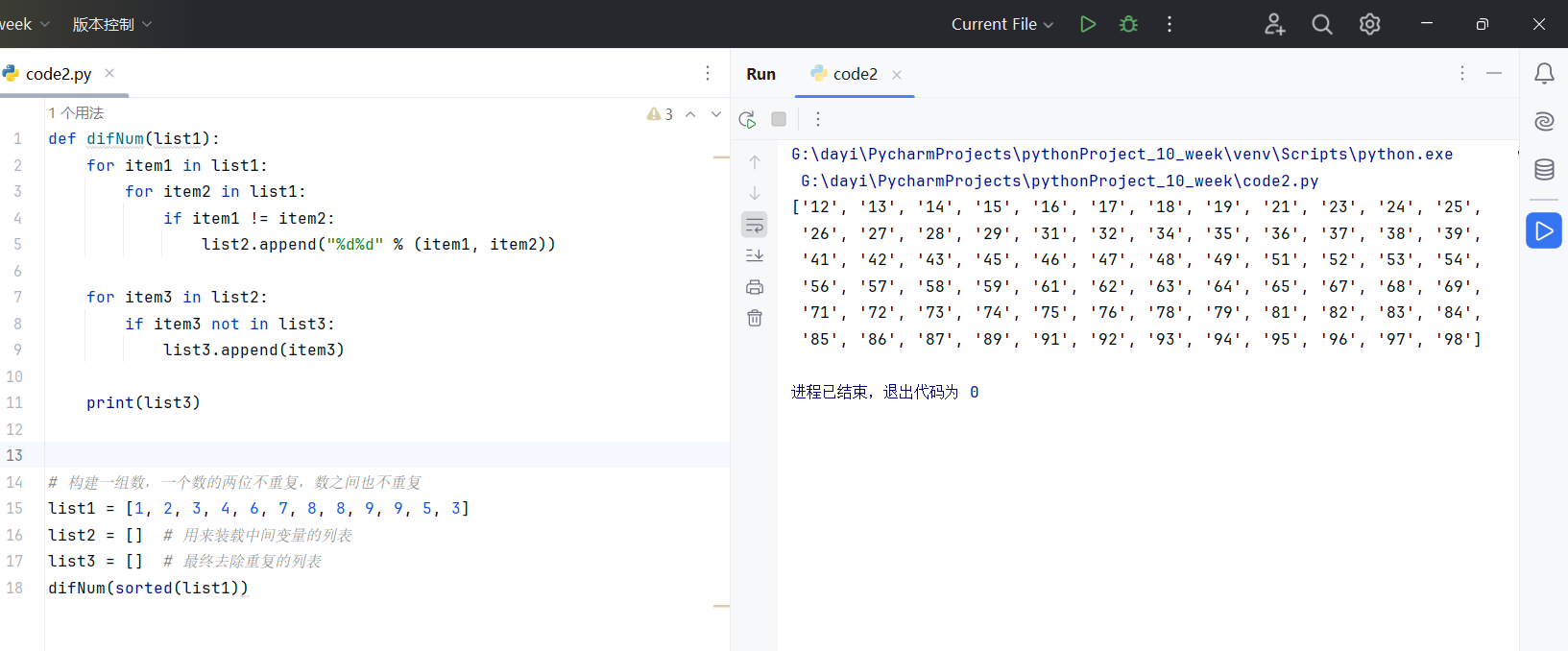
code2 第二个代码
1 | def difNum(list1): |
code3 类继承
1 | class Person: |
code4 豆瓣爬虫
镜像源
快下但是好像pycharm不是很喜欢。卡卡的
北外(ustc跳转)镜像源:https://mirrors.ustc.edu.cn/pypi/web/simple

或者直接通过pip install requests beautifulsoup4 bs4 -i https://mirrors.ustc.edu.cn/pypi/web/simple安装

代码
1 | # 获取请求,给远程服务器发送信息 获取数据 |

code5 爬虫爬多页
1 |
|

code6 词云1
1 | #pandas做逻辑清洗 |
code7 词云2
去掉语气词
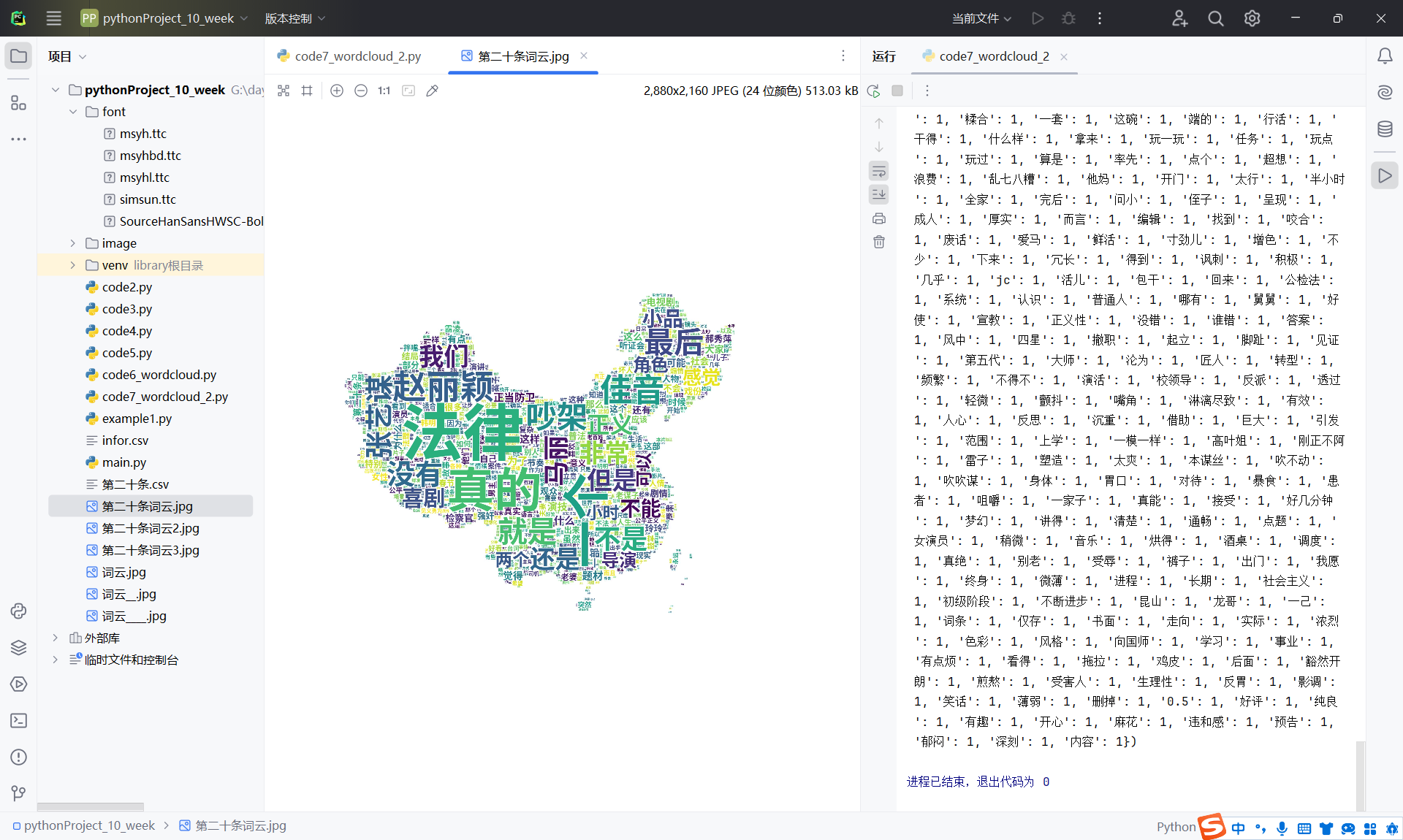

1 | #pandas做逻辑清洗 |
code8 flask

1 | from flask import Flask, render_template, request |
code9 index.html
1 | <!DOCTYPE html> |

code10 复制下文件
压缩包解压拖过去就可以

app.py
1 | from flask import Flask, render_template, request |
fix:
wordcloud_html:
1 |
|
code11 散点图
app.py新增
1 | from pyecharts.charts import Scatter |
散点图

code12 map
新增
1 | from pyecharts.charts import Map |
Code13 Pie
1 | from pyecharts.charts import Pie |
Code14 bar
1 | from pyecharts.charts import Scatter, Bar |

第十周实训-附录
这里只包括一些核心代码,具体滴请看压缩包啦。
app.py
1 | import sqlite3 |
flask的类get_pop.py
1 | # https://movie.douban.com/cinema/nowplaying/beijing/ |
init.py
1 | # 直接写成模块吧 |
download_pic.py
1 | # 用于异步下载并保存文件 |
get_list_ywcz.py
1 | # 要闻传真的获取 |
get_title.py
1 | #获得标题,时间,点击量(主要是点击量) |
get_pages.py
1 | #获得页面的数据 |
爬虫库里的sqlite class
1 | import sqlite3 |
一个平平无奇的flask的模板,就是那个可以实时生成词云的那个 sdust_content_easy.html
1 |
|